Descargar la presentación
La descarga está en progreso. Por favor, espere

1
PROGRAMA DE DOCTORADO EN SALUD PÚBLICA
Bioestadística PROGRAMA DE DOCTORADO EN SALUD PÚBLICA

2
Primera clase: Presentación del curso Stata Bases de datos de trabajo
Definition of Epidemiology, its objectives and analytic procedures Prevalence, Incidence, Odds Mortality, Lethality, Proportionate Mortality, Cause-specific mortality Rates and ratios, odds-ratios, risk-ratios or relative-risks Reality, tests and gold standards: validity and reliability Sensitivity and specificity; positive and negative predictive value Concordance and the Kappa statistic Case series and cross-sectional studies; case-control and cohort studies Prospective and retrospective studies Clinical trials, what are they? Random and systematic error. Selection and information biases Confounding?

3
PRESENTACIÓN DEL CURSO

4
Objetivo general: Presentar los fundamentos del tratamiento de datos cuantitativos en el sector salud, tanto en la practica profesional y académica, así como en la ejecución de proyectos de investigación y desarrollo

5
Capacidades a desarrollar:
Análisis exploratorio, estadística descriptiva y estimaciones de parámetros estadísticos Inferencias para datos en salud pública y epidemiología: prevalencias e incidencias, regresiones simples y múltiples, análisis de sobrevivencia, análisis longitudinal. Utilizar Stata proficientemente para realizar los análisis descritos previamente. Interpretar y transmitir correctamente resultados provenientes de estos análisis

6
Metodología: Cero fórmulas, 100% software
Integración de teoría y práctica con ejemplos y datos de la realidad local Trabajo individual con datos reales 3 controles de lectura 4 ejercicios 1 trabajo final Prueba inicial/final

7
Contactos Mirko Zimic Jefe de la Unidad de Bioinformática y Biología Computacional, Facultad de Ciencias, UPCH anexo 2604

8
Porqué STATA?

9
Porqué usamos Stata? Opciones orientadas a BIOestadística
Programa preferido en escuelas de medicina y salud pública en los EEUU y otros paises Precios accesibles: $72 y $100 por copia para licencias educativas y corporativas Pago único por uso perpetuo de todos sus módulos con actualizaciones gratuitas

10
Stata tiene, SPSS no… Manejo de incidencias, prevalencias, y razones de riesgo (regresiones para RR también) Regresión logística condicional para estudios de caso-control apareado Ajuste directo/indirecto de tasas/proporciones Cálculo de tamaño de muestra Meta-análisis

11
Amplio soporte en Perú:
Licencias y cursos en San Marcos y UPCH Utilizado por diversos grupos (NMRCD, UPCH, PRISMA, INEI, OGE, PUCP, etc.) Asesoría de bioestadísticos locales (ABE) Base de usuarios rápidamente creciente
 Asesoría de bioestadísticos locales (ABE) Base de usuarios rápidamente creciente.")
12
Resultados (.log) Historia de comandos Comandos (uno cada vez) (.do)
Variables (.dta) Resultados (.log)
 Resultados (.log)")
13
Semana 1. Introducción a los conceptos estadísticos - Definición de observables físicos. - Cuantificación y medición. - Procesos determinísticos y procesos aleatorios. - Constantes y variables aleatorias. - Tipos de variables. - Definición frecuentista de probabilidad - Distribuciones probabilísticas especiales - Distribuciones sesgadas. - Definición de parámetros y estimadores. - Definición de la Estadística Bayesiana.

14
What is Probability? Two Schools: * Frequentists * Bayesians

15
Frequentists definition of Probability
…Probability of an event is the limit of the frequency at which it occurs when the number of trials tends to infinity…

16
Probability Probability is the numerical measure of the likelihood
that the event will occur. Value is between 0 and 1. Sum of the probabilities of all mutually exclusive and collective exhaustive events is 1. 1 Certain .5 Impossible

17
Discrete Probability Distribution Example
Event: Toss 2 Coins Count # Tails. Probability distribution Values probability 0 1/4 = .25 1 2/4 = .50 2 1/4 = .25 T T T T

18
SAMPLES AND POPULATIONS: INFERENCE AND PROBABILITY
PN Inference Probability Sample S1 S2 Sn 18

19
Sometimes the frequentists definition may not be applied…
For example, under the question: What is the probability that China declares the war to the US and a world nuclear catastrophe occurs?

20
Bayesian definition of probability
…Probability can be understood as the hope or expectancy (particular belief) that the event may occur… So the answer to the last question may be any number that represents a particular belief
 that the event may occur… So the answer to the last question may be any number that represents a particular belief.")
21
The probabilistic concept produces a natural classification:
Fixed Numbers (Constants) Random Variables (unfixed, may change with a certain probability distribution)
 Random Variables (unfixed, may change with a certain probability distribution)")
22
For example, some constants are:
The speed of light in vacuum ( Km/s) Avogadro’s number Boltzmann’s constant Planck’s constant
 Avogadro’s number. Boltzmann’s constant. Planck’s constant.")
23
Some examples of random variables
The number of bacteria that grow on a plaque The number of neurons on a human brain The time that takes a flight from Chicago to Baltimore Human adult blood pressure Cholesterol level The money your wife spends monthly !!

24
A random variable has a PROBABILITY DISTRIBUTION
The probability distribution can be seen as a ‘frequency plot’ or as an ‘histogram’

25
What about your HEIGHT, is it a random variable ?
(Suppose you are in the stationary phase of growth)
")
26
What do you need to do in order to KNOW your height?
…Mmmmm, I need to MEASURE ! Remember !, MEASURING is a key concept, we will go over it later

27
Just to remind: To MEASURE is nothing else than to ‘assign’ a NUMBER to a certain characteristic of a physical observable, and for that we need to use a MEASUREMENT INSTRUMENT

28
Suppose you measure yourself several times during a week…
Will you obtain always the same value?

29
A Clarification… A RANDOM VARIABLE has a probability distribution, BUT its realization (the value obtained once it’s measured) is then a CONSTANT (fixed value)
 is then a CONSTANT (fixed value)")
30
What causes randomness?
How do we know if an observable is determined by a random variable or a constant? Remember that to ‘know’ something is equivalent to measure it several times and make predictions and inferences on it

31
Can the process of ‘measuring’ play any role in the ‘randomness’ of the observables?

32
During a measurement, the ‘instrument of measurement’ INTERACTS with the system and may PERTURBE it randomly, because the measuring conditions may not be ‘exactly’ repeated

33
Therefore, a deterministic world?
Originally, Physics, Chemistry and Biology were born in a deterministic framework.

34
Classical Physics is deterministic
According to Newton’s laws, we can ‘predict’ how a system is going to behave in the future

35
Classical Chemistry is deterministic
A + B C

36
Classical Biology is deterministic
A – T G – C

37
Consequences of a deterministic world…
Suppose we are able to ‘calculate’ the dynamics of ‘every’ molecule in the brain, and predict a future state… Then we could predict what a particular person is going to think or even do !!!

38
What are the difficulties?
The calculation is incommensurably complex, at the point that neither all the computers in the world working together at a billion times faster than they are could complete the calculations in an acceptable time (in less than several hundreds of years) At the end of the calculations, the individual is already dead
 At the end of the calculations, the individual is already dead ")
39
Is the computational power limitation the only obstacle?

40
Remember that in order to solve for the dynamics of any system, we need to ‘know’ the initial conditions How can we ‘know’ the initial conditions? Just ‘measuring them’… and after measuring, we inevitably introduce uncertainty

41
What about ‘giving’ the initial conditions instead of measuring them?
Can we then use our computational capacity to ‘predict’ how the system is going to evolve?

42
For example: What’s going on when we roll a dice?
Given the initial conditions we can calculate how the dice is going to move and thus determine which face is going to be up. The randomness of a ‘dice roll’ resides in the fact that the initial conditions during the throw are never the same for a human arm So, a finest and precise robot arm, that always ‘throw’ the dice in the SAME WAY could be designed such that ‘always’ get an ace.

43
What can we conclude about it?
So, if a robot arm can always throw an ace, what happened to the randomness of the process? What can we conclude about it?

44
The randomness is due to the variability on the initial conditions Many systems are very sensible even to extremely small variations on the initial conditions: This is called Dynamical Instability or CHAOS

45
Chaos is not always as ‘bad’ as it sounds…
Sometimes, it can really be beautiful. An example of this are the FRACTALS

46
Atan Method Fractals

47
Miscellaneous

48
Bubbles

49
3D Phoenix Spirals

50
Summarizing The ‘randomness’ of a random variable resides on:
The variability of the initial conditions The dynamical instability The perturbation suffered during a measurement

51
Important Conclusion: Determinism and Random Behavior are not actually divorced, but they are connected through the Dynamical Equations. Therefore, Random Behavior is a consequence of determinism under special conditions

52
Tipos de variables

53
Clasificación general:
Categórica Cuantitativa o numérica Nominal Ordinal Discreta Continua

54
Ejemplos: Nominales: Sexo, estado civil, presencia de morbilidad, resultado del tratamiento Ordinales: Severidad de morbilidad, riesgo quirúrgico, resistencia a antibioticos Discretas: Cociente intelectual, tiempo de tratamiento u hospitalización Contínuas: concentración de alcohol en la sangre

55
Las variables continuas
El carácter continuo de una variable lo da la naturaleza intrínseca del observable físico y es independiente de la manera cómo se mida (i.e. del instrumento utilizado) ó de la manera cómo se reporte la medición
 ó de la manera cómo se reporte la medición.")
56
Efecto de la manera ‘cómo se mide’ una variable
Imaginemos que medimos la induración del PPD en varios pacientes, y para ello utilizamos una regla milimetrada. Las dimensiones medidas para diferentes personas fueron: 5mm, 12mm, 9mm, 32mm, 21mm Aparentemente estamos frente a una variable discreta, aunque en realidad la induración (longitud) es y debe tratarse de manera continua.
 es y debe tratarse de manera continua.")
57
Efecto de la manera ‘cómo se reporta’ una variable
Imaginemos que medimos la duración de la permanencia en UCI de pacientes en un hospital. Los tiempos medidos para diferentes pacientes fueron: 15días, 2días, 9días, 12días, 31días Aparentemente estamos frente a una variable discreta, aunque en realidad el tiempo es y debe tratarse de manera continua.

58
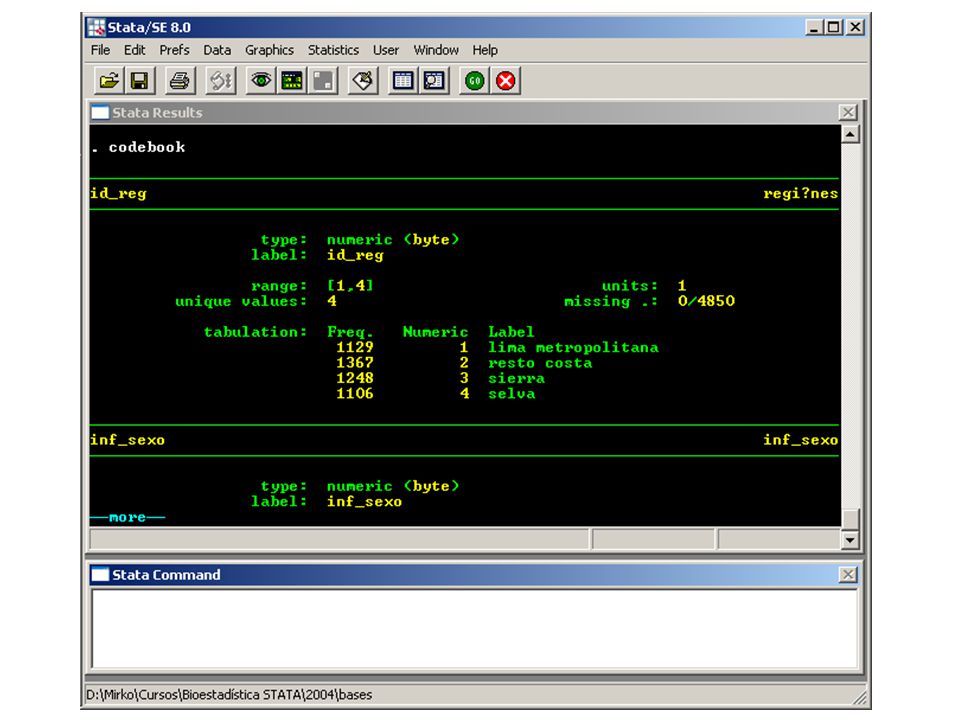
En la base de datos: id_reg Región inf_sexo Sexo inf_edad Edad
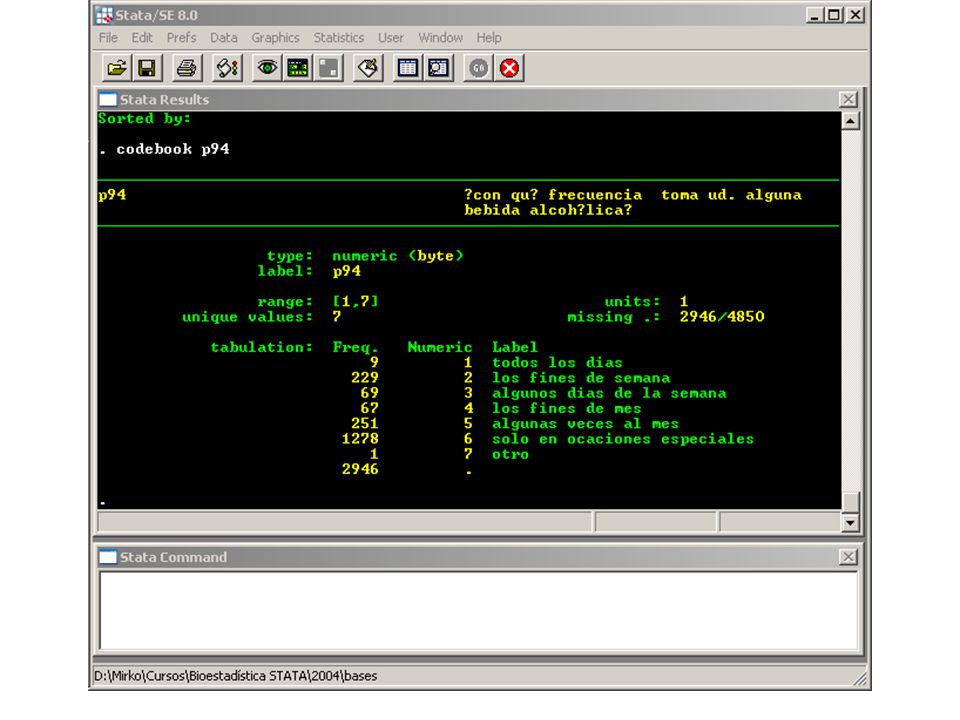
p ¿Cuál es el nivel de educación alcanzado? p En su grupo de amigos, ¿Con qué frecuencia fuma? p ¿Cuándo fue la primera vez que Ud. fumó cigarrillos? p ¿Qué edad tenía cuando fumó cigarrillos por primera vez? p Y, ¿Cuándo fue la última vez que Ud. fumó cigarrillos? p ¿Con qué frecuencia fuma Ud. cigarrillos? p Más o menos, ¿Cuántos cigarrillos al día fuma Ud.? p Más o menos, ¿Cuántos cigarrillos fumó en los últimos 30d? p ¿Cuándo fue la primera vez que Ud. bebió? p La primera vez que Ud. bebió, ¿Qué bebida tomó? p ¿A que edad Ud. bebió por primera vez? p ¿Con quién estaba Ud. la primera vez que tomó? p Y, ¿Cuándo fue la última vez que Ud. bebió? p ¿Con qué frecuencia toma Ud. alguna bebida alcohólica? arsoc2 Estrato social

59
En sus trabajos, que tipo de dato es su variable respuesta, resultado o desenlace principal?

60
Categorización/discretización:
Las variables continuas pueden ser convertida en variables discretas y hasta en categóricas En este proceso se pierde información (precisión) La información debe obtenerse al mayor nivel de precisión posible y luego agruparse si fuera necesario (discretización)
 La información debe obtenerse al mayor nivel de precisión posible y luego agruparse si fuera necesario (discretización)")
61
Definiciones especiales:
Categóricas dicotómicas o de más de dos valores Cuantitativas con distribución normal o no Discretas tipo conteo: números de casos reportados, CD4, carga viral o parasitaria Cuantitativas truncadas: ingresos, edad, peso/talla Tiempo para evento: edad de inicio del consumo (considerando a no consumidores)
")
62
DESCRIBIENDO VARIABLES DICOTOMICAS

63
Variables dicotómicas:

64
Pero, nos interesa realmente la muestra o la población?
Esta exploración es parte de un proceso de inferencia estadística Queremos extrapolar conclusiones a la población Nuestro primer objetivo es hacer una estimación a nivel de la población: Cálculo numérico de un cierto parámetro en la población En forma puntual y con intervalo de variabilidad

65
Definición frecuentista de probabilidad

66
Distribuciones probabilísticas especiales

67
Dos bases de datos hipotéticas… Es importante tener una
imagen visual de la distribución de la variable Datos de baja variabilidad La media provee una buena representación de los valores en la base de datos. Al incrementar datos la distribución cambia.. Datos con alta variabilidad La media ya NO provee ahora una buena información de los datos como sucedía anterioremente

68
Perfil de la distribución
Describe cómo los Datos están Distribuídos Caracterización del perfil de la distribución: Simétrica o sesgada

69
Recordemos las características de una variable continua con distribución normal…
Figure 10.10 6

70
Perfil de la distribución
Describe cómo los Datos están Distribuídos Caracterización del perfil de la distribución: Simétrica o sesgada Simétrica Media = Mediana = Moda

71
Gráficos ‘tallo y hoja’ comando ‘stem’ de STATA

73
How does the standard deviation affect the shape of f(x)?
How does the expected value affect the location of f(x)? m = 10 m = 11 m = 12 Bioestadística Aplicada
 m = 10. m = 11. m = 12. Bioestadística Aplicada.")
74
Fenómenos tipo Bernoulli:
Se aplican a variables dicotómicas Representan la ocurrencia o no ocurrencia de UN evento, por ejemplo: el sexo de CADA UNA de las personas encuestadas Toman solamente dos posibles valores o estados: hombre (1) o mujer (2) Solo se aplican a nivel unitario: un dato, persona u observación
 o mujer (2) Solo se aplican a nivel unitario: un dato, persona u observación.")
75
Distribución Binomial:
Es un conjunto de variables Bernoulli del mismo tipo, por ejemplo, el sexo de las 4,850 personas encuestadas La variable en estudio (sexo) tiene también dos valores (hombre/mujer), los cuales ocurren con frecuencias relativas (p) y (1-p) simétricas El valor p es la frecuencia relativa o proporción de hombres entre las personas encuestadas
 tiene también dos valores (hombre/mujer), los cuales ocurren con frecuencias relativas (p) y (1-p) simétricas. El valor p es la frecuencia relativa o proporción de hombres entre las personas encuestadas.")
76
Rápidamente:

77
Transformando sexo a 0/1:

78
n=2 n=5 n=30 n=3 n=15 n=60

79
El Teorema del Límite Central da validez a los intervalos de confianza
La media de una muestra “grande” de datos de cualquier tipo sigue una distribución normal Esto aún se cumple para datos binomiales (sexo, prevalencia, sensibilidad, etc) Qué es una muestra grande? Eso varía según cada tipo de dato (entre otras cosas) A medida que el tamaño de muestra crece, la distribución de la media muestral se hace más normal
 Qué es una muestra grande Eso varía según cada tipo de dato (entre otras cosas) A medida que el tamaño de muestra crece, la distribución de la media muestral se hace más normal.")
80
AN ILLUSTRATION OF THE CENTRAL LIMIT THEOREM
Bioestadística Aplicada 80

81
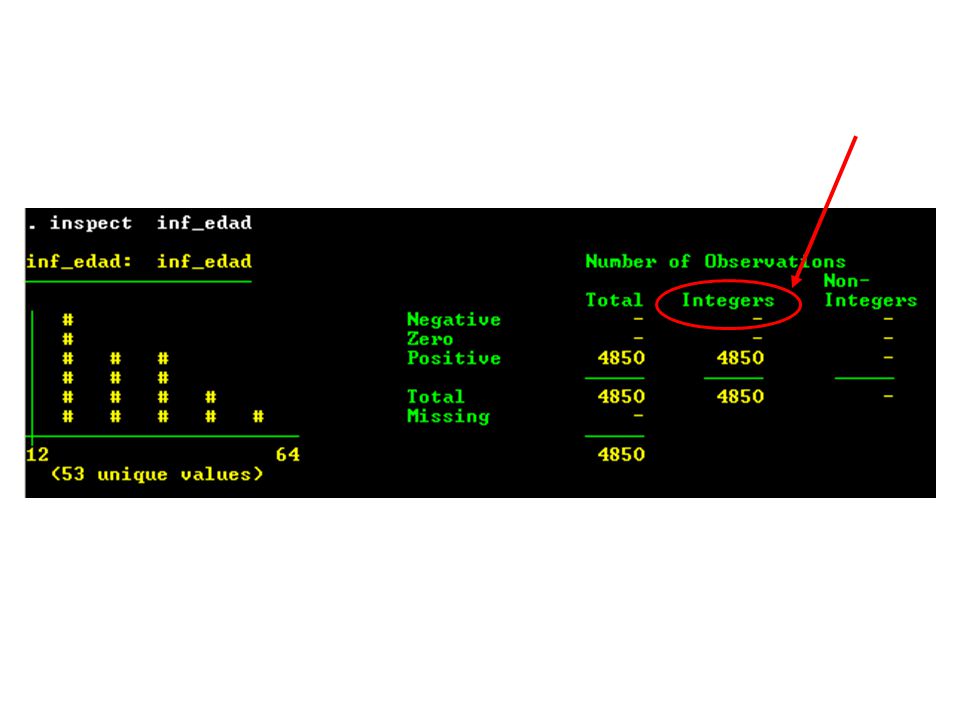
Comandos usados en STATA para identificar el tipo de variable:
Codebook Inspect

85
ATENCION ! STATA puede identificar un tipo de variable de manera erronea ! Debemos apoyarnos en la ciencia, en nuestro conocimiento previo de la variable con que estamos trabajando.

87
Continuous Models on the Line
Normal Logistic Cauchy Laplace Student Non-central Student Bioestadística Aplicada

88
Normal Distribution Mean= 0 SD = 0.5, 1, 2 Bioestadística Aplicada

89
Logistic distribution
Mean=0 SD=0.5, 1 Bioestadística Aplicada

90
Student distribution Degrees of freedom= 1,10,100
Bioestadística Aplicada

91
Laplace distribution Mean=0 SD=0.5, 1, 5 Bioestadística Aplicada

92
Continuous Models on the Half Line
Exponential Gama Chi-square Non central Chi-square F Non central F Weibull Bioestadística Aplicada

93
Exponential distribution
Scale parameter = 0.5, 1, 2 Bioestadística Aplicada

94
Chi-square distribution
Degrees of freedom = 3, 5, 10,15 Bioestadística Aplicada

95
F distribution Degrees of freedom = (3,3), (10,10), (30,30)
Bioestadística Aplicada

96
Continuous Models on a Finite Interval
Beta Uniform Bioestadística Aplicada

97
Uniform distribution P = 1/3 Bioestadística Aplicada

98
Beta distribution Parameters: (2,15), (5,15), (15,5)
Bioestadística Aplicada

99
Discrete Models Binomial Poisson Negative Binomal Uniform
Bioestadística Aplicada

100
Binomial distribution
P= 0.2, 0.5, 0.8 Bioestadística Aplicada

101
Poisson distribution Intensity parameter = 1, 3, 7
Bioestadística Aplicada

102
Negative Binomial P N Bioestadística Aplicada

103
Distribuciones sesgadas

104
Perfil de la distribución (skewness coefficient)
Describe cómo los Datos están Distribuídos Caracterización del perfil de la distribución: Simétrica o sesgada

105
Perfil de la distribución
Describe cómo los Datos están Distribuídos Caracterización del perfil de la distribución: Simétrica o sesgada Sesgada izquierda Simétrica Mean Median Mode Mean = Median = Mode

106
Perfil de la distribución
Describe cómo los Datos están Distribuídos Caracterización del perfil de la distribución: Simétrica o sesgada Sesgada izquierda Simétrica Sesgada derecha Media Mediana Moda Media = Mediana = Moda Moda Mediana Media

107
Análisis de OUTLIERS: Datos sesgados:
Valores que se exceden de 3 rangos intercuartiles por debajo del primer cuartil Q1 o por encima del tercer cuartil (Q3) (percentiles 25 y 75 respectivamente) Sesgada izquierda Sesgada Positiva outlier region outlier region Q1 Q3 Q1 Q3 Q1 – 3(Q3 – Q1) Q3 + 3(Q3 – Q1)
 (percentiles 25 y 75 respectivamente) Sesgada izquierda. Sesgada Positiva. outlier region. outlier region. Q1. Q3. Q1. Q3. Q1 – 3(Q3 – Q1) Q3 + 3(Q3 – Q1)")
Presentaciones similares



 Hacer: to make/do.>")




. When we ask what time it is in Spanish, we say “¿Qué hora es?” Some people also say “¿Qué horas son?”>")












