Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Píldora de evaluación estadística de ajuste de curvas Files con las tablas: T_tables.pdf F_tables.pdf Descargadas desde http://fsweb.berry.edu/academic/education/vbissonnette/tables/tables.html http://fsweb.berry.edu/academic/education/vbissonnette/tables/tables.html Ver también “A complete guide to nonlinear regression” http://www.curvefit.com/

2
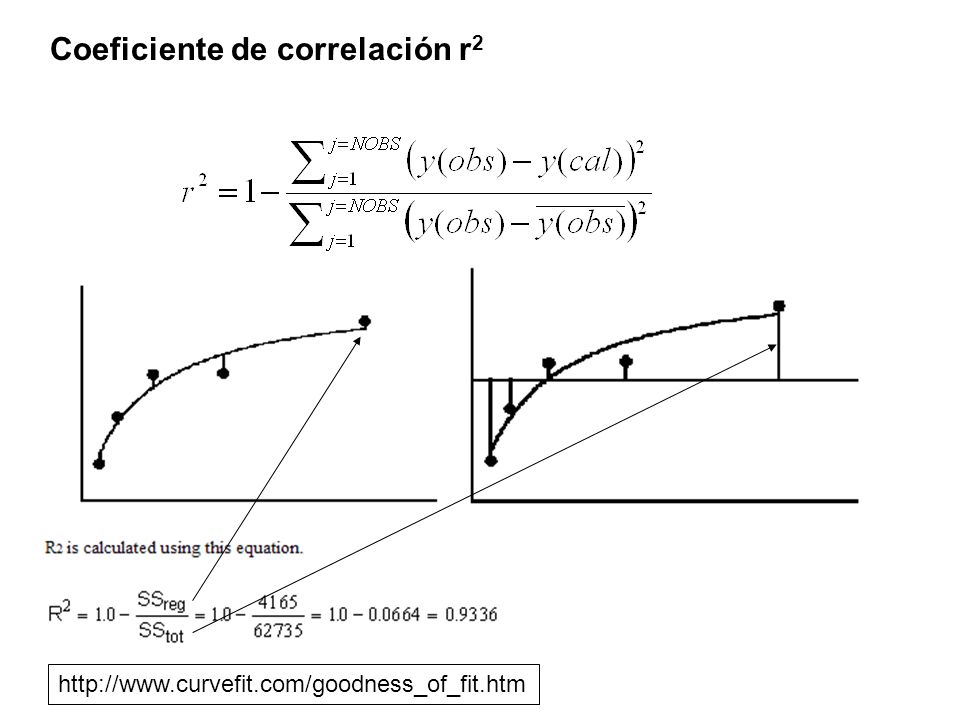
Tenemos una tabla con los resultados experimentales de una variable dependiente y en función de varias variables independientes x 1, x 2, x 3 … La tabla contiene NOBS filas en que las primeras columnas son las variables independientes y la última los valores observados de la variable dependiente y(obs) Producimos una función que suponemos que describe bien los datos experimentales. Esta función depende de las variables independientes (x 1, x 2, x 3 ) y un conjunto de NPAR parámetros a 1, a 2, a 3 ….a NPAR Usamos un programa de ajuste no lineal para encontrar los NPAR parámetros. Por ejemplo Solver de Excel. Solver nos entrega los parámetros encontrados más una lista de NOBS filas con valores calculados para la función para cada conjunto de variables independientes. Esto son los y(cal). Un gráfico en que se muestren los valores y(obs) e y(cal) de una impresión visual de la calidad del ajuste. Ver archivo AjusteExcel.xls Coeficiente de correlación r 2
 y un conjunto de NPAR parámetros a 1, a 2, a 3 ….a NPAR Usamos un programa de ajuste no lineal para encontrar los NPAR parámetros. Por ejemplo Solver de Excel. Solver nos entrega los parámetros encontrados más una lista de NOBS filas con valores calculados para la función para cada conjunto de variables independientes. Esto son los y(cal). Un gráfico en que se muestren los valores y(obs) e y(cal) de una impresión visual de la calidad del ajuste. Ver archivo AjusteExcel.xls Coeficiente de correlación r 2.")
3
http://www.curvefit.com/goodness_of_fit.htm
4
r 2 =0.01195 r 2 =0.95742 Con el coeficiente de correlación se evalúa el significado estadístico del ajuste usando el Student’s test.

5
Se compara el valor calculado de t con el de la tabla de t tabla, para comprobar la hipótesis que dice que la función describe los datos por azar. Si t t tabla la hipótesis es falsa. El ajuste sí es significativo. La tabla del Student’s test. Tablas estadisticas http://www.statsoft.com/textbook/sttable.html#t

6
r2r2 0.01195449 df37 t0.66907983 r2r2 0.95742213 df37 t28.8443418

7
To index t = 0.066 < t.05,37 La hipótesis es verdad. No hay correlación t = 28.8 > t.05,37 La hipótesis es falsa. Hay correlación Table of t-statistics df P = 0.05 P = 0.01 P = 0.001 112.7163.66636.61 24.309.9231.60 33.185.8412.92 42.784.608.61 52.574.036.87 62.453.715.96 72.363.55.41 82.313.365.04 92.263.254.78 102.233.174.59 202.092.853.85 302.042.753.65 402.022.73.55 1001.982.633.39 http://fsweb.berry.edu/academic/education/vbissonnette/tables/t.pdf

8
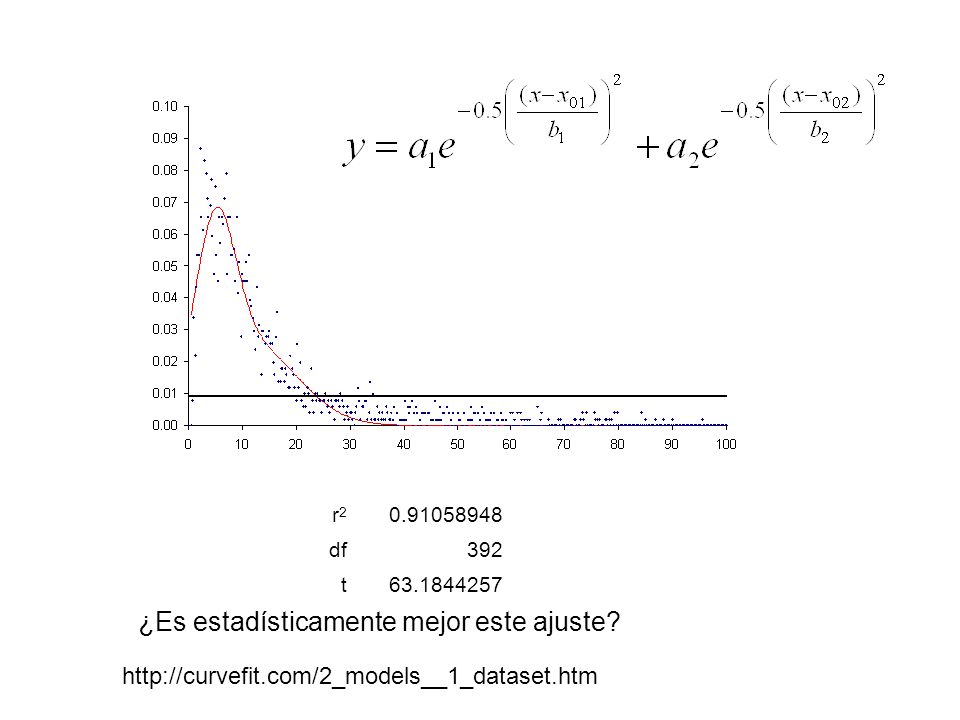
Evaluación de un ajuste al mismo set de datos usando dos modelos diferentes. Un modelo con más parámetros que el otro Ejemplos de Fabián López Modelo 1 : una curva de Gauss vs Modelo 2 suma de dos curvas de Gauss http://curvefit.com/2_models__1_dataset.htm

9
r2r2 0.88072097 df395 t54.0052101 t = 54 > t.05,395 La hipótesis es falsa. Hay correlación

10
r2r2 0.91058948 df392 t63.1844257 ¿Es estadísticamente mejor este ajuste? http://curvefit.com/2_models__1_dataset.htm
11
Al poner más parámetros la curva va a pasar más cerca de los puntos experimentales por lo tanto la suma de cuadrados de los residuos, SS, va a disminuir. El ajuste mejora si el cambio relativo de SS es mayor que el cambio relativo del número de grados de libertad. El modelo 1 (simple) tiene menos parámetros que el modelo 2 (complicado). Por lo tanto df1 > df2 y SS1 > SS2.. La razón F da una estimación cuantitativa de la mejora del ajuste Si el modelo 2 (complicado) es mejor que el modelo 1 (simple) se espera F >1 ¿Qué tanto mayor que 1 tiene que ser F para que la mejora sea significativa y no debida al azar?
 tiene menos parámetros que el modelo 2 (complicado). Por lo tanto df1 > df2 y SS1 > SS2.. La razón F da una estimación cuantitativa de la mejora del ajuste Si el modelo 2 (complicado) es mejor que el modelo 1 (simple) se espera F >1 ¿Qué tanto mayor que 1 tiene que ser F para que la mejora sea significativa y no debida al azar .")
12
Para responder esta pregunta se usa el F test. Ajuste2Ajuste1 nobs 399 npar 63 df 392395 SS 0.0119320.015936 F calculado 43.85 F Tabla 2.62 La razón F se compara con el valor de F de la tabla en que los grados de libertad de numerador son df 1 -df 2 y los del denominador df 2. El ajusten mejora si Hoja de calculo para F Ftest.xls Tablas estadísticas: http://www.ento.vt.edu/~sharov/PopEcol/tables/f005.html

13
df numerador df denominadorr Se cumple que F calculado > F tabla por lo que el ajuste es estadísticamente mejor,

14
Evaluación de un ajuste al mismo set de datos usando dos modelos diferentes. Dos modelos con el mismo número de parámetros. Ejemplo usando Solver de Excel

15
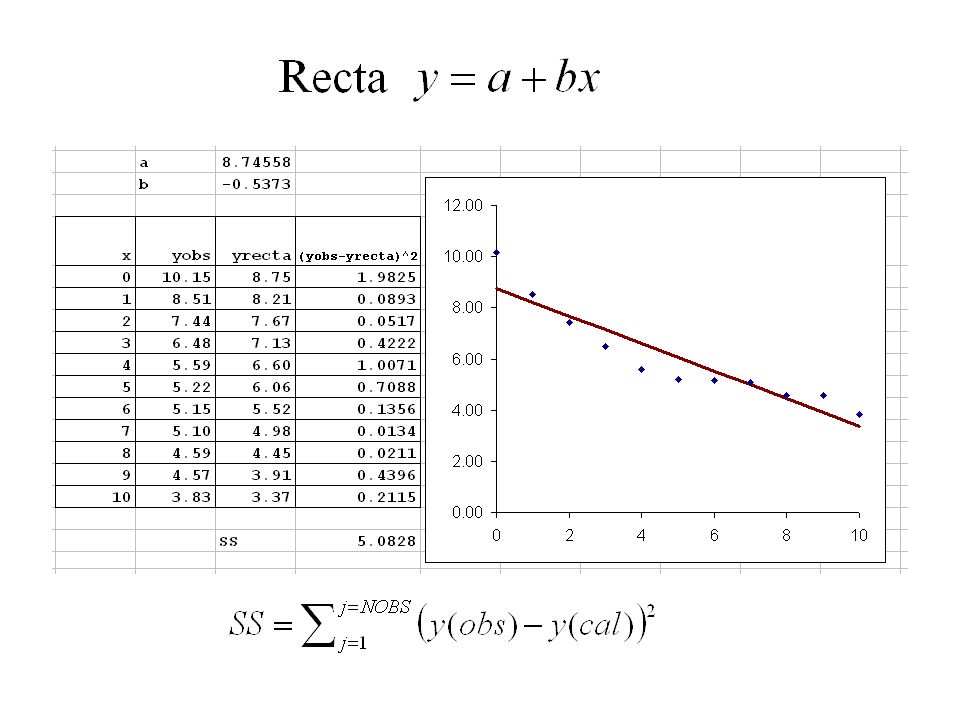
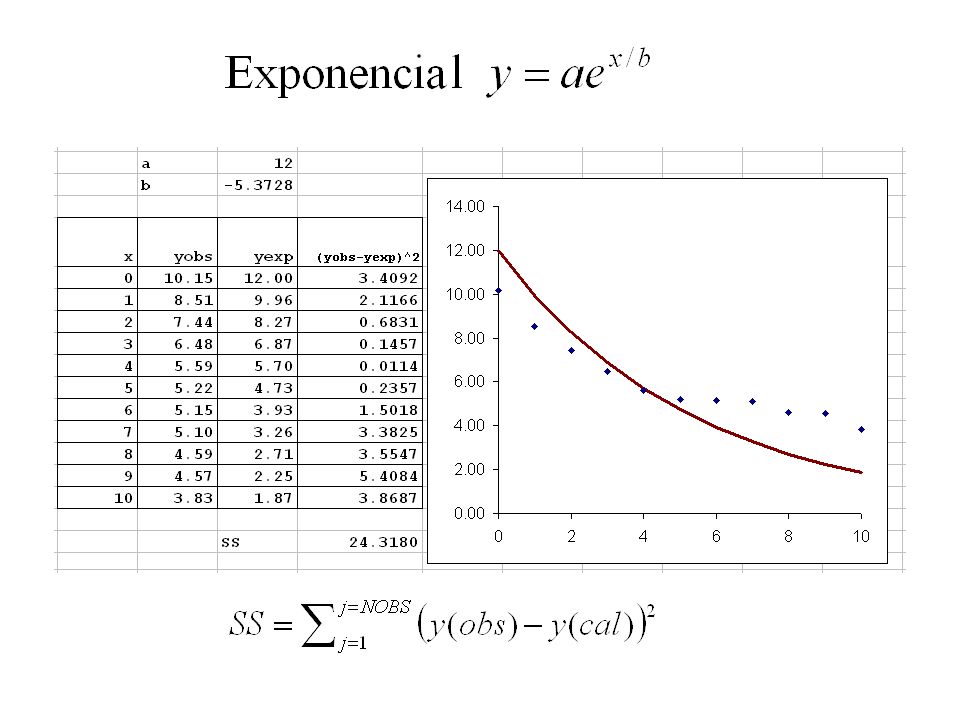
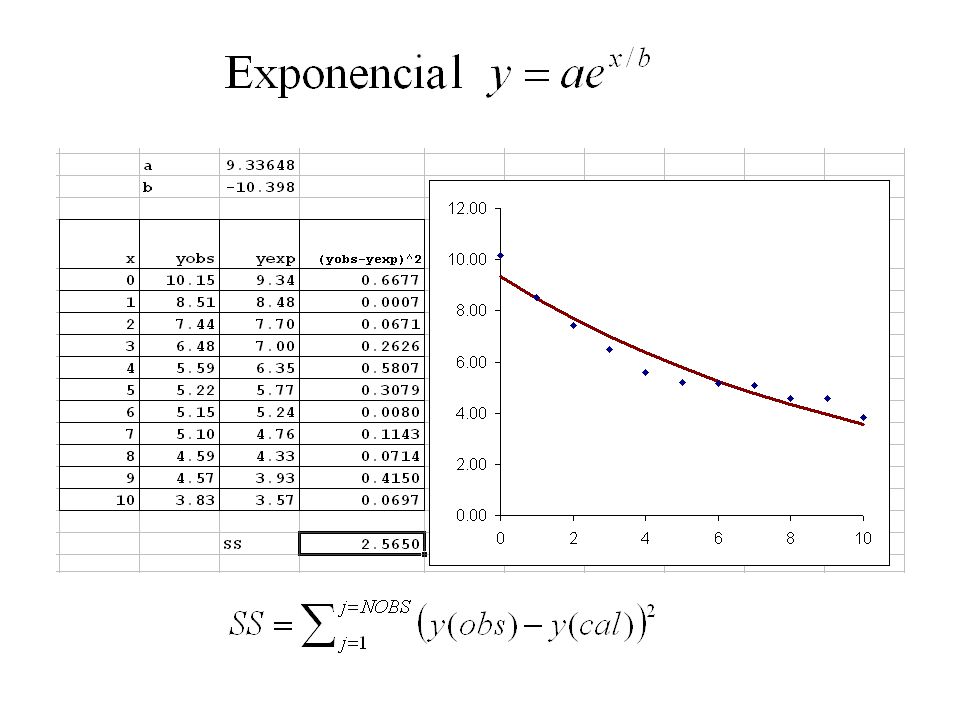
Ver archivo Recta_Exponencial.xls

20
Recta SS 1 = 5.0828 Exponencial SS 2 = 2.5650 Grados de libertaddf 1 = df2 = 8 F test para evaluar si el ajuste es mejor. F calculado es menor que el F de tabla. El ajuste exponencial no es significativamente mejor que el lineal. df numerador df denominador

21
Evaluación del cambio de los parámetros al ajustar dos set de datos usando el mismo modelo. http://curvefit.com/1_model__2_datasets.htm

22
r 2 = 0.9604 a1 0.0361 0.0052 a2 0.0274 0.0025 b1 3.3377 0.3343 b2 11.7151 1.2000 x01 4.7719 0.2148 x02 10.7239 2.4336 r2 = 0.9853 a1 0.0463 0.0036 a2 0.0261 0.0013 b1 3.6223 0.1771 b2 10.3013 0.7142 X01 4.6649 0.0881 x02 12.6866 1.3459 Valor del parámetro SE, standard error Ajuste hecho con Sigmaplot) ¿Qué parámetros son diferentes en los dos set de datos?
 ¿Qué parámetros son diferentes en los dos set de datos")
23
Para responder esta pregunta se usa el t test. Por ejemplo para el parámetro x 02 a 1 =10.7239 SE 1 = 2.4336 a 1 = 12.6866 SD 2 = 1.3459 : t = 0.70578 Cada ajuste tiene df grados de libertad Los grados de libertad del t test son df 1 + df 2. En estos casos NOBS = 399 NPAR = 6 df 1 = df 2 = 393, df = 786 Table of t-statistics dfP = 0.05P = 0.01 P = 0.001 112.7163.66636.61 24.39.9231.6 33.185.8412.92 42.784.68.61 52.574.036.87 991.982.633.39 1001.982.633.39 t calculado < t tabla, la diferencia no es significativa.

24
a1se1 a1se1 t a10.03610.0052 0.04630.0036 1.6128 a20.02740.0025 0.02610.0013 0.4614 b13.33770.3343 3.62230.1771 0.7523 b211.71511.2000 10.30130.7142 1.0124 x014.77190.2148 4.66490.0881 0.4609 x0210.72392.4336 12.68661.3459 0.7058 Todos los t calculados < t tabla.Ningún cambio es significativo.

25
a1se1 a1se1 t a10.03610.0052 0.03940.0005 0.6317 a20.02740.0025 0.02440.0003 1.1915 b13.33770.3343 3.79480.0776 1.3319 b211.71511.2000 10.61040.1482 0.9136 x014.77190.2148 4.65270.0695 0.5280 x0210.72392.4336 40.02730.1467 12.0194 t tabla = 1.98. p0.05, df = 786 El único parámetro que cambia significativamente es x 02.

26
Evauación de la independencia del los parámetros Ejemplo una curva normal Ajuste hecho con LabFit. Wilton Pereira da Silva (Brasil) wiltonps@uol.com.br www.labfit.net wiltonps@uol.com.brwww.labfit.net
")
27
THE CONVERGENCE HAPPENED IN THE ITERATION 5 C_Normal.txt N. 29: Y = A*EXP(((X-B)**2)/C) <--- Gaussian PARAMETERS: Mean UNCERTAINTIES: SD t P(t) A = 0.18648524573E+01 SIGMAA = 0.11884440790E-01 0.156915E+03 0.000 B = 0.47729148665E+01 SIGMAB = 0.15785173528E-02 0.302367E+04 0.000 C = -0.92081840012E-01 SIGMAC = 0.13570209777E-02 -0.678559E+02 0.000 Correlation Coeficient: = 0.9871693E+00 Average Absolute Residual: Sum of Absolute Residuals / Number of points => Res_av = 0.102686E+02 / 201 => Res_av = 0.510874E-01
**2)/C) <--- Gaussian PARAMETERS: Mean UNCERTAINTIES: SD t P(t) A = E+01 SIGMAA = E E B = E+01 SIGMAB = E E C = E-01 SIGMAC = E E Correlation Coeficient: = E+00 Average Absolute Residual: Sum of Absolute Residuals / Number of points => Res_av = E+02 / 201 => Res_av = E-01.")
28
COVARIANCE MATRIX 0.141240E-03 -.294458E-09 0.932009E-05 -.294458E-09 0.249172E-05 -.657955E-10 0.932009E-05 -.657955E-10 0.184151E-05 0.011884 0.001579 0.001357 Raíz cuadrada de los elementos de la diagonal SIGMAA = 0.11884440790E-01 SIGMAB = 0.15785173528E-02 SIGMAC = 0.13570209777E-02

29
COVARIANCE MATRIX A B C A 0.141240E-03 -.294458E-09 0.932009E-05 B -.294458E-09 0.249172E-05 -.657955E-10 C 0.932009E-05 -.657955E-10 0.184151E-05 Los elementos fuera de la diagonal muestran la interacción entre los parámetros. Tienen que ser menores que los elementos de la diagonal Diagnóstico: Hay interacción entre A y C. A y C no son independientes. Efectivamente, la curva normal es así : Si conoces , ya sabes el factor pre-exponencial,

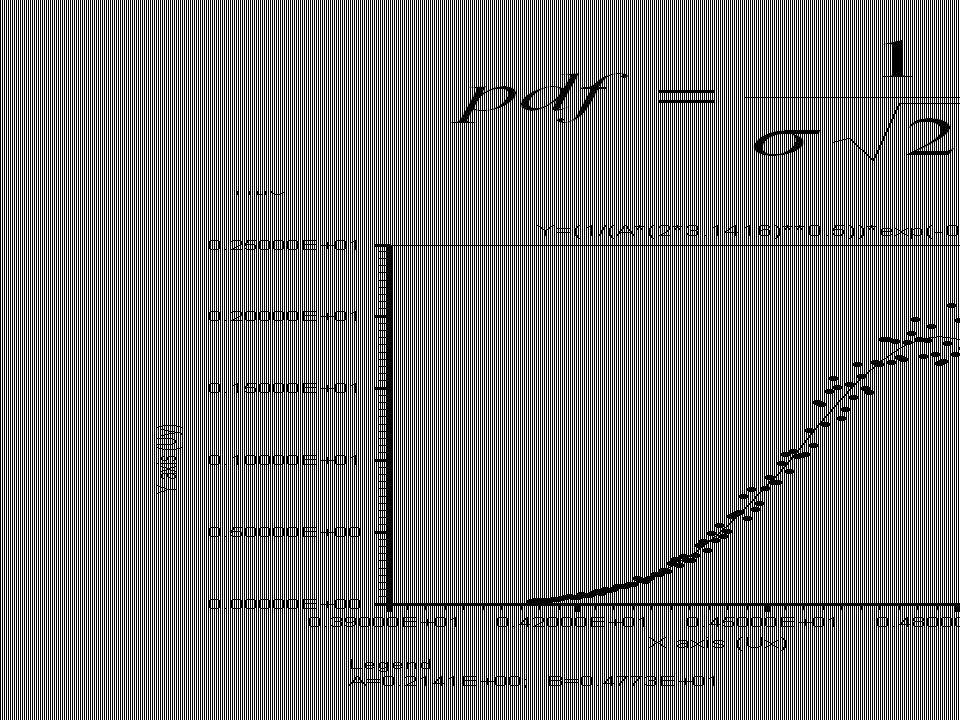
31
Y=(1/(A*(2*3.1416)**0.5))*exp(-0.5*((x-B)/A)**2) PARAMETERS: Mean UNCERTAINTIES: SD t P(t) A = 0.21414195474E+00 SIGMAA = 0.12874464101E-02 0.166331E+03 0.000 B = 0.47729149197E+01 SIGMAB = 0.15754263575E-02 0.302960E+04 0.000 Correlation Coeficient: R²yy(x) = 0.9872929E+00 adjR²yy(x) = 0.9872290E+00 Ryy(x) = 0.993626E+00 => P(NP,|R|) = 0.300E-07 Average Absolute Residual: Res_av = Sum of Absolute Residuals / Number of points => Res_av = 0.102755E+02 / 201 => Res_av = 0.511218E-01 COVARIANCE MATRIX 0.165752E-05 0.465531E-10 0.465531E-10 0.248197E-05
**0.5))*exp(-0.5*((x-B)/A)**2) PARAMETERS: Mean UNCERTAINTIES: SD t P(t) A = E+00 SIGMAA = E E B = E+01 SIGMAB = E E Correlation Coeficient: R²yy(x) = E+00 adjR²yy(x) = E+00 Ryy(x) = E+00 => P(NP,|R|) = 0.300E-07 Average Absolute Residual: Res_av = Sum of Absolute Residuals / Number of points => Res_av = E+02 / 201 => Res_av = E-01 COVARIANCE MATRIX E E E E-05")
32
¿Cuál de los dos ajuste es mejor? Ajuste2Ajuste1 nobs 201 npar 32 df 197198 SS 0.102686E+020.102755E+02 F calculado 0.132 F Tabla ? La razón F se compara con el valor de F de la tabla en que los grados de libertad de numerador son df 1 -df 2 y los del denominador df 2. El ajusten mejora si Tablas estadísticas: http://www.ento.vt.edu/~sharov/PopEcol/tables/f005.html

33
df numerador df denominadorr Se cumple que F calculado > F tabla por lo que el ajuste es estadísticamente mejor,

34
¿Cuál de los dos ajuste es mejor? Ajuste2Ajuste1 nobs 201 npar 32 df 197198 SS 0.102686E+020.102755E+02 F calculado 0.132 F Tabla 3.89 La razón F se compara con el valor de F de la tabla en que los grados de libertad de numerador son df 1 -df 2 y los del denominador df 2. El ajusten mejora si El ajuste de 3 parámetros no es mejor que el de 2 parámetros

Presentaciones similares






 a partir de los valores de x (variable.>")











.>")

