Descargar la presentación
La descarga está en progreso. Por favor, espere

1
EL SPSS Y LAS TÉCNICAS MULTIVARIANTES AL SERVICIO DE LA INVESTIGACIÓN DE MERCADOS
Dr. D. Ángel M. Ramos Domínguez Director-Profesor del Curso Dra. Dña. Victoria I. Jiménez González Profesora del Curso

2
CONTENIDO Introducción al análisis multivariante y al SPSS
Análisis de componentes principales: posicionamiento de productos Análisis de correspondencias: mapa de posicionamiento Análisis cluster: segmentación de mercados Análisis de la Varianza paramétrico y no paramétrico Análisis discriminante: clasificación de nuevos clientes

3
BIBLIOGRAFÍA BÁSICA Análisis Multivariante Aplicado. Uriel Jiménez, E. y Aidás Manzano, J. Paraninfo Cengage Learning Técnicas de Análisis Multivariante. Jimenez, V. y Ramos, A. Fotocopiadora Campus Técnicas estadísticas con SPSS versión 12. Aplicaciones al análisis de datos. C.Pérez. Pearson-Prentice Hall Técnicas de análisis multivariantes de datos. Aplicaciones con SPSS. López, C.Pearson-Prentice-Hall. Técnicas de Análisis de datos en investigación de mercados. Luque Martínez, T. Ed Piramide Métodos multivariantes para investigación comercial. Abascal, E. y Grande, I. Ariel Economía Métodos estadíticos avanzados con SPSS. Pérez López, C. Editorial Thomson

4
1. Introducción Definición:
Técnicas estadísticas para el análisis descriptivo o inferencial de observaciones multivariantes. Objetivos: Describir Estructurar la población creando grupos o clases. Explicar las relaciones observadas entre caracteres Problemas a resolver: Dimensionalidad Información redundante Clasificación

5
TIPOS DE TÉCNICAS MULTIVARIANTES
Factoriales: Análisis de Componentes Principales. Para tablas de medidas o de escalas métricas. Análisis de Correspondencias Simple y Múltiple. Para tablas de contingencia o de frecuencias Clasificación: Análisis Cluster Análisis Discriminante

6
FUENTES DE DATOS Objetivo del estudio Información disponible:
Encuestas: Características de la población de la que se extrae la muestra Diseño muestral Presupuesto disponible

7
2. Análisis de Componentes Principales
Objetivo: Transformar un conjunto de variables en un nuevo conjunto, componentes principales, incorrelacionadas entre sí. Se consigue una representación simplificada, más sencilla y fácil de ver. Metodología: Los datos se presentan en una tabla rectangular con n líneas (individuos) y p columnas (variables) (matriz R, nxp). Puede ser disimétrica y con variables heterogéneas. Hay dos espacios: Rp : n individuos con los valores que toman para cada una de las p variables. Rn : p variables para cada individuo. Finalidad: Buscar un subespacio Rq, q<p que contenga la mayor cantidad posible de información de la nube primitiva, y que mejor se ajuste a la nube de puntos y la deforme lo menos posible. El criterio de ajuste es el de mínimos cuadrados. Se obtendrán nuevas variables, combinaciones lineales de las variables originales llamadas factores o componentes.
 y p columnas (variables) (matriz R, nxp). Puede ser disimétrica y con variables heterogéneas. Hay dos espacios: Rp : n individuos con los valores que toman para cada una de las p variables. Rn : p variables para cada individuo. Finalidad: Buscar un subespacio Rq, q<p que contenga la mayor cantidad posible de información de la nube primitiva, y que mejor se ajuste a la nube de puntos y la deforme lo menos posible. El criterio de ajuste es el de mínimos cuadrados. Se obtendrán nuevas variables, combinaciones lineales de las variables originales llamadas factores o componentes.")
8
Gráficamente: ui es el vector unitario o propio y zi es la proyección de xi en Fi. Como medida de la cantidad de información incorporada en una componente se utiliza su varianza. Cuanto mayor sea, mayor es la información incorporada a dicha componente. La primera componente será la de mayor varianza. Para obtener los factores o componentes que diferencian al máximo a los individuos entre sí, medidos a través de caracteres métricos, la extracción se realiza sobre variables tipificadas, con matriz X, para evitar problemas de escala. La suma de las varianzas es igual a p, ya que la de cada una de ellas es igual a 1 y habrá tantas componentes como número de variables originales. Mientras más correlacionadas estén las variables originales entre sí, más alta será la variabilidad que se pueda explicar con menos componentes. Si existiera incorrelación, el ACP carecería de sentido, ya que las variables originales y las componentes o nuevas variables coincidirían.

9
Cálculo de medias y desviaciones típicas
MATRIZ DE DATOS Cálculo de medias y desviaciones típicas X: MATRIZ DE DATOS TIPIFICADOS R =X´X MATRIZ DE CORRELACIONES Diagonalización de R, cálculo de valores propios, varianza explicada y correlaciones COMPONENTES PRINCIPALES

10
Resumen Las componentes principales son combinaciones lineales de las variables originales. Los coeficientes de las combinaciones lineales son los elementos de los vectores característicos asociados a la matriz de covarianzas de las variables originales. Por tanto, la obtención de componentes principales es un caso típico de cálculo de raíces y vectores característicos de una matriz simétrica. La primera componente se asocia a la mayor raíz característica a que va asociada. Si se tipifican las variables originales, su proporción de variabilidad total captada por una componente es igual a su raíz característica dividida por el número de variables originales. La correlación entre una componente y una variable original se determina con la raíz característica de la componente y el correspondiente elemento del vector característico asociado, si las variables originales están tipificadas

11
CASO: Posicionamiento de turistas en Tenerife
Objetivo: Posicionamiento del producto turístico de Tenerife según nacionalidades. Metodología: Cuestionario: Fichero base turistas curso.sav. Caso de ACP: Se han elegido noches, nº visitas, nº personas, gasto y edad Se crea una nueva variable: Gasto/persona/noche. Se obtienen las medianas por nacionalidad para las variables.

12
Datos. Medianas Tabla de datos:
Nacionalidad Nº Noches Nº visitas anteriores Gasto noche/persona Edad Sexo Alemana 14,00 ,00 76,6290 42,00 1,00 Austriaca 7,00 35,7452 33,00 Belga 46,2028 35,00 Británica 2,00 37,5633 39,00 Española 85,8589 31,00 Europa exc 41,7811 24,50 1,50 Finlandesa 32,00 50,00 46,9541 73,00 Francesa 75,1265 38,00 Holandesa 18,9410 26,00 Italiana 72,9800 28,00 R. América 29,00 19,1990 22,50 R. Europa 89,0786 34,00 R. mundo 6,00 117,9486 30,00 Sueca 123,5552 Suiza 80,3639 37,00 Total 64,3942 Nacionalidad Nº Noches Nº visitas anteriores Gasto noche/persona Edad Sexo Alemana 14,00 ,00 76,6290 42,00 1,00 Austriaca 7,00 35,7452 33,00 Belga 46,2028 35,00 Británica 2,00 37,5633 39,00 Española 85,8589 31,00 Europa exc 41,7811 24,50 1,50 Finlandesa 32,00 50,00 46,9541 73,00 Francesa 75,1265 38,00 Holandesa 18,9410 26,00 Italiana 72,9800 28,00 R. América 29,00 19,1990 22,50 R. Europa 89,0786 34,00 R. mundo 6,00 117,9486 30,00 Sueca 123,5552 Suiza 80,3639 37,00 Total 64,3942 Datos. Medianas Tabla de datos: Matriz con 15 filas, correspondientes a las nacionalidades, y 4 columnas, correspondientes a las 4 variables. Dentro, medianas

13
SPSS versión 14.0 para windows
Analizar Reducción de datos Análisis Factorial

14
Elección del numero de ejes
Criterio de la media aritmética: Se seleccionan las componentes cuya varianza (valor propio) o inercia asociada a cada componente, exceda de la media de las raíces características. Por tanto, se debe verificar que Si las variables originales están tipificadas, , por lo que la media de la inercia es igual a 1. Se retendrán los factores cuya inercia sea mayor que 1.
 o inercia asociada a cada componente, exceda de la media de las raíces características. Por tanto, se debe verificar que. Si las variables originales están tipificadas, , por lo que la media de la inercia es igual a 1. Se retendrán los factores cuya inercia sea mayor que 1.")
15
Resultados ACP 1 Estadísticos descriptivos más importantes de las variables utilizadas El perfil promedio de los turistas de la muestra tiene un estancia promedio de 11 o 12 días, han visitado con anterioridad la isla entre 3 y 4 ocasiones, el gasto persona/día de sus vacaciones ha sido de 64,53€, la edad es aproximadamente 35 años. La variable con mayor grado de dispersión relativa es el nº de visitas anteriores (357%).
.")
16
Resultados ACP 2 Matriz de coeficientes de correlación para todos los pares de variables originales. Niveles de significación unilaterales de cada uno de los coeficientes. Para un nivel del 5% de significación, resultaron significativos 4 de los 6 (67%), porcentaje de índices de correlación adecuado para el análisis.
, porcentaje de índices de correlación adecuado para el análisis.")
17
Resultados ACP 3 La adecuación de los datos al análisis factorial de componentes principales se contrasta mediante KMO y prueba de Bartlett

18
Resultados ACP 4 KMO: Estadístico de prueba de la hipótesis de que las correlaciones parciales entre las variables son pequeñas. Indica la proporción de varianza de las variables originales que es común, y que podría ser explicada por factores subyacentes. Valores cercanos a 1: un análisis factorial puede ser útil para los datos. Valores menores de 0,5: los resultados probablemente no sean muy útiles. KMO = 0,6: Los datos muestran ser adecuados para el análisis ACP. rij : coeficiente de correlación lineal de Pearson entre las variables i,j aij: coeficiente de correlación parcial entre las variables i,j Prueba de esferidad de Bartlett: Indica si la matriz de correlaciones es una matriz identidad, por lo que que las variables no están relacionadas Hay evidencia suficiente para rechazar que la matriz de correlaciones es una matriz identidad. Existe un cierto nivel de relación entre las variables.

19
Resultados ACP 5 Covarianzas y correlaciones parciales negativas. Índice de las correlaciones no debidas a los factores. Valores pequeños: las variables están relativamente libres de correlaciones no explicadas. La mayoría de los valores fuera de la diagonal principal deberían ser muy pequeños (próximos a cero). En nuestro caso, parece existir una parte importante de las correlaciones entre las variables que los factores extraídos no consiguen explicar. Elementos de la diagonal principal de la matriz de correlación anti-imagen: medida de adecuación muestral para cada variable. Valores inferiores a 0,5: Las variables no se ajustan a la estructura de las otras. Deberíamos eliminarlas del análisis. En nuestro caso todas las variables presentan una medida de adecuación muestral superior a 0,5.
. En nuestro caso, parece existir una parte importante de las correlaciones entre las variables que los factores extraídos no consiguen explicar. Elementos de la diagonal principal de la matriz de correlación anti-imagen: medida de adecuación muestral para cada variable. Valores inferiores a 0,5: Las variables no se ajustan a la estructura de las otras. Deberíamos eliminarlas del análisis. En nuestro caso todas las variables presentan una medida de adecuación muestral superior a 0,5.")
20
Resultados ACP 6 Indican la cantidad de varianza de cada variable que es explicada. En el método de extracción Componentes Principales, las comunalidades iniciales son siempre 1. Las comunalidades de la extracción son estimaciones de la varianza de cada variable que es explicada por los factores incluidos en la solución factorial. Para todas las variables la cantidad de varianza explicada por los factores de la solución factorial es alta. Todas las variables se ajustan bien a la solución factorial.

21
Resultados ACP 7 Las tres primeras columnas se refieren a la solución inicial, y hay tantos valores como componentes o factores posibles. Total: Cantidad de varianza explicada por cada componente en las variables observadas. “% de varianza”: Porcentaje de varianza explicada por las componentes. “% de varianza acumulado”: Porcentaje acumulado de varianza explicada por la componente correspondiente y las anteriores. En nuestro caso los dos primeros factores consiguen explicar prácticamente el 91% de la varianza de las variables originales, lo que indica un buen modelo factorial. También se muestran las cantidades de varianza explicada por cada factor extraído una vez realizada la rotación de los mismos. En ese caso, el factor 1 explica más del 56% de la varianza, mientras que el segundo factor explica el 34.63%.

22
Resultados ACP 8 Matriz de casos
Nacionalidad F1 F2 Alemana 0,142 0,380 Austriaca -0,201 -0,666 Belga -0,167 -0,331 Británica 0,309 -0,619 Española -0,505 0,466 Europa excomunista -0,471 -0,805 Finlandesa 3,374 0,988 Francesa -0,254 0,443 Holandesa -0,026 -1,534 Italiana -0,526 0,058 Resto América 0,524 -2,126 Resto Europa -0,436 0,643 Resto mundo -0,734 1,234 Sueca -0,720 1,335 Suiza -0,308 0,535 Cargas factoriales para cada variable sobre las componentes no rotadas. Cada valor representa la correlación entre la variable y la componente. Pueden ayudar a formular una interpretación de los factores. La mayoría de las variables originales presentan una correlación alta con el primero de los factores, lo que dificulta la interpretación de los mismos.

23
Resultados ACP 9 Correlaciones reproducidas y residuos
Patrón predictivo de las relaciones. Si la solución es correcta, las correlaciones reproducidas están próximas a los valores observados, Los residuos indican la diferencia entre valores reproducidos y observados. La mayoría de estos valores deberán ser pequeños. a. Hay 3 (50,0%) residuales no redundantes con valores absolutos mayores que 0,05. Los valores residuales son pequeños. La bondad del modelo factorial estimado es bastante alta
 residuales no redundantes con valores absolutos mayores que 0,05. Los valores residuales son pequeños. La bondad del modelo factorial estimado es bastante alta.")
24
Resultados ACP 10 Valores utilizados para el cálculo de las puntuaciones para cada caso. Para cada nacionalidad, la puntuación factorial se calcula multiplicado los valores de la variable por los coeficientes de la puntuación factorial.

25
Gráfico ACP: Diagrama de dispersión

26
Rotación de los ejes: Procedimientos
Objetivo: Obtener nuevos factores más fáciles de interpretar. Cada variable original tendrá una correlación lo más próxima a 1 con uno de los factores y lo más próximas a 0 con el resto. Cada factor tendrá correlación alta con un grupo de variables y baja con el resto. 1. Rotación ortogonal: Queda preservada la incorrelación entre los factores. VARIMAX. Los ejes de los factores rotados se obtienen maximizando la suma de varianzas de las cargas factoriales al cuadrado dentro de cada factor. Problema: Las variables con mayores comunalidades tienen mayor influencia en la solución final. Para evitarlo: normalización de Kaiser: Cada carga factorial al cuadrado se divide por la comunalidad de la variable correspondiente (VARIMAX normalizado). Ventaja: queda inalterada tanto la varianza total explicada por los factores como la comunalidad de cada una de las variables EQUAMAX y el QUARTIMAX 2. Rotación oblicua: Factores no incorrelacionados. Se compensarse si se consigue una asociación más nítida de cada variable con el factor correspondiente. OBLIMIN: Se utilizan algoritmos para controlar el grado de no ortogonalidad. Tampoco se ve modificada la comunalidad en la rotación oblicua
. Ventaja: queda inalterada tanto la varianza total explicada por los factores como la comunalidad de cada una de las variables. EQUAMAX y el QUARTIMAX. 2. Rotación oblicua: Factores no incorrelacionados. Se compensarse si se consigue una asociación más nítida de cada variable con el factor correspondiente. OBLIMIN: Se utilizan algoritmos para controlar el grado de no ortogonalidad. Tampoco se ve modificada la comunalidad en la rotación oblicua.")
27
Resultados Rotación VARIMAX 1
Las cargas factoriales quedan más repartidas Para la componente 1 las variables con mayores cargas factoriales son: “nº de visitas anteriores” (+), “edad del turista” (+) y “nº de noches” (+), aunque ésta última, también presenta una alta carga factorial con la componente 2. Con la componente 2 además de el “nº de noches” (-), se da una alta correlación con : “gasto por persona y día” (+). Explicación: Componente 1: Los turistas de más edad son los que más veces han repetido visita a Tenerife, y los que más alargan su estancia durante sus vacaciones. Componente 2: Los que más gastan por persona y día son los que menor tiempo de estancia tienen.
, edad del turista (+) y nº de noches (+), aunque ésta última, también presenta una alta carga factorial con la componente 2. Con la componente 2 además de el nº de noches (-), se da una alta correlación con : gasto por persona y día (+). Explicación: Componente 1: Los turistas de más edad son los que más veces han repetido visita a Tenerife, y los que más alargan su estancia durante sus vacaciones. Componente 2: Los que más gastan por persona y día son los que menor tiempo de estancia tienen.")
28
MATRIZ DE CASOS ROTADOS
Resultados Rotación VARIMAX 2 MATRIZ DE CASOS ROTADOS Nacionalidad F1 F2 Alemana 0,293 0,280 Austriaca -0,471 -0,512 Belga -0,294 -0,226 Británica 0,008 -0,692 Española -0,252 0,640 Europa excomunista -0,775 -0,520 Finlandesa 3,467 -0,580 Francesa -0,036 0,510 Holandesa -0,691 -1,370 Italiana -0,449 0,281 Resto América -0,454 -2,142 Resto Europa -0,112 0,769 Resto mundo -0,123 1,430 Sueca -0,067 1,515 Suiza -0,044 0,616 Factor 1: Cuadrante positivo: Nacionalidades: Finlandesa, Alemana y Británica. Nº visitas anteriores, edad, nº noches Cuadrante negativo: Nacionalidades: Resto Factor 2: Nacionalidades: Alemana, Española, Francesa, Italiana, Resto de Europa, Resto del Mundo, Sueca y Suirza. Gasto noche persona Nacionalidades: Resto. Nº noches

29
Gráfico ACP rotado: Diagrama de dispersión

30
Caso a resolver: Imagen de fabricantes de modas para penetración en un mercado extranjero
La marca de ropas St. John no es muy conocida en Europa. Procede de EEUU. Allí es adquirida por mujeres de nivel socioeconómico alto. St. John fabrica primordialmente trajes de chaqueta, empleando fibras naturales que mezcla con una pequeña parte de un polímero sintético que impide que la ropa se arrugue. Muchas mujeres compran ropa de este fabricante, especialmente si realizan un trabajo en el que la imagen sea importante, pues los trajes presentan un aspecto impecable después de muchas horas de llevarlos puestos. Se puede llegar al final de la jornada casi sin que sea necesario tener que plancharlos. En 1991 se realizó un estudio sobre el posicionamiento de marcas de fabricantes de ropa (Dishener y Grande, 1991) para detectar cómo era percibida esta marca y encontrar el segmento en el que podría ser incluida y decidir sobre la oportunidad de penetrar en el mercado español. Fase cualitativa: Como la marca no era conocida en España, no tenía mucho sentido obtener información en el mercado. Se optó por consultar con expertos del mundo de la moda para que posicionaran las marcas. Tras una serie de entrevistas con directores de escuelas de diseño de moda se consideraron las variables más importantes para juzgar una serie de marcas. En un principio se pensó que, debido al perfil socioeconómico de las compradoras de St. John en EEUU, el segmento dentro del cual podría penetrar la marca podría ser el de Loewe o Chanel.
 para detectar cómo era percibida esta marca y encontrar el segmento en el que podría ser incluida y decidir sobre la oportunidad de penetrar en el mercado español. Fase cualitativa: Como la marca no era conocida en España, no tenía mucho sentido obtener información en el mercado. Se optó por consultar con expertos del mundo de la moda para que posicionaran las marcas. Tras una serie de entrevistas con directores de escuelas de diseño de moda se consideraron las variables más importantes para juzgar una serie de marcas. En un principio se pensó que, debido al perfil socioeconómico de las compradoras de St. John en EEUU, el segmento dentro del cual podría penetrar la marca podría ser el de Loewe o Chanel.")
31
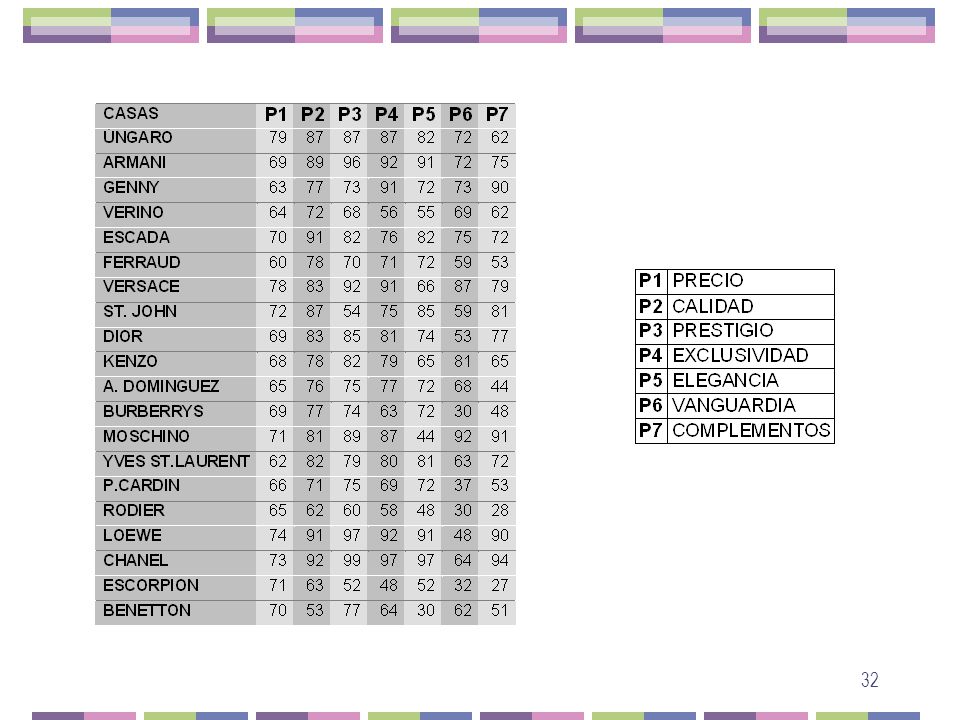
Objetivo del estudio: Averiguar en qué medida se situaba cada una de las marcas respecto a una marca media. Se intenta obtener las valoraciones de cada marca; no sólo estudiar qué aspectos destacan en su imagen, sino si se encuentran por debajo o por encima de la media. Metodología: Se consideró que la técnica más adecuada para este caso era el Análisis de Componentes Principales, que trabaja con datos métricos. Se diseñó un cuestionario en el que debían valorarse de 0 a 100 las características citadas para cada una de las marcas. La valoración que debía darse era en términos positivos: cuanto más cara fuera la marca, mayor su calidad, prestigio, exclusividad, etc., mayor tenía que ser la puntuación asignada. La aparente dificultad de las valoraciones - obliga a pensar y fatiga - quedó mitigada por el reducido número de atributos a valorar y la gran cualificación de los encuestados, todos ellos expertos en moda. Muestra: El cuestionario se distribuyó a 256 directores de centros de diseño de moda, 30 distribuidores y 10 importadores. La información se recogió a lo largo de mayo y junio de Los valores medios de cada marca en cada atributo son los siguientes:

33
3. Análisis de Correspondencias Simples
Estudio de tablas de contingencia, para juzgar objetos según un cierto número de criterios. Matriz de datos de orden (n*p):Tabla de doble entrada. Filas: n modalidades de la variable A. Columnas: p modalidades de la variable B. Intersección kij: frecuencia conjunta entre las modalidades i y j. Método: Simétrico con relación a líneas y columnas. Deberá permitir comparar las distribuciones de frecuencias.
:Tabla de doble entrada. Filas: n modalidades de la variable A. Columnas: p modalidades de la variable B. Intersección kij: frecuencia conjunta entre las modalidades i y j. Método: Simétrico con relación a líneas y columnas. Deberá permitir comparar las distribuciones de frecuencias.")
34
Caso: Lugar de residencia de turistas y su edad
Estudio sobre la posible asociación entre la zona o lugar de residencia de los turistas en Tenerife y su edad agrupada en intervalos Datos: base turistas curso.sav. Información sobre 796 turistas a los que se ha realizado la encuesta. Se han elegido la edad en intervalos y lugar de residencia de los turistas en Tenerife. Se elaboró una tabla de contingencia. Como algunos pares de modalidades se repetían un número muy pequeño de veces, se agruparon: Los ocho intervalos de edad de la base de datos se redujeron a seis: * < de 24 anos * a 30 años * a 40 años * a 50 años * a 60 años * > 60 años El lugar de residencia se reduce a tres modalidades: * Puerto de la Cruz * Las Américas-Los Cristianos * Resto

35
Metodología: Análisis de correspondencias simple
Objetivo: Conocer el lugar de residencia de los turistas que se asocia con un intervalo de edad en mayor proporción que los demás. Detectar las características que más destacan en cada intervalo de edad y en cada lugar de residencia de los turistas. Reducir nº de caracteres relacionados a dimensiones independientes. Método: Obtener ejes factoriales que reducen la información original mediante nuevas variables estudiando la asociación entre modalidades fila y columna. Se parte de frecuencias relativas para comparar. En el espacio de las columnas: nube de n puntos i con coordenadas kij/ki. para j = 1, 2, .....p En el espacio de las filas: nube de p puntos j con coordenadas kij/k.j para i = 1, 2, n

36
Transformaciones en la matriz de datos
Iguales en ambos subespacios, llevando a transformaciones analíticas diferentes. p y n puntos de las nubes, situados en subespacios de p-1 y n-1 dimensiones. Centro de gravedad: media de perfiles de frecuencias afectados por sus masas

37
Tabla de contingencia Intervalo de edad: Los turistas de < 24 años se alojaron mayoritariamente en Las Américas-Los Cristianos. El menor número de turistas tienen una edad > 60 años y que se alojaron en el Resto de Lugares. La edad más frecuente es [30-40). Lugar de Residencia: Las Américas-los Cristianos alojan los 95 turistas de menos de 24 años, que representan la mayor frecuencia conjunta de la muestra. Los 11 turistas alojados en el Resto de Lugares tienen una edad >60 años los que representan el grupo de menor frecuencia conjunta. En cuanto a la frecuencia marginal, Las Américas-Los Cristianos es la zona más frecuente de residencia.
. Lugar de Residencia: Las Américas-los Cristianos alojan los 95 turistas de menos de 24 años, que representan la mayor frecuencia conjunta de la muestra. Los 11 turistas alojados en el Resto de Lugares tienen una edad >60 años los que representan el grupo de menor frecuencia conjunta. En cuanto a la frecuencia marginal, Las Américas-Los Cristianos es la zona más frecuente de residencia.")
38
SPSS: Introducir los datos
Poner en las dos primeras columnas los pares de rangos posibles para las columnas (Lugar de residencia: 1 a 3) y las filas (Intervalos de edad: 1 a 6) y, en la tercera, la frecuencia de cada par de rangos. Se puede poner etiquetas al valor de cada rango. Utilizar como variable de ponderación las frecuencias mediante los comandos del menú: Datos, Ponderar casos
 y las filas (Intervalos de edad: 1 a 6) y, en la tercera, la frecuencia de cada par de rangos. Se puede poner etiquetas al valor de cada rango. Utilizar como variable de ponderación las frecuencias mediante los comandos del menú: Datos, Ponderar casos.")
39
Distancia Chi-cuadrado
Propiedades: Equivalencia distribucional Permite agregar dos modalidades de idénticas frecuencias de una variable, en una nueva modalidad afectada por la suma de sus masas, sin cambiar nada, ni en las distancias entre modalidades de esta variable o de la otra. Relaciones de transición Ligan gráficamente las dos variables representadas en líneas y columnas.

40
Obtención de los ejes factoriales
Analizar Reducción de datos Análisis de correspondencias Dos transformaciones: en el perfil de líneas y de las columnas. Se toma como columnas la dimensión más pequeña. Maximizar la suma ponderada de los cuadrados de las proyecciones sobre el eje: Matriz a diagonalizar Descartado el valor propio trivial igual a 1 y su vector propio asociado, retenemos los p-1 valores propios no nulos y sus vectores propios asociados. Obtendremos como máximo p-1 ejes factoriales.

41
Normalización Canónica: Para examinar conjuntamente las diferencias o similitudes entre dos variables. Principal: Examinar las diferencias o similitudes entre categorías de variables, pero por separado. Principal por filas: Averiguar cómo difieren entre sí las distintas categorías de la variable fila. Principal por columnas: Averiguar cómo difieren entre sí las distintas categorías de la variable columna. Las soluciones son equivalentes en términos de ajuste (valores singulares), inercia y contribuciones, pero las puntuaciones por filas y columnas son diferentes.
, inercia y contribuciones, pero las puntuaciones por filas y columnas son diferentes.")
42
Estadísticos Dependiendo de la opción elegida en la normalización se podrá demandar el gráfico conjunto o no. Si se ha elegido la normalización canónica: Gráfico conjunto. Si se ha elegido la principal: Gráficos por separado de filas y columnas.

43
Análisis Valores propios. Inercia total
Coordenadas: Proyecciones de los puntos filas en los ejes factoriales Contribuciones a la inercia de puntos a varianza explicada en cada eje Correlaciones: Contribución de dimensiones a la inercia de cada punto

44
Interpretación de representación simultánea
Filas (columnas) con estructura similar, situación próxima en el plano. Cercanía punto fila i y columna j: interpretar si están alejados del origen. Línea con perfil próximo al medio, se encontrará próxima al origen. Buscar los puntos de mayor Contribución absoluta de las inercias. Se separa los que se proyectan del lado positivo de los del lado negativo. Estudiar la calidad de representación (correlación) de los puntos. Correlación pequeña: tiene un papel importante sobre otro eje. Se buscan aquellos puntos i(j) que si bien no contribuyen a la formación del factor, sí se encuentran bien representados (correlación alta).
 con estructura similar, situación próxima en el plano. Cercanía punto fila i y columna j: interpretar si están alejados del origen. Línea con perfil próximo al medio, se encontrará próxima al origen. Buscar los puntos de mayor Contribución absoluta de las inercias. Se separa los que se proyectan del lado positivo de los del lado negativo. Estudiar la calidad de representación (correlación) de los puntos. Correlación pequeña: tiene un papel importante sobre otro eje. Se buscan aquellos puntos i(j) que si bien no contribuyen a la formación del factor, sí se encuentran bien representados (correlación alta).")
45
Resultados AC 1 Perfil fila
Proporción de modalidades de la variable fila en cada modalidad de la variable columna. Proporción de edades en cada zona. El 66% de los turistas de < 24 años se alojaron en Las Américas-Los Cristianos, mayoritaria en cada estrato de edad, con un 51,6% de turistas de la muestra alojados en ella.

46
Resultados AC 2 Perfil columna
De 30 a 40 años es la edad más frecuente (23%), repitiéndose esta situación entre los turistas alojados en el Puerto de la Cruz (23.8%) y los alojados en el Resto de Lugares (29%). Sin embargo, entre los turistas alojados en Las Américas-Los Cristianos, el intervalo de edad modal es los jóvenes de menos de 24 años (23.1%).
, repitiéndose esta situación entre los turistas alojados en el Puerto de la Cruz (23.8%) y los alojados en el Resto de Lugares (29%). Sin embargo, entre los turistas alojados en Las Américas-Los Cristianos, el intervalo de edad modal es los jóvenes de menos de 24 años (23.1%).")
47
Resultados AC 3 Valor propio o singular: medida de asociación para cada una de las dimensiones entre las variables fila y columna, donde valores altos indican la existencia de una fuerte relación Inercia: Cuadrado del valor propio. Varianza explicada Inercia global Chi cuadrado: Prueba de independencia. 2 = 796*0,041 = 32,953. Se rechaza la hipótesis de independencia entre las modalidades.

48
ANÁLISIS Analisis en Rp: Examen de los puntos fila
COORDENADAS :Puntos fila Proyecciones de los puntos filas en los ejes factoriales. Mientras más alejados del origen sean los valores, mejor representadas estarán las filas en cada uno de los ejes. CONTRIBUCIÓN A LA INERCIA O ABSOLUTAS: Las de cada uno de los puntos filas a la inercia explicada en cada eje. Se busca conocer los elementos responsables de la construcción de cada eje. CORRELACIÓN O CONTRIBUCIÓN RELATIVA: La contribución de las dimensiones a la inercia de cada punto fila es la correlación existente entre cada uno de los caracteres y los nuevos ejes. Coseno del ángulo entre el eje y el vector uniendo el centro de gravedad de la nube al punto i. Analisis en Rp: Examen de los puntos columna. Igual

49
Resultados AC 3 Analisis en Rp: Examen de los puntos fila

50
Resultados AC 4 Analisis en Rn: Examen de los puntos columna

51
GRÁFICO

52
Interpretación de resultados
Eje 1 Puntuación: Lado positivo: < 24 años, años, > 60 años. Américas-Cristianos. Lado negativo: 31 a 40 años, 41 a 50 y 51 a 60. Resto de Lugares y Puerto de la Cruz muy ligeramente. Contribución a la inercia: < 24 años, y años. Américas-Cristianos y Resto de Lugares. Correlaciones: Todas las edades. Américas-Cristianos y Resto de Lugares. Eje 2 Puntuación: Lado positivo: > de 60 años, 25 a 30 y 31 a 40 años. Puerto de la Cruz. Lado negativo: < 24 años, y años. Américas-Cristianos y Resto de Lugares. Contribución de puntos a la inercia de la dimensión: años y < 24 años. Puerto de la Cruz. Contribución de la dimensión a la inercia del punto: años. Puerto de la Cruz.

53
CONCLUSIONES Existe asociación entre las dos variables, por lo que será posible el hacer corresponder las modalidades de una con las de la otra. Los turistas con una edad mayor de los 60 años se alojan preferentemente en la zona del Puerto de la Cruz, mientras que los menores de 30 años lo hacen en Las Américas-Los Cristianos. Los turistas con una edad entre los 30 y 50 años tienen una tendencia a alojarse en el grupo de zonas etiquetadas con el nombre de Resto de Lugares.

54
Caso a resolver: Forma jurídica de las empresas exportadoras canarias y su propensión a exportar
Se quiere realizar un estudio sobre la relación existente entre las distintas formas jurídicas de las empresas exportadoras canarias y su propensión a exportar, definida ésta como el cociente entre el volumen de exportaciones y el volumen de negocios de cada una de ellas. Los datos con los que se cuenta provienen de una Base de Datos elaborada por la empresa CAMERDATA en 1990 que contiene información sobre empresas exportadoras españolas, de las cuales 693 pertenecen a la Comunidad Autónoma de Canarias. Una vez depurada la Base de Datos, el número de empresas exportadoras canarias se redujo a 394 realizándose transformaciones sobre las variables con las que cuenta la Base de Datos

55
Las siete formas jurídicas de las empresas, se redujeron a cuatro mediante la agregación de algunas de ellas. Así, las formas jurídicas resultantes fueron: Sociedades Anónimas Sociedades Limitadas Autónomos Otros A partir del volumen de exportación y volumen de negocios se obtuvo la propensión a exportar de cada empresa de la Base de datos depurada. Hecho esto, se agregaron los resultados. Así, la propensión a exportar presentara tres modalidades: Propensión a exportar baja: 0 a 10%. Propensión a exportar media:10 a 50% . Propensión a exportar alta: 50 a 100%.

56
4. Análisis de Correspondencias Múltiples
Generalización del ACS. Permite describir grandes tablas binarias, referidas por ejemplo a ficheros de encuestas socio-económicas. Líneas: individuos u observaciones. Columnas: Modalidades de variables nominales. El ACM es un Análisis de Correspondencias Simple aplicado, no a tablas de contingencia sino a una tabla disyuntiva completa Z, en la que para cada modalidad de cada variable hay sólo dos valores posibles: 0 = el encuestado no contesta esa modalidad. 1= es la respuesta elegida por él. Las propiedades de Z son interesantes y los procedimientos de cálculo y sus reglas de interpretación de las representaciones obtenidas son simples y específicas. La mayoría de los ficheros de encuestas presentan las respuestas a las preguntas bajo la forma de una tabla disyuntiva completa.

57
La tabla disyuntiva completa
La forma de la matriz Z (Tabla disyuntiva completa) será: Las frecuencias marginales de las líneas de la tabla disyuntiva completa son iguales al número de preguntas, s, y las frecuencias marginales de las columnas corresponden al número de sujetos que han elegido la modalidad j de la pregunta q, por lo que para cada subtabla, el número total de individuos es n. En consecuencia, si para n individuos se dispone de respuestas respecto a, por ejemplo, dos variables nominales que tienen respectivamente p1 y p2 modalidades, entonces es equivalente someter a un Análisis de Correspondencias Simples la tabla de contingencia (p1, p2) y analizar la tabla binaria de n líneas y (p1 + p2) columnas que describe las respuestas. p Si hay alguna variable continua, debe transformarse en nominal, ordenándose en intervalos a los que se da un rango de valores.
 será: Las frecuencias marginales de las líneas de la tabla disyuntiva completa son iguales al número de preguntas, s, y las frecuencias marginales de las columnas corresponden al número de sujetos que han elegido la modalidad j de la pregunta q, por lo que para cada subtabla, el número total de individuos es n. En consecuencia, si para n individuos se dispone de respuestas respecto a, por ejemplo, dos variables nominales que tienen respectivamente p1 y p2 modalidades, entonces es equivalente someter a un Análisis de Correspondencias Simples la tabla de contingencia (p1, p2) y analizar la tabla binaria de n líneas y (p1 + p2) columnas que describe las respuestas. p. Si hay alguna variable continua, debe transformarse en nominal, ordenándose en intervalos a los que se da un rango de valores.")
58
La tabla de Burt A partir de la tabla disyuntiva completa se puede construir la tabla de contingencia de Burt, B, que es una tabla simétrica de orden (p, p): B = Z´Z B es una yuxtaposición de tablas de contingencia y está formada de s2 bloques de la forma: B = Z´Z = Cada bloque es una submatriz formada por tablas de contingencia de las variables dos a dos, salvo los bloques que se están en la diagonal que son las tablas de contingencia de cada variable consigo misma. p1 p ps p1 p2 ps p p
: B = Z´Z. B es una yuxtaposición de tablas de contingencia y está formada de s2 bloques de la forma: B = Z´Z = Cada bloque es una submatriz formada por tablas de contingencia de las variables dos a dos, salvo los bloques que se están en la diagonal que son las tablas de contingencia de cada variable consigo misma. p1 p2 ps. p1. p2. ps. p. p.")
59
Principios del análisis de correspondencias múltiples
Es el análisis de correspondencias de una tabla disyuntiva completa, estudiándose la nube de los individuos y la nube de las modalidades. Sus principios son, por tanto, los del análisis de correspondencias: Iguales transformaciones de la tabla en los perfiles líneas y columnas Igual criterio de ajuste con ponderación de los puntos por sus frecuencias marginales Igual distancia, la chi-cuadrado Presenta propiedades particulares debido a la naturaleza misma de la tabla disyuntiva completa. La Tabla disyuntiva completa es equivalente a la tabla de Burt y ambos producen los mismos factores

60
Caso: Estudio de los turistas en función del lugar de residencia, sexo y alojamiento
A partir de la base de datos referida a los turistas que vienen a Tenerife, se quiere estudiar la asociación existente entre el lugar donde residen en la isla, el sexo y el tipo de alojamiento en el que se quedan, con sus respectivas modalidades.

61
Con estas tres variables se ha construido la tabla de Burt.
A partir de ella se ha creado una hoja de cálculo en spss (corres multiple turismo.sav).
.")
62
Resultados Utilizaremos una tabla de Burt.
Con ella se podrán obtener las puntuaciones (distancias al centro de gravedad), contribuciones absolutas de cada modalidad y variable a los ejes o factores obtenidos (contribución de cada modalidad o variable a la inercia de los nuevos ejes) y contribuciones relativas o correlaciones de cada modalidad con los nuevos ejes. El número de ejes considerado fue de 2. Como en la Tabla de Burt las filas y las columnas representan las mismas modalidades, el estudio de ambas ofrece iguales resultados, por lo que sólo presentaremos los de las filas. Para la resolución en el SPSS, en primer lugar hay que introducir los datos de la misma forma que en el análisis de correspondencias simples, creando por tanto tres variables. Las dos primeras corresponden a los rangos de todas las modalidades y, en la tercera, se incluirán las frecuencias conjuntas de los pares de modalidades, las cuales funcionarán como ponderaciones.
, contribuciones absolutas de cada modalidad y variable a los ejes o factores obtenidos (contribución de cada modalidad o variable a la inercia de los nuevos ejes) y contribuciones relativas o correlaciones de cada modalidad con los nuevos ejes. El número de ejes considerado fue de 2. Como en la Tabla de Burt las filas y las columnas representan las mismas modalidades, el estudio de ambas ofrece iguales resultados, por lo que sólo presentaremos los de las filas. Para la resolución en el SPSS, en primer lugar hay que introducir los datos de la misma forma que en el análisis de correspondencias simples, creando por tanto tres variables. Las dos primeras corresponden a los rangos de todas las modalidades y, en la tercera, se incluirán las frecuencias conjuntas de los pares de modalidades, las cuales funcionarán como ponderaciones.")
63
Los valores singulares, inercia, porcentajes de varianza explicada y sus acumulados fueron:
Los valores singulares son los valores propios que se obtendrían si hubiéramos partido de una tabla disyuntiva completa, cuyo cuadrado es igual a la Inercia o valores propios resultantes de la matriz de Burt. En el Análisis de Correspondencias Múltiples, los porcentajes de varianza explicada suelen ser pequeños para cada eje y no se pueden explicar de igual forma que en el análisis de correspondencias simples.

64
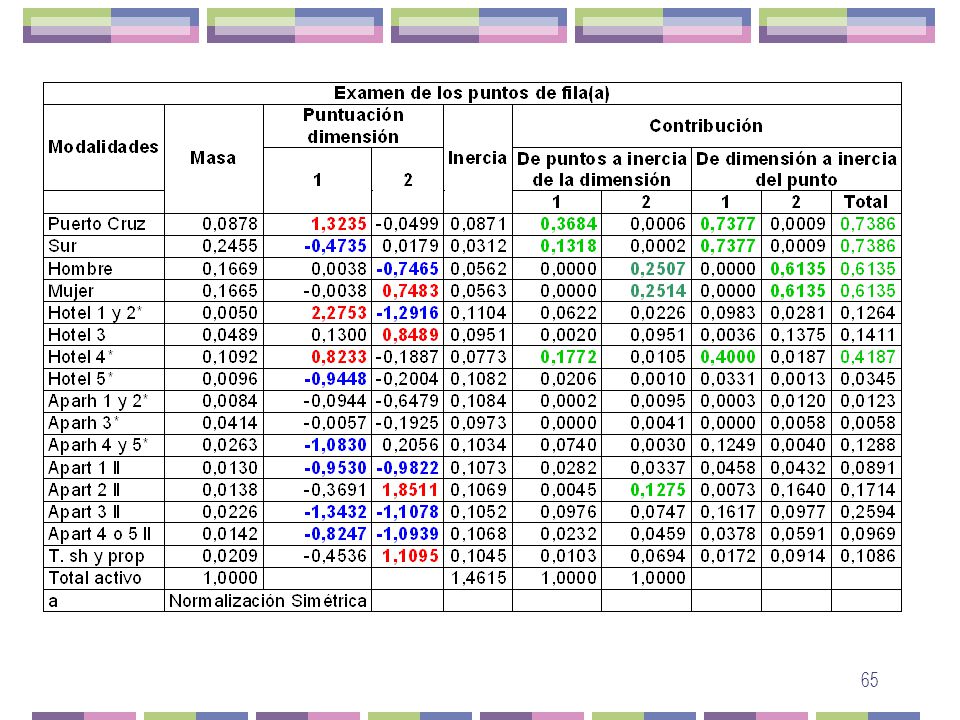
Examen de los puntos Las distancias de las modalidades, mientras más alejadas se encuentren del origen, mejor representados estarán. Mientras más alejadas estén las modalidades entre sí en el gráfico menos asociación existirá entre ellas y cuanto más cercanas, más asociación existirá entre ellas. La contribución de los puntos a la inercia de cada dimensión o contribución de cada una de las filas a la inercia o varianza explicada en cada uno de los ejes considerados La contribución de las dimensiones a la inercia de cada punto. Se refiere a la correlación existente entre cada uno de los caracteres y los nuevos ejes. A continuación se presentan los resultados y el diagrama de dispersión de los dos ejes obtenidos.

67
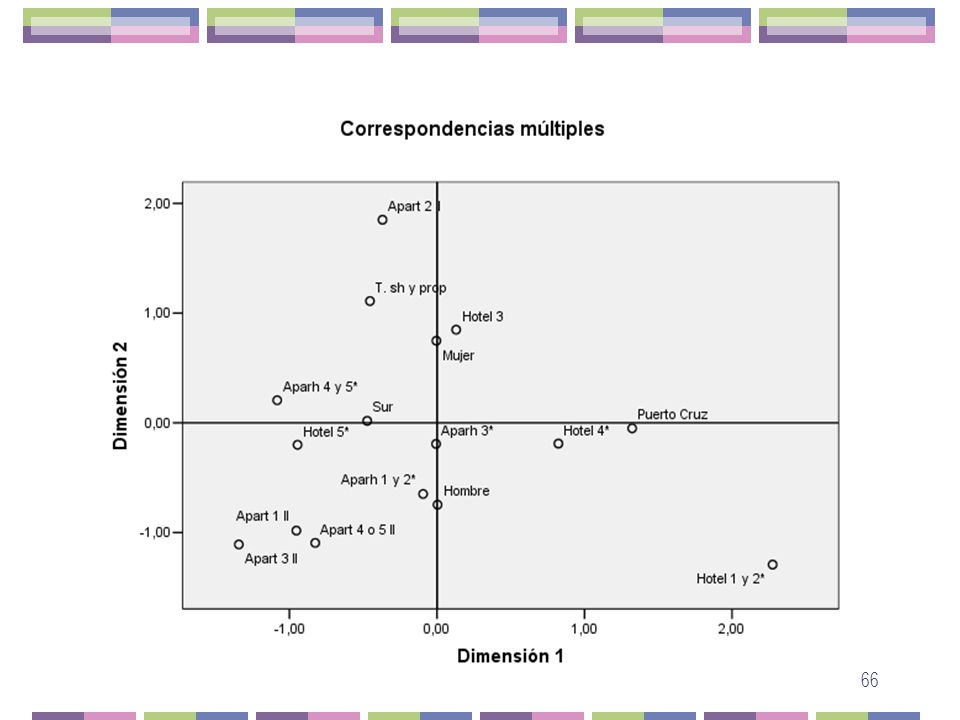
Eje 1: Se contraponen los turistas que se quedan en el Puerto de la Cruz y que destacan por alojarse en hoteles de 1, 2 y 4*, todos ellos en el lado positivo, a los turistas que van al Sur y que se alojan en hoteles de 5*, aparthoteles de 4 y 5* y apartamentos de 1, 3, 4 y 5 llaves, todos ellos en el lado negativo. Las variables con mayor contribución absoluta a la inercia del eje 1 son Puerto de la Cruz, Sur y Hoteles de 4*. Las variables más correlacionadas con el eje 1 son Puerto Cruz, Sur y Hoteles de 4*. Eje 2: Sobresalen en el lado positivo los turistas mujeres, que se alojan en hoteles de 3*, apartamentos de dos llaves y Time sharing y propiedad, contraponiéndose a los turistas hombres que se alojan en hoteles de 1 y 2*, apartamentos de 1, 3, 4 y 5 llaves, todas ellas en el lado negativo. Las variables con mayor contribución absoluta a la inercia del eje 2 son: Hombres, mujeres y apartamentos de 2 llaves. Las variables más correlacionadas con el eje 2 son hombre y mujer. Por tanto, podemos decir que el eje 1 viene afectado por la variable lugar de residencia, mientras que en el eje 2 influye la variable sexo.

68
CONCLUSIONES En cuanto al lugar de residencia y al sexo de los turistas, éstos residen en el Puerto de La Cruz y en el Sur, independientemente del sexo. Las diferencias se encuentran en el tipo de alojamiento que utilizan. Así, en el Puerto de la Cruz se caracterizan los que se quedan en hoteles de 4*, frente al Sur, que se caracterizan por alojarse en aparthoteles de 4 y 5* y en hoteles de 5*.En cuanto al tipo de alojamiento por sexo, las mujeres se caracterizan por preferir especialmente los apartamentos de 2 llaves y el Time sharing y propiedad, frente a los hombres, que prefieren especialmente los apartamentos de 1, 3, 4 y 5 llaves. Nos referimos a que en esos tipos de alojamientos se diferencian hombres y mujeres o Puerto de la Cruz y Sur.

69
Caso a resolver: Estudio de la conducta del consumidor en Centros Comerciales en Tenerife
Se realizaron encuestas en los Municipios de Santa Cruz de Tenerife, Puerto de la Cruz y Adeje en la isla de Tenerife para estudiar el comportamiento de los consumidores en Centros Comerciales de la isla de Tenerife. El tamaño de la muestra fue de 456 elementos. (datos acm consumidores.sav) El objetivo es analizar el comportamiento de los consumidores en los Centros Comerciales de Tenerife estudiando la asociación existente entre una serie de variables y entre sus respectivas modalidades. Se partió de las preguntas sobre la edad, el sexo, los estudios, los ingresos y el gasto, al ser consideradas como básicas. A ellas se añadieron las que tenían un alto grado de asociación con aquellas, como son tipo de transporte al centro comercial, lugar de residencia, frecuencia de las visitas o compras y razón de la visita. La técnica adecuada será el Análisis de Correspondencias Multiples
 El objetivo es analizar el comportamiento de los consumidores en los Centros Comerciales de Tenerife estudiando la asociación existente entre una serie de variables y entre sus respectivas modalidades. Se partió de las preguntas sobre la edad, el sexo, los estudios, los ingresos y el gasto, al ser consideradas como básicas. A ellas se añadieron las que tenían un alto grado de asociación con aquellas, como son tipo de transporte al centro comercial, lugar de residencia, frecuencia de las visitas o compras y razón de la visita. La técnica adecuada será el Análisis de Correspondencias Multiples.")
70
5. Análisis Cluster Etapas:
Conjunto de técnicas multivariantes de clasificación que ante un conjunto de datos derivados de una muestra de entidades, tratan de reorganizarlas en clases, tipos o grupos, internamente los más homogéneos posible y heterogéneos entre sí. Etapas: Elección de las entidades (objetos, variables, individuos, etc..) que se van a clasificar. Elección de las características que permiten la definición de las entidades y sobre las que se basará la clasificación final. Elección de una medida que defina la proximidad entre entidades. Selección de un método de clasificación. Interpretación de los grupos resultantes.
 que se van a clasificar. Elección de las características que permiten la definición de las entidades y sobre las que se basará la clasificación final. Elección de una medida que defina la proximidad entre entidades. Selección de un método de clasificación. Interpretación de los grupos resultantes.")
71
Método Objetivo: condiciona en buena medida los criterios empleados en la agrupación, por lo que no existe una metodología cluster única. Describiremos aquí la clasificación jerárquica que es la más utilizada. Puede aplicarse a variables cuantitativas o cualitativas. Procedimiento de agrupamiento: Formar los conglomerados en distintas etapas. Representación gráfica: Dendograma. Medida de homogeneidad entre dos elementos, viene dada por la distancia entre ellos. Hemos utilizado la distancia euclídea, ya que trabajaremos con valores y no con frecuencias:

72
MATRIZ DE CASOS ROTADOS
Caso: Resultados de la rotación varimax en el ACP para el posicionamiento de turistas en Tenerife MATRIZ DE CASOS ROTADOS Nacionalidad F1 F2 Alemana 0,293 0,280 Austriaca -0,471 -0,512 Belga -0,294 -0,226 Británica 0,008 -0,692 Española -0,252 0,640 Europa excomunista -0,775 -0,520 Finlandesa 3,467 -0,580 Francesa -0,036 0,510 Holandesa -0,691 -1,370 Italiana -0,449 0,281 Resto América -0,454 -2,142 Resto Europa -0,112 0,769 Resto mundo -0,123 1,430 Sueca -0,067 1,515 Suiza -0,044 0,616 El objetivo es clasificar a las distintas nacionalidades de turistas de la muestra en grupos homogéneos, en función de las dos nuevas variables creadas en el Análisis de Componentes Principales. Los resultados obtenidos fueron:

73
Clasificación jerárquica
Procedimiento de clasificación: Análisis cluster jerárquico. Identifica grupos relativamente homogéneos de casos (o de variables) basándose en las características seleccionadas, mediante un algoritmo que comienza con cada caso (o variable) en un conglomerado diferente y combina los conglomerados hasta que sólo queda uno. Es posible analizar las variables brutas o elegir de entre una variedad de transformaciones de estandarización. Medidas de distancia o similitud: Proximidades. Los estadísticos se muestran en cada etapa para ayudar a seleccionar la mejor solución. Propósito: Unir los objetos (nacionalidades) en clusters sucesivamente más grandes, usando una cierta medida de semejanza o de distancia. Un resultado típico de este tipo de agrupación es el árbol jerárquico. Método: Transformación de matriz de datos originales en matriz de distancias euclídeas. 1ª etapa: agrupar los elementos con distancias más pequeñas. A continuación, atender a la menor de las distancias entre cada elemento agrupado con anterioridad y los que quedan en conglomerados individuales. El procedimiento continuará hasta llegar a alcanzar el número de conglomerados que se hayan fijado con anterioridad.
 basándose en las características seleccionadas, mediante un algoritmo que comienza con cada caso (o variable) en un conglomerado diferente y combina los conglomerados hasta que sólo queda uno. Es posible analizar las variables brutas o elegir de entre una variedad de transformaciones de estandarización. Medidas de distancia o similitud: Proximidades. Los estadísticos se muestran en cada etapa para ayudar a seleccionar la mejor solución. Propósito: Unir los objetos (nacionalidades) en clusters sucesivamente más grandes, usando una cierta medida de semejanza o de distancia. Un resultado típico de este tipo de agrupación es el árbol jerárquico. Método: Transformación de matriz de datos originales en matriz de distancias euclídeas. 1ª etapa: agrupar los elementos con distancias más pequeñas. A continuación, atender a la menor de las distancias entre cada elemento agrupado con anterioridad y los que quedan en conglomerados individuales. El procedimiento continuará hasta llegar a alcanzar el número de conglomerados que se hayan fijado con anterioridad.")
74
Ventanas de SPSS Analizar Clasificar Conglomerados jerárquicos

75
Resultados: Matriz distancias euclídeas al cuadrado
Casos 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 1:Alemana 0,000 1,211 0,601 1,027 0,426 1,781 10,813 0,161 3,693 0,550 6,427 0,403 1,495 1,654 0,227 2:Austriaca 0,113 0,262 1,374 0,093 15,510 1,233 0,785 0,630 2,658 1,769 3,892 4,270 1,454 3:Belga 0,309 0,750 0,318 14,272 0,607 1,467 0,281 3,699 1,022 2,770 3,081 0,771 4:Británica 1,841 0,643 11,977 1,446 0,949 1,156 2,317 2,149 4,520 4,875 1,713 5:Española 1,618 15,317 0,064 4,231 0,167 7,779 0,036 0,641 0,800 0,044 6:Eur. Exc. 17,998 1,606 0,730 0,748 2,735 2,100 4,226 4,640 1,823 7:Finlandesa 13,454 17,918 16,075 17,818 14,632 16,929 16,877 13,759 8:Francesa 3,962 0,223 7,207 0,073 0,855 1,012 0,011 9:Holandesa 2,786 0,653 4,910 8,162 8,711 4,362 10:Italiana 5,874 0,351 1,425 1,667 0,275 11:R.América 8,592 12,870 13,523 7,775 12:R.Europa 0,437 0,558 0,028 13:R.mundo 0,010 0,669 14:Sueca 0,809 15:Suiza Están resaltados en negrilla, las distancias más pequeñas como son la existente entre la nacionalidad sueca y resto del mundo con una distancia de 0.010, francesa y suiza con una distancia de y suiza y resto de Europa con una distancia euclídea al cuadrado de y española y resto de Europa con una distancia de

76
Resultados: Historial de conglomeración

77
Diagrama de Témpanos

78
Resultados: Dendograma

79
CONCLUSIONES Cluster 1:
Resto del Mundo, suecos, franceses, suizos, españoles, resto de Europa, italianos y Alemanes. Cluster 2: Austriacos, Europa excomunista, belgas, británicos, holandeses y resto de América. Cluster 3: Finlandeses.

80
Caso a resolver: Resultados de la rotación varimax en el ACP para el posicionamiento de casas de moda Clasificar a las casas de moda del caso resuelto en ACP en grupos homogéneos, a partir de los resultados obtenidos en dicho análisis una vez rotado.

81
6. Análisis de la Varianza Paramétrico y no Paramétrico
El Analisis de la Varianza es una prueba estadística de homogeneidad de los comportamientos medios de una determinada característica o variable respuesta, para k poblaciones independientes, correspondientes a k condiciones distintas de un determinado factor. Esta prueba paramétrica puede considerarse como una extensión del contraste paramétrico de igualdad de medias para dos poblaciones independientes, ya estudiado anteriormente. Al igual que éste, el Análisis de la Varianza requiere la verificación de una serie de supuestos, como puede ser la normalidad, homocedasticidad, etc. En caso de que no se cumpla algunos de estos supuestos, hemos estudiado algunos procedimientos alternativos, encuadrados dentro de los contrastes no paramétricos que podríamos llamar análisis de la varianza no paramétrico.. H0: 1 = 2 = … = k H1: (i,j) / i ≠ j
 / i ≠ j.")
82
CONCEPTOS A continuación se van a definir los principales términos que intervienen en el análisis de la varianza: Es la variable dependiente o característica objeto de nuestro estudio y que cuantifica el efecto de una serie de condiciones que influyen sobre ella. Por tanto, se necesita que dicha variable pueda medirse en escala cuantitativa. Es cada una de las variables independientes o explicativas que influyen en la característica de estudio o variable respuesta. Cada factor debe incluir las diferentes condiciones a las que se somete a los individuos para analizar el efecto diferencial de las mismas. A las distintas modalidades que presenta un factor se les denomina niveles. Estos suelen diferenciarse en tratamientos (cuando se pueden manipular las condiciones del factor) o modos de clasificación (cuando las condiciones del factor no son susceptibles de manipulación). VARIABLE RESPUESTA FACTOR NIVELES
 o modos de clasificación (cuando las condiciones del factor no son susceptibles de manipulación). VARIABLE RESPUESTA. FACTOR. NIVELES.")
83
Las muestras han de ser extraídas de forma aleatoria.
SUPUESTOS BÁSICOS Las muestras han de ser extraídas de forma aleatoria. Las puntuaciones u observaciones han de ser independientes entre sí. Las observaciones del j-ésimo grupo (Xij, i=1,…,nj) deben tener distribución Normal de media j. Todos los grupos deben tener la misma varianza poblacional 2, lo que se conoce como homocedasticidad. La variable respuesta debe ser cuantitativa, mientras que la variable independiente o factor se establece a modo de categorías, pudiendo ser cuantitativa o cuantitativa. DISEÑOS SEGÚN TIPO DE FACTORES Los niveles observados incluyen todos los posibles, o bien, todos los que interesan Factor fijo Modelo de efectos fijos El número de posibles niveles del factor es elevado y se seleccionan aleatoriamente algunos para realizar el estudio. Factor aleatorio Modelo de efectos aleatorios Intervienen factores fijos y aleatorios Modelo de efectos mixtos
 deben tener distribución Normal de media j. Todos los grupos deben tener la misma varianza poblacional 2, lo que se conoce como homocedasticidad. La variable respuesta debe ser cuantitativa, mientras que la variable independiente o factor se establece a modo de categorías, pudiendo ser cuantitativa o cuantitativa. DISEÑOS SEGÚN TIPO DE FACTORES. Los niveles observados incluyen todos los posibles, o bien, todos los que interesan. Factor fijo. Modelo de efectos fijos. El número de posibles niveles del factor es elevado y se seleccionan aleatoriamente algunos para realizar el estudio. Factor aleatorio. Modelo de efectos aleatorios. Intervienen factores fijos y aleatorios. Modelo de efectos mixtos.")
84
VARIABILIDAD El Análisis de la Varianza permite separar el efecto que sobre la variable respuesta ejerce uno o varios factores controlados del de otros no controlados, contrastando la influencia de los factores controlados sobre los resultados. La variabilidad total de la variable respuesta se puede dividir en dos partes. La causada por el factor controlable y sus niveles; y la originada por el resto de factores, conocidos o no, que influyen sobre ella, llamada variabilidad debida al error experimental. Esta división daría lugar a dos tipos de varianzas: (1) Varianza dentro de los grupos: Representa la variabilidad debida al error experimental, causante de las posibles diferencias existentes entre los elementos de cada grupo. (2) Varianza entre grupos: Representa la variabilidad existente entre los grupos debida al efecto de los diferentes niveles del factor. Para decidir si existen diferencias entre o no como consecuencia de los diferentes niveles del factor, esta técnica se basará en la comparación de los estimadores de las dos varianzas definidas.
 Varianza dentro de los grupos: Representa la variabilidad debida al error experimental, causante de las posibles diferencias existentes entre los elementos de cada grupo. (2) Varianza entre grupos: Representa la variabilidad existente entre los grupos debida al efecto de los diferentes niveles del factor. Para decidir si existen diferencias entre o no como consecuencia de los diferentes niveles del factor, esta técnica se basará en la comparación de los estimadores de las dos varianzas definidas.")
85
PLANTEAMIENTO INICIAL
Este modelo se caracteriza porque la variable respuesta considerada depende de un único factor con k niveles, quedando el resto de las causas de variación englobadas en el error experimental. El objetivo del mismo será contrastar la homogeneidad de promedios de la variable respuesta para k poblaciones independientes, pudiendo expresarse de la siguiente manera: Si rechazamos la hipótesis nula, concluiremos que existen diferencias significativas entre los comportamientos promedio, ya que, al menos uno de ellos es diferente a los demás. H0: 1 = 2 = … = k H1: (i,j) / i ≠ j
 / i ≠ j.")
86
CONTRASTE PARAMÉTRICO: MODELO FACTORIAL SIMPLE. ANOVA I
Xij Valor de la variable respuesta para el i-ésimo individuo del j-ésimo grupo. Constante común para todas las observaciones que representa a la media poblacional. Aj Es la aportación cuantitativa del j-ésimo nivel del factor a la puntuación total, que refleja la diferencia entre la puntuación esperada del j-ésimo grupo j y la puntuación esperada para toda la población, . ij Error experimental de cada puntuación, que indica la parte de Xij no explicada por las otras dos componentes. Se verifica que ij N (0, 2) Al ser los valores de , Aj y ij desconocidos, habrá que estimarlos, por ejemplo, utilizando el método de los mínimos cuadrados, dando lugar a: Por tanto, el modelo quedaría:
 Al ser los valores de , Aj y ij desconocidos, habrá que estimarlos, por ejemplo, utilizando el método de los mínimos cuadrados, dando lugar a: Por tanto, el modelo quedaría:")
87
Debida al factor (entre grupos) Debida al error (dentro de los grupos)
Así pues: En términos de las sumas de cuadrados se tiene que: A partir de SCT se obtienen los estimadores de las varianzas: Se puede demostrar que S2T, S2F y S2E son estimadores insesgados de 2. SCT = SCF + SCE Cuasivarianza Total Debida al factor (entre grupos) Debida al error (dentro de los grupos) Además
 Debida al error (dentro de los grupos) Además.")
88
La región crítica asociada al contraste será:
siendo el estadístico de contraste: El cuadro resumen de todo el proceso vendrá dado por: Variabilidad Suma de cuadrados g. l. Estimador Estadístico Punto crítico FACTOR ERROR SCF SCE k-1 n-k SF2 = SCF/(k-1) SE2 = SCF/(n-k) F = SF2 / SE2 Fk-1,n-k,1- TOTAL SCT n-1 ST2 = SCT/(n-1) Contraste unilateral a la derecha: A mayor numerador respecto al denominador, mayor posibilidad de rechazar la hipótesis nula. Mientras más pequeño, mayor posibilidad de no rechazarla.
 SE2 = SCF/(n-k) F = SF2 / SE2. Fk-1,n-k,1- TOTAL. SCT. n-1. ST2 = SCT/(n-1) Contraste unilateral a la derecha: A mayor numerador respecto al denominador, mayor posibilidad de rechazar la hipótesis nula. Mientras más pequeño, mayor posibilidad de no rechazarla.")
89
Caso: Comparación del precio de pan de molde
Se ha realizado un experimento con el fin de comparar los precios de la barra de pan de molde en cuatro ciudades diferentes. La muestra está formada por ocho almacenes para las tres primeras ciudades, mientras que para la cuarta está formada por siete almacenes, todos ellos seleccionados aleatoriamente.

90
Comandos SPSS Introducir datos en columna: Variable ciudad, variable precios Analizar Comparar medias ANOVA de un factor Dependiente: precios Factor: ciudad Opciones: Estadísticos: Descriptivos Homogeneidad de varianzas Gráfico de medias Post hoc: Tukey

91
Planteamiento Modelo factorial simple con efectos fijos, ya que las conclusiones se referirán exclusivamente a esas cuatro ciudades. Variable independiente: Ciudad, con cuatro niveles. Variable respuesta (dependiente): precio de la barra de pan. Objetivo: determinar si hay diferencias significativas entre los precios medios de la barra de pan en las cuatro ciudades. Hipótesis Estadístico del contraste: será una F de Snedecor: Contraste unilateral a la derecha: A mayor numerador respecto al denominador, mayor posibilidad de rechazar la hipótesis nula. Mientras más pequeño, mayor posibilidad de no rechazarla.
: precio de la barra de pan. Objetivo: determinar si hay diferencias significativas entre los precios medios de la barra de pan en las cuatro ciudades. Hipótesis. Estadístico del contraste: será una F de Snedecor: Contraste unilateral a la derecha: A mayor numerador respecto al denominador, mayor posibilidad de rechazar la hipótesis nula. Mientras más pequeño, mayor posibilidad de no rechazarla.")
92
Ejemplo de ANOVA I. Resultados SPSS

93
Resultados ANOVA I SPSS
Conclusión: A nivel de significación del 5%, se rechaza la hipótesis nula de igualdad de medias. Hay diferencias significativas entre los precios medios del pan de las cuatro ciudades.

94
Resultados SPSS. Pruebas dos a dos
Los promedios de precios son significativamente distintos, salvo entre las ciudades 1 y 2.

95
CONTRASTES NO PARAMÉTRICOS DE IGUALDAD DE PROMEDIOS
Pruebas de hipótesis de características poblacionales si no se conoce la distribución de probabilidad de la variable de la que procede la muestra. Si hay razones para presuponer una determinada distribución, hay que hacer una prueba paramétrica. Es estadísticamente mejores. De gran utilidad en economía y empresa, en las que es difícil que se cumpla la hipótesis de normalidad de la distribución de probabilidad de las variables que se están estudiando.

96
Test U de Mann-Whitney Objetivo:
Contrastación de promedios de dos poblaciones a partir de dos muestras independientes. Supuestos: Observaciones extraídas de muestras aleatorias. Valores ordenables (escala no nominal) Hipótesis nula: Los datos muestrales proceden de dos poblaciones con la misma medida de tendencia central, la mediana, para poderlo aplicar a datos ordinales. Metodología: Combinación de las n y m observaciones procedentes de dos poblaciones ordenadas en orden creciente de magnitud, asignando a cada una un rango de 1 a n+m.
 Hipótesis nula: Los datos muestrales proceden de dos poblaciones con la misma medida de tendencia central, la mediana, para poderlo aplicar a datos ordinales. Metodología: Combinación de las n y m observaciones procedentes de dos poblaciones ordenadas en orden creciente de magnitud, asignando a cada una un rango de 1 a n+m.")
97
Caso: Dietas alternativas de engorde de cerdos
Se quiere comparar dos dietas distintas para engorde de cerdos. Para ello se seleccionan 8 cerdos de 6 meses de edad de la granja A que los alimenta con la primera dieta, y a 12 cerdos de la misma edad de la granja B que usa la segunda, obteniéndose el incremento de peso en el último mes. Los resultados se reflejan en la tabla adjunta. Comprobar, con un 5% de significación, que existen diferencias significativas en el promedio de incremento de peso de los cerdos en el último mes entre las dos dietas. (Se ha comprobado previamente la no normalidad de los incrementos de peso en ambas granjas). Hipótesis: H0: 1 = 2 Ha: 1 2
. Hipótesis: H0: 1 = 2. Ha: 1 2.")
98
Ejemplo Test de Mann-Whitney. Comandos SPSS
Introducir datos: Igual que ANOVA Analizar Pruebas no paramétricas Dos muestras independientes Contrastar variables: Incremento peso Variable de agrupación: Granjas Definir grupos: (1 2) Tipo de prueba: U de Mann-Whitney Opciones: Estadísticos descriptivos
 Tipo de prueba: U de Mann-Whitney. Opciones: Estadísticos descriptivos.")
99
Ejemplo Test de Mann-Whitney. Resultados SPSS
Las dos dietas no producen por término medio los mismos resultados en cuanto al engorde de los animales. Aparentemente, el engorde es mayor en la dieta aplicada en la granja B que en la aplicada en la granja A.

100
Test de Wilcoxon Objetivo:
Contrastar si los dos promedios de variables relacionadas procedentes de una misma población o son diferentes. Supuestos: Observaciones extraídas de muestras aleatorias relacionadas. Valores ordenables (escala no nominal) Hipótesis nula: Los datos muestrales proceden de dos poblaciones con la misma medida de tendencia central. Metodología: Diferencias de los n pares de observaciones procedentes de dos poblaciones ordenadas en orden creciente, independientemente del signo, asignando a cada una un rango de 1 a n.
 Hipótesis nula: Los datos muestrales proceden de dos poblaciones con la misma medida de tendencia central. Metodología: Diferencias de los n pares de observaciones procedentes de dos poblaciones ordenadas en orden creciente, independientemente del signo, asignando a cada una un rango de 1 a n.")
101
Caso: Comparación de dos materiales para fabricación de tacones de zapatos de caballero
En un experimento para comparar dos materiales distintos, A y B, que se deben utilizar para fabricar tacones de zapatos de caballero, se seleccionó a 15 hombres y se les proporcionó un par de zapatos nuevos de los cuales un tacón estaba hecho con el material A y el otro con el material B. Al principio del experimento, cada tacón tenía un grosor de 10 mm. Después de usar los zapatos durante un mes, se midió el grosor restante, resultando Verificar que no existen diferencias significativas en el el grosor resultante de los tacones entre ambos materiales, usando un α=0,05. Hipótesis de partida serán: H0: 1 = 2 Ha: 1 2

102
Ejemplo Test de Wilcoxon. Resultados SPSS
El estadístico es igual a –1,96. Está en el límite de (-1,96; 1,96), por lo que se concluye que, a un nivel de significación del 5%, no estamos seguros de aceptar o rechazar la hipótesis nula. En este caso se debería recomendar aumentar el tamaño de la muestra para estar más seguros si existen diferencias significativas en el grosor resultante de los tacones entre ambos materiales.
, por lo que se concluye que, a un nivel de significación del 5%, no estamos seguros de aceptar o rechazar la hipótesis nula. En este caso se debería recomendar aumentar el tamaño de la muestra para estar más seguros si existen diferencias significativas en el grosor resultante de los tacones entre ambos materiales.")
103
Test de Kruskall-Wallis
Objetivo: Decidir si varias muestras independientes (más de dos) puede considerarse que provienen de poblaciones con la misma distribución, desde el punto de vista de su promedio. Supuestos: Observaciones extraídas de muestras aleatorias relacionadas. Valores ordenables (escala no nominal) Hipótesis nula: Los datos muestrales proceden de dos poblaciones con la misma medida de tendencia central. Metodología: Se asignan rangos, de 1 a n (n = n1 + n nk).
 puede considerarse que provienen de poblaciones con la misma distribución, desde el punto de vista de su promedio. Supuestos: Observaciones extraídas de muestras aleatorias relacionadas. Valores ordenables (escala no nominal) Hipótesis nula: Los datos muestrales proceden de dos poblaciones con la misma medida de tendencia central. Metodología: Se asignan rangos, de 1 a n (n = n1 + n nk).")
104
Caso: Influencia de la renta familiar en el nivel cultural de los hijos
Se desea saber si la renta familiar influye en el grado de cultura de los hijos. Para verificarlo se toman cuatro niveles de renta y en cada uno un cierto número de familias con niños comprendidos entre ciertas edades. Se somete a los niños a tests cuyos resultados, expresados en la tabla adjunta, reflejan el grado de cultura. Usar un 5% de significación. Hipótesis: H0: 1 = 2= 3 = 4 Ha: 1 2 3 4

105
Ejemplo Test de Kruskall-Wallis. Comandos SPSS
Introducir datos: Columna para cada variable Analizar Pruebas no paramétricas k muestras independientes Contrastar Variables: Puntuaciones Variable de agrupación Definir rango (1 4) Tipo de prueba: H de Kruskall-Wallis Opciones: Estadísticos descriptivos
 Tipo de prueba: H de Kruskall-Wallis. Opciones: Estadísticos descriptivos.")
106
Ejemplo Test de Kruskall-Wallis. Resultados SPSS
Con un nivel de significación del 5%, se rechaza la hipótesis nula de igualdad de promedios poblacionales. Al menos uno de los promedios es diferente al del resto. Efectivamente, hay diferencias significativas en el grado de cultura de los hijos según el nivel de renta de los padres.

107
Test de Friedman Objetivo:
Comparar en términos promedio el comportamiento de los mismos individuos bajo k (> 2) condiciones diferentes. Supuestos: Observaciones de muestras aleatorias independientes. Valores ordenables (escala no nominal) Hipótesis nula: Los datos muestrales proceden de k poblaciones con la misma medida de tendencia central. Metodología: De forma independiente, en los datos o puntuaciones de cada fila se asignan rangos, correspondiendo el 1 a la puntuación menor de la fila y el k a la mayor puntuación
 condiciones diferentes. Supuestos: Observaciones de muestras aleatorias independientes. Valores ordenables (escala no nominal) Hipótesis nula: Los datos muestrales proceden de k poblaciones con la misma medida de tendencia central. Metodología: De forma independiente, en los datos o puntuaciones de cada fila se asignan rangos, correspondiendo el 1 a la puntuación menor de la fila y el k a la mayor puntuación.")
108
Caso: Comparación de calificaciones en una prueba de salto
Cuatro jueces se encargan de calificar en una competencia de salto que incluye a 10 finalistas. Los datos que figuran en la tabla siguiente son calificaciones, donde un 10 indica un salto perfecto. Para una significación del 1%, determinar si existe diferencia significativa en las calificaciones que otorgan cada uno de los cuatro jueces. H0: 1 = 2= 3 = 4 Ha: 1 2 3 4

109
Ejemplo Test de Friedman. Comandos SPSS
Introducir datos: Columna para cada variable Analizar Pruebas no paramétricas k muestras independientes Contrastar Variables: Calificaciones Tipo de prueba: Friedman Opciones: Estadísticos descriptivos

110
Ejemplo Test de Friedman. Resultados SPSS
Con un nivel de significación del 1%, hay diferencias significativas en al menos una de las calificaciones que otorgan cada uno de los cuatro jueces.

111
7. Análisis Discriminante
Técnica multivariante de clasificación de individuos en grupos sistemáticamente distintos, utilizando también técnicas factoriales. Se parte de dos o más grupos de objetos o individuos, de los que conocemos los valores de p variables. Objetivo: Explicar la pertenencia de cada individuo a un grupo (variable categórica) según la variable aleatoria p-dimensional del objeto (variable explicativa). Predecir a qué grupo pertenece un individuo nuevo, del que conocemos el valor de la variable p dimensional clasificadora o explicativa. Puede aplicarse para: Describir: Explicar la diferencia entre los distintos tipos de objetos. Hacer Inferencia: Contrastar diferencias significativas entre poblaciones. Tomar de decisiones: Decidir donde clasificar un objeto.
 según la variable aleatoria p-dimensional del objeto (variable explicativa). Predecir a qué grupo pertenece un individuo nuevo, del que conocemos el valor de la variable p dimensional clasificadora o explicativa. Puede aplicarse para: Describir: Explicar la diferencia entre los distintos tipos de objetos. Hacer Inferencia: Contrastar diferencias significativas entre poblaciones. Tomar de decisiones: Decidir donde clasificar un objeto.")
112
SUPUESTOS Existen K poblaciones o grupos G1, G2,....Gk.
Cada grupo está formado por n1, n2,...nk objetos: . Sobre cada objeto han sido medidas p variables x1, x2,.xp, Se quiere buscar una regla de decisión que permita asignar un objeto a uno de los grupos partiendo de la información anterior. Los datos se presentan en matriz de n objetos pertenecientes a K grupos, medidos por una variable aleatoria p dimensional y una variable discreta que indica el grupo al que pertenece cada objeto.

113
CLASIFICACIÓN Funciones discriminantes lineales de Fisher:
Permiten diferenciar los grupos para el proceso de clasificación. Son combinación lineal de las P variables, interviniendo cada una con un peso diferente que indica las que más discriminan. Problema descriptivo. Funciones discriminantes canónicas: Sirven para la predicción óptima del grupo a que pertenece un individuo. Problema de inferencia.

114
CLASIFICACIÓN CON DOS GRUPOS Y UNA VARIABLE CLASIFICADORA, X
Problema: Clasificar a cada individuo en el grupo correcto, según la variable clasificadora. Gráficamente, podríamos representar las hipotéticas funciones de frecuencias de la variable X para cada uno de los dos grupos. Las distribuciones de frecuencias y la varianza son iguales, coincidiendo en todo menos en su media. Se pueden solapar: pueden haber errores de clasificación. Xi<C, clasificar al individuo i en grupo I. Xi>C, clasificar al individuo i en grupo II Los errores de clasificación están en : Área a la derecha de C : Casos del grupo I donde Xi>C: casos del grupo I mal clasificados en el grupo II. Área a la izquierda de C : Casos del grupo II donde Xi<C,: casos del grupo II mal clasificados en el grupo I.

115
CLASIFICACIÓN CON DOS GRUPOS Y UNA VARIABLE CLASIFICADORA, X
Problema: Clasificar a cada individuo en el grupo correcto, según la variable clasificadora. Gráficamente, podríamos representar las hipotéticas funciones de frecuencias de la variable X para cada uno de los dos grupos. Las distribuciones de frecuencias y la varianza son iguales, coincidiendo en todo menos en su media. Se pueden solapar: pueden haber errores de clasificación. Xi<C, clasificar al individuo i en grupo I. Xi>C, clasificar al individuo i en grupo II Los errores de clasificación están en : Área a la derecha de C : Casos del grupo I donde Xi>C: casos del grupo I mal clasificados en el grupo II. Área a la izquierda de C : Casos del grupo II donde Xi<C,: casos del grupo II mal clasificados en el grupo I.

116
Caso: Situación de las Comunidades Autónomas españolas en cuanto a indicadores de bienestar
En el periódico “El País” del día 17 de enero de 2002 se publicó un resumen de un estudio incluido en el Anuario social de España 2001 de la Caixa, elaborado por la Universidad Autónoma de Madrid, sobre el mapa de bienestar de las provincias españolas para el año 2001, clasificándolas a partir de las 12 variables siguientes: El estudio establece una clasificación según el bienestar de las provincias. Queremos hacer un estudio similar, pero considerando el mapa de las autonomías y los datos correspondientes al Anuario social de España de Tras la aplicación de un análisis cluster jerárquico a los indicadores según autonomía, conseguimos formar cuatro grupos.

117
DATOS CC.AA Grupo p1 p2 p3 p4 p5 p6 p7 p8 p9 p10 p11 p12 Andalucía 1 2
Castilla-La Mancha 7 8 Extremadura Murcia 9 Aragón Castilla-León La Rioja Asturias Canarias Cantabria Galicia Valencia Baleares 10 Cataluña Madrid Navarra Euskadi

118
Objetivo y metodología del estudio
Contrastar si la clasificación que realizamos de las Comunidades Autónomas españolas es correcta, dependiendo de las 12 variables consideradas. Metodología: La técnica adecuada es el Análisis Discriminante. En él, la variable grupo de bienestar es la variable dependiente, mientras que el resto son las variables independientes que, previsiblemente, discriminan.

119
Obtención de las funciones discriminantes
Criterio: Maximizar variabilidad entre grupos respecto a la de dentro de ellos. Sea un eje definido por el vector unitario U, de dimensión p*1. La proyección del individuo i-ésimo sobre él es el peso zi: Proyección de los n individuos: Vector Z (nx1), (Z=XU), función discriminante de Fisher. Es una combinación lineal de las k variables explicativas originales. Problema:Obtener los coeficientes de ponderación uj. Hay que tener en cuenta que : 1. La matriz a diagonalizar no es simétrica: los vectores propios no son necesariamente ortogonales. 2. El número de ejes discriminantes, F es como máximo el mínimo de [(K-1), p].
, (Z=XU), función discriminante de Fisher. Es una combinación lineal de las k variables explicativas originales. Problema:Obtener los coeficientes de ponderación uj. Hay que tener en cuenta que : 1. La matriz a diagonalizar no es simétrica: los vectores propios no son necesariamente ortogonales. 2. El número de ejes discriminantes, F es como máximo el mínimo de [(K-1), p].")
120
Métodos iterativos de selección de variables
Método de inclusión iterativa En cada paso se selecciona la variable que más contribuye a la separación de los grupos. El proceso se detiene si ninguna variable separa los grupos significativamente más de lo que ya estaban. Método de exclusión iterativa Se incluyen todas las variables y en cada paso se elimina la que menos contribuye a la separación de los grupos. El proceso se detiene cuando la exclusión de cualquiera de las variables hace disminuir significativamente la separación entre los grupos. Método mixto de inclusión-exclusión: Stepwise En cada etapa se evalúa la posibilidad de incluir o excluir una variable, según criterios prefijados. Su aplicación requiere definir previamente una regla de decisión, Landa de Wilks, cociente entre el determinante de la matriz de variación dentro de los grupos y el de la matriz de variación total.

121
Stepwise Con el landa de Wilks se calcula un estadístico F. Cuanto mayor sea F, más significativa será la variable para la que se calcula. Hay que fijar: F mínimo para entrar (F-min-to-enter). F máximo para salir (Fmax-to-go) (F to enter > F de salida). Nivel de tolerancia: Medida del grado de asociación lineal entre las variables clasificadoras. Si la tolerancia de la variable i es muy pequeña, significa que dicha variable está muy correlacionada con el resto, lo que puede provocar problemas en la estimación. Generalmente, se fija un nivel mínimo de tolerancia.
. F máximo para salir (Fmax-to-go) (F to enter > F de salida). Nivel de tolerancia: Medida del grado de asociación lineal entre las variables clasificadoras. Si la tolerancia de la variable i es muy pequeña, significa que dicha variable está muy correlacionada con el resto, lo que puede provocar problemas en la estimación. Generalmente, se fija un nivel mínimo de tolerancia.")
122
Cómo saber si los datos son apropiados
Si las poblaciones son normales, pero con matrices de covarianzas distintas, la regla de clasificación óptima se obtiene con funciones lineales cuadráticas. Excepto en el caso de dos variables, las funciones cuadráticas son difíciles de obtener, por su complejidad analítica. Sin embargo, los resultados prácticos no suelen diferir sustancialmente. Conviene, no obstante, contrastar la igualdad de matrices de covarianzas. Si las distribuciones de probabilidad poblacionales de los grupos son normales multivariantes con matrices de covarianzas iguales, y se fijan probabilidades a priori y costes idénticos para todos los grupos, la predicción con todas las funciones lineales discriminantes coincide con la clasificación óptima obtenida con la regla de decisión. Cuando las poblaciones no son normales, las probabilidades o verosimilitud de la muestra no se conocen, al no conocer la forma de la distribución probabilística de cada grupo. En este caso, puede sustituirse el cociente de verosimilitudes por el de distancias de Mahalanobis. Si las poblaciones son normales, ambos coinciden.

123
Ventanas SPSS 1 Analizar Clasificar Análisis discriminante
En la variable de agrupación pondremos la variable categórica que es la que indica el grupo de pertenencia de cada individuo en la matriz inicial. En nuestro caso se han considerado cuatro grupos. De 1 a 4 Pediremos las medias y los ANOVAS univariados. Además, pediremos los coeficientes de la función de Fisher, la correlación y la covarianza intra-grupos.

124
Ventanas SPSS 2 Si elegimos usar método de inclusión por pasos, debemos definir el que deseamos y los criterios. Utilizaremos la distancia de Mahalanobis. Además, indicaremos que el resultado muestre un resumen de los pasos y el valor de la F de Snedecor para las distancias por parejas. La distancia de Mahalanobis D² es una medida generalizada de distancia entre dos grupos que tiene en cuenta la posición central (centro de gravedad) y las dispersiones (matrices de productos cruzados o de covarianzas intragrupos) de los grupos. DI,II: matriz de productos cruzados (matriz de covarianzas intragrupos). Se asignará cada individuo al grupo para el que D² es menor.
 y las dispersiones (matrices de productos cruzados o de covarianzas intragrupos) de los grupos. DI,II: matriz de productos cruzados (matriz de covarianzas intragrupos). Se asignará cada individuo al grupo para el que D² es menor.")
125
Ventanas SPSS 3 Probabilidades previas:
Se puede elegir todos los grupos iguales o calcular según tamaño de grupos. Mostrar: Resultados para cada grupo y tabla resumen. Usar matriz de covarianzas intragrupos. Gráficos de los grupos combinados.

126
Resultados: Estadísticos descriptivos
Índice GRUPO 1 GRUPO 2 GRUPO 3 GRUPO 4 TOTAL Media Desv. típ. CVP Renta 2,25 0,957 0,426 5,5 1,512 0,275 8 9,25 0,104 5,765 2,796 0,485 Salud 5,75 1,893 0,329 4,75 1,669 0,351 3 6,25 1,708 0,273 5,235 1,786 0,341 Ss.sanitarios 3,75 0,255 6,625 1,847 0,279 7 0,500 0,054 6,588 2,347 0,356 N.educativo y cultural 3,25 0,295 6,5 1,309 0,201 5 6,294 2,365 0,376 Of.educativa, cultural/ocio 3,5 0,577 0,165 1,414 0,257 10 0,105 5,294 1,795 0,339 Empleo 4,5 1,915 1,282 0,223 0,177 6,118 1,900 0,311 Condiciones trabajo 2,754 0,441 1,035 0,218 2,517 0,387 5,529 1,940 Vivienda 0,167 5,125 1,553 0,303 6 2,054 0,326 Acces.ec.y seguridad vial 2,160 0,360 1,832 0,319 8,25 1,258 0,153 6,412 1,938 0,302 Conv.y partic.social 1,291 0,199 5,25 0,197 4,941 1,600 0,324 Seguridad ciudadana 6,375 1,408 0,221 4 1,826 0,609 1,929 0,364 Entorno natural y clima 1,155 0,289 2,446 0,369 2,582 0,430 6,059 2,512 0,415 Nº CASOS 1 17

127
Pruebas de igualdad de medias de los grupos
Lambda de Wilks F gl1 gl2 Sig. Índice de renta ,172 20,872 3 13 ,000 Índice de salud ,764 1,340 ,304 Índice de servicios sanitarios ,311 9,615 ,001 Índice de nivel educativo y cultural ,173 20,696 Índice de oferta educativa, cultural y de ocio 9,623 Índice de empleo ,493 4,450 ,023 Índice decondiciones trabajo (calidad del empleo) ,818 ,967 ,438 Índice de vivienda y equipamiento del hogar ,302 10,029 Índice de accesibilidad económica y seguridad vial ,703 1,833 ,191 Índice de convivencia y participación social ,372 7,300 ,004 Índice de seguridad ciudadana ,447 5,355 ,013 Índice de entorno natural y clima ,653 2,307 ,125 La lambda de Wilk oscila entre 0 y 1. Valores pequeños indican fuertes diferencias de grupo y los cercanos a 1 no diferencias de grupo. F es una proporción de variabilidad entre-grupos y variabilidad intra-grupos. Variables con los menores valores de lambda: Nivel de instrucción, vivienda, riqueza, servicios sanitarios y educación, cultura y ocio, Empleo y accesibilidad económico-comercial con F significativos a menos de un 10%. Variables con niveles superiores de lambda: Condiciones de trabajo, sanidad, convivencia y participación social, entorno y clima y seguridad y medio ambiente, que no muestran diferencias significativas entre los grupos de bienestar, con niveles de significación de la F superiores al 10%.
 ,818. ,967. ,438. Índice de vivienda y equipamiento del hogar. , ,029. Índice de accesibilidad económica y seguridad vial. ,703. 1,833. ,191. Índice de convivencia y participación social. ,372. 7,300. ,004. Índice de seguridad ciudadana. ,447. 5,355. ,013. Índice de entorno natural y clima. ,653. 2,307. ,125. La lambda de Wilk oscila entre 0 y 1. Valores pequeños indican fuertes diferencias de grupo y los cercanos a 1 no diferencias de grupo. F es una proporción de variabilidad entre-grupos y variabilidad intra-grupos. Variables con los menores valores de lambda: Nivel de instrucción, vivienda, riqueza, servicios sanitarios y educación, cultura y ocio, Empleo y accesibilidad económico-comercial con F significativos a menos de un 10%. Variables con niveles superiores de lambda: Condiciones de trabajo, sanidad, convivencia y participación social, entorno y clima y seguridad y medio ambiente, que no muestran diferencias significativas entre los grupos de bienestar, con niveles de significación de la F superiores al 10%.")
128
Matriz de correlaciones
Las matrices intra-grupos combinadas muestran una matriz de covarianzas y una matriz de correlaciones. Son diferentes de las matrices usuales donde todos los casos son tratados como una muestra individual. Las covarianzas intra-grupos combinadas se obtienen promediando las matrices de covarianzas separadas para todos los grupos. Las correlaciones intra-grupos combinadas se calculan a partir de las covarianzas y varianzas.

129
Variables introducidas/eliminadas en el análisis
Paso Introducidas Eliminadas Mín. D cuadrado Estadístico Entre grupos F exacta gl1 gl2 Sig. 1 N.Educativo 1,887 2 y 3 1,677 13 0,218 2 Renta 10,223 2 y 4 12,582 12 0,001 3 Of.Educativa 10,530 1 y 2 7,920 11 0,004 4 7,905 9,729 0,003 5 Vivienda 15,903 11,961 6 Conv.y Part.Social 16,958 8,697 10 Distancia de Mahalanobis grande: Casos con valores extremos en una o más variables independientes. En cada paso se introduce la variable que maximiza la distancia de Mahalanobis entre los grupos más cercanos. Paso 1: la variable que maximiza la distancia de Mahalanobis entre los dos grupos más cercanos (2 y 3) es el Nivel educativo y cultural. Paso 2: Renta entre los grupos 2 y 4. Paso 3: Oferta educativa entre los grupos 1 y 2. Paso 4: Se elimina la variable Renta, puesto el estadístico desciende respecto a los anteriores entre los grupos 2 y 4. Paso 5: Se introduce la variable Vivienda puesto que maximinza la distancia entre los grupos 2 y 4 que son los más cercanos. Paso 6: Convivencia y participación social entre los grupos 2 y 4.
 es el Nivel educativo y cultural. Paso 2: Renta entre los grupos 2 y 4. Paso 3: Oferta educativa entre los grupos 1 y 2. Paso 4: Se elimina la variable Renta, puesto el estadístico desciende respecto a los anteriores entre los grupos 2 y 4. Paso 5: Se introduce la variable Vivienda puesto que maximinza la distancia entre los grupos 2 y 4 que son los más cercanos. Paso 6: Convivencia y participación social entre los grupos 2 y 4.")
130
Estadísticos para las variables en el análisis
Tolerancia: Proporción de la varianza de la variable que no es explicada por las otras variables independientes. Se utiliza para determinar cuantas variables independientes están linealmente relacionadas con las otras (multicolinealidad). Una variable con muy baja tolerancia contribuye con poca información al modelo y puede causar problemas de cálculo. F para eliminar: Útil para describir qué ocurre si la variable es eliminada del modelo presente. Es la misma que la F para entrar en la etapa anterior. Dependiendo del método por pasos elegido, podemos ver otros estadísticos tales como la lambda de Wilks.
. Una variable con muy baja tolerancia contribuye con poca información al modelo y puede causar problemas de cálculo. F para eliminar: Útil para describir qué ocurre si la variable es eliminada del modelo presente. Es la misma que la F para entrar en la etapa anterior. Dependiendo del método por pasos elegido, podemos ver otros estadísticos tales como la lambda de Wilks.")
131
Número de variables en cada etapa
Lambda: Contraste multivariante de significación. Contraste de hipótesis de igualdad de medias entre los grupos para cada uno de los pasos. Oscila entre 0 y 1. Valores cercanos a 0: las medias de los grupos son diferentes. Valores cercanos a 1: las medias de los grupos no son diferentes. Lambda y sus grados de libertad son transformados en un estadístico F. Si el valor de significación es pequeño (menor que 0,10) indica que las medias de los grupos difieren. Si el valor de significación es grande (mayor que 0,10) indica que las medias de los grupos no difieren. Como el nivel de significación o área que deja a la derecha el estadístico es, como máximo 0,012, a un nivel de significación del 5%, no se puede concluir que las medias de los grupos sean iguales. Es decir, se rechaza la igualdad de medias entre grupos de cada una de las variables incluidas en el análisis.
 indica que las medias de los grupos difieren. Si el valor de significación es grande (mayor que 0,10) indica que las medias de los grupos no difieren. Como el nivel de significación o área que deja a la derecha el estadístico es, como máximo 0,012, a un nivel de significación del 5%, no se puede concluir que las medias de los grupos sean iguales. Es decir, se rechaza la igualdad de medias entre grupos de cada una de las variables incluidas en el análisis.")
132
Comparaciones de grupos por pares: Última etapa
Los dos grupos con mayores F y menores niveles de significación son los que difieren más. Los dos grupos con menores F y mayores niveles de significación son los que difieren menos. Si el valor de significación es pequeño, la diferencia entre los grupos es significativa. Si el valor de significación es grande (mayor que el 5%) entonces la diferencia entre los grupos no es significativa.
 entonces la diferencia entre los grupos no es significativa.")
133
Funciones canónicas discriminantes
Valor propio: Cociente entre la suma de cuadrados intra-grupos e Inter.-grupos. El mayor valor propio corresponde al vector propio en la dirección de la máxima dispersión de las medias de los grupos. El segundo, al vector propio en la dirección que tiene la siguiente mayor dispersión, y así sucesivamente. La raíz cuadrada de cada valor propio proporciona un índice de la longitud del correspondiente vector propio. Valores propios pequeños explican muy poco de la dispersión total. % de varianza: Evalúa la dispersión de cada variable canónica. % acumulado: Porcentaje de la dispersión total explicada por las variables canónicas. Las dos primeras variables canónicas explican el 100% de la dispersión total. Correlación canónica: mide la asociación entre las puntuaciones discriminantes y los grupos. Valores cercanos a 1 indican una fuerte correlación entre las puntuaciones discriminantes y los grupos. Número de variables canónicas: Cuando hay más de dos grupos, es k-1 (donde k es el número de grupos) o p (el número de variables), el que sea menor de los dos.
 o p (el número de variables), el que sea menor de los dos.")
134
Prueba de hipótesis igualdad de medias entre grupos de las funciones
La lambda de Wilks varía entre 0 y 1. Valores cercanos a 0 indican que las medias de los grupos son diferentes. Valores cercanos a 1 indican que las medias de los grupos no son diferentes (igual a 1 indica que todas las medias son la misma). Chi-cuadrado de la lambda de Wilks determina la significación. Si es pequeña (menor que el 10%) indica que las medias de grupo difieren. Si es grande, indica que las medias de los grupos no difieren.
. Chi-cuadrado de la lambda de Wilks determina la significación. Si es pequeña (menor que el 10%) indica que las medias de grupo difieren. Si es grande, indica que las medias de los grupos no difieren.")
135
Matriz de estructura Correlaciones intra-grupos de cada variable predictora con la función canónica. Proporciona otra forma de estudiar la utilidad de cada variable en la función discriminante. Para cada variable, en negrilla se marca su mayor correlación absoluta con una de las funciones canónicas, ordenándose luego por tamaño de correlación. Función 1: Oferta educativa, Empleo, Servicios sanitarios y Condiciones de trabajo. Función 2: Nivel educativo, Convivencia y participación social y Renta. Función 3: Vivienda, Seguridad ciudadana, Salud, Entorno y clima y Accesibilidad económica y seguridad vial.

136
Coeficientes de funciones canónicas
Se utilizan para calcular las puntuaciones de la variable canónica en cada caso. Si las variables son medidas en unidades diferentes, la magnitud de un coeficiente no estandarizado proporciona poca indicación de la contribución relativa de la variable a la discriminación global. Los coeficientes no tipificados de las funciones canónicas discriminantes son estrictamente proporcionales a los coeficientes tipificados de dichas funciones para cada una de las variables. Si sustituimos los valores de las variables para cada una de las Autonomías, obtendremos las puntuaciones discriminantes. Medias de las variables canónicas por grupos. Las medias intra-grupos se calculan para cada variable canónica. Funciones discriminantes canónicas no tipificadas evaluadas en las medias de los grupos. La estimación de la función de clasificación para las Comunidades Autónomas del grupo 1 es

137
Estimación del grupo con los coeficientes de las Funciones discriminantes lineales de Fisher
El programa SPSS no ofrece la función discriminante de Fisher, sino tantas funciones como grupos se hayan considerado para los casos. A partir de estas funciones se podría obtener la Función discriminante lineal de Fisher. Con ellas se podrá predecir en qué grupo debe estar un individuo. Para ello, habrá que sustituir en cada una de las funciones los valores originales de las tres variables para cada una de las Comunidades Autónomas. En nuestro caso, se clasificará la Comunidad Autónoma en aquel grupo cuyo valor sea mayor en una de las cuatro funciones discriminantes anteriores.

138
Resultados Con la función discriminante de Fisher todas las C.A. se clasifican en el mismo grupo inicial, salvo Valencia, que se estaba en el segundo grupo y, según la función discriminante de Fisher, hay que incluirla en el primer grupo.

139
Estadísticos de clasificación por casos
· Grupo real: el que se asignó a cada caso en la clasificación inicial. · Grupo mayor: En el que debe estar incluido cada caso, según las funciones discriminantes y con probabilidad a posteriori de pertenencia a él, P(G=g/ D=d), mayor, (teorema de Bayes), utilizando la Distancia de Mahalanobis, D2, y la probabilidad condicionada P(D>d/ G=g) · Segundo grupo mayor: en cuanto al valor de la probabilidad a posteriori. · Puntuaciones discriminantes: las obtenidas al sustituir los valores en las funciones discriminantes canónicas.
, mayor, (teorema de Bayes), utilizando la Distancia de Mahalanobis, D2, y la probabilidad condicionada P(D>d/ G=g) · Segundo grupo mayor: en cuanto al valor de la probabilidad a posteriori. · Puntuaciones discriminantes: las obtenidas al sustituir los valores en las funciones discriminantes canónicas.")
140
Gráfico Grupo 1: Andalucía, Castilla-La Mancha, Extremadura, Valencia y Murcia. Grupo 2: Canarias, Aragón, Castilla-León, Asturias, Cantabria, Galicia y La Rioja. Grupo 3: Baleares Grupo 4: Cataluña, Madrid, Euskadi y Navarra. La única Comunidad Autónoma reclasificada, pasándola del grupo 2 al 1 Valencia.

141
Conclusiones Las variables independientes que más discriminan entre los cuatro grupos iniciales referidos al bienestar de las autonomías son: Nivel educativo Oferta educativa Vivienda Convivencia y participación social Con las funciones discriminantes obtenidas, todas las comunidades autónomas se encuentran clasificadas en los mismos grupos inicialmente considerados, salvo Valencia que se había incluido en el grupo 2 y, a partir del Análisis Discriminante, parece mejor situada en el grupo 1.

142
Caso a resolver: Lugar previsible de residencia de los turistas en Tenerife
Objetivo: Lugar de residencia previsible de los turistas que vienen a Tenerife. Metodología: Cuestionario: Fichero: base turistas curso.sav Se han elegido: nacionalidad, noches, nº visitas, nº personas, edad, sexo y gasto/persona/noche. Se elige como variable dependiente de clasificación el lugar de residencia con tres posibilidades: Puerto de la Cruz, Las Américas-Los Cristianos, Resto.

Presentaciones similares