Descargar la presentación
La descarga está en progreso. Por favor, espere

1
I Bioinformática: una panorámica Andrés Moreira Departamento de Informática UTFSM

2
De un artículo en Nature : “El desarrollo y aplicación de herramientas computacionales para adquirir, almacenar, organizar, archivar, analizar y visualizar datos biológicos.” ¿Qué es la bioinformática?

3
Qué dice Wikipedia: “La bioinformática y la biología computacional involucran el uso de técnicas que incluyen las matemáticas aplicadas, la informática, la estadística, la inteligencia artificial, la química y la bioquímica para resolver problemas biológicos, generalmente a un nivel molecular.” ¿Qué es la bioinformática?

4
Qué dice Wikipedia: Bioinformática y biología computacional son usados casi como sinónimos. Diferencia: Bioinformática énfasis en los datos ( más cerca de la definición en Nature ) Biología computacional énfasis en las teorías, hipótesis ¿Qué es la bioinformática?
 Biología computacional énfasis en las teorías, hipótesis ¿Qué es la bioinformática .")
5
Desarrollo de algoritmos HCI Web Análisis (semi)automatizado a gran escala Testeo de hipótesis BIOLOGÍA MATEMÁTICAS INFORMÁTICA
automatizado a gran escala Testeo de hipótesis BIOLOGÍA MATEMÁTICAS INFORMÁTICA")
6
¿Qué NO es la bioinformática? Si bien existe amplio campo informático en otras áreas de la biología (por ejemplo, ecología), la palabra bioinformática se suele reservar para cosas cercanas a la biología molecular. Por otro lado... Al hablar de “biología computacional” casi podría pensarse en “mirada computacional de la biología”. Ese es otro tema, pero no tan descabellado como puede parecer a primera vista.
, la palabra bioinformática se suele reservar para cosas cercanas a la biología molecular. Por otro lado... Al hablar de biología computacional casi podría pensarse en mirada computacional de la biología . Ese es otro tema, pero no tan descabellado como puede parecer a primera vista..")
7
¿Qué NO es la bioinformática? De hecho es una perspectiva a la que a veces volveremos. “If you want to understand life, don’t think about vibrant, throbbing gels and oozes, think about information technology.” Richard Dawkins, en “The Blind Watchmaker” Así que no es sólo prestación de servicios... Es una invasión!

8
Bioinformática: lo “bio” ¿De qué está hecha la vida? Proteínas: Cadenas formadas por aminoácidos: {A, C, D, E, F, G, H, I, K, L, M, N, P, Q, R, S, T, V, W, Y} Realizan casi todos los trabajos: estructura, mensajería, catálisis, manejo de energía Ácidos nucleicos: Cadenas formadas por nucleótidos: {a, c, g, t} para DNA, {a, c, g, u} para RNA. Almacenamiento y porte de información, síntesis de proteínas.

9
Bioinformática: lo “bio”

10
augccuaguaug......ugugcaacguga å aug ccu auu aug...... ugu gca acg uga å M P S M...... C A T stop

11
Bioinformática: lo “bio”

12
RNAs tRNA

13
Bioinformática: lo “bio” Es aún más importante en las proteínas: ahí la forma básicamente determina la función. Estructura 1d, 2d, 3d (“primaria”, “secundaria”...)
.")
14
Bioinformática: lo “bio” ¿Quién decide qué se copia y se fabrica? Básicamente proteínas, pegándose a un punto apropiado en el DNA (regulación). Eso determinará qué tanto se fabrica de cada gen (el nivel de expresión). Varias proteínas pueden regular un mismo gen, y ese a su vez puede regular a otros aparecen redes de regulación.
. Eso determinará qué tanto se fabrica de cada gen (el nivel de expresión). Varias proteínas pueden regular un mismo gen, y ese a su vez puede regular a otros aparecen redes de regulación..")
15
Bioinformática: lo “bio” Los niveles de expresión: van cambiando a través del tiempo determinan el tipo de célula Los cambios en la regulación y expresión de los genes pueden ser tanto o más importantes para la evolución que los cambios en la secuencia del DNA. nivel gen 1 nivel gen 2 Un ciclo diario

16
Bioinformática: lo “bio” Una célula hace cosas: Metabolismo Comunicación Reproducción Evolución Así que se agregan fenómenos a otros niveles: de organismo multicelular, de linaje que evoluciona, etc etc

17
Bioinformática: perspectiva histórica 1953: Watson & Crick descifran la estructura del DNA En las décadas siguientes, se aprende sobre el código genético. Más tarde, se empiezan a leer genes. Desde hace un tiempo, genomas.

18
Bioinformática: perspectiva histórica Número de letras ___________________________________________________________ 1971 Se publica la primera secuencia de DNA 12 1977 PhiX174 5,375 1982 Lambda 48,502 1992 Cromosoma III de la levadura 316,613 1995 Haemophilus influenza 1,830,138 1996 Saccharomyces 12,068,000 1998 C. elegans 97,000,000 2000 D. melanogaster 120,000,000 2001 H. sapiens (borrador) 2,600,000,000 2003 H. sapiens 2,850,000,000
 2,600,000, H. sapiens 2,850,000,000.")
19
Bioinformática: perspectiva histórica Proyecto de genoma humano: Terminado el 2001 Se pensó que iba atrasado. Consorcio Público (HGP)Celera Genomics
Celera Genomics.")
20
Bioinformática: perspectiva histórica Simultáneamente, va creciendo el número de secuencias de proteínas que se conocen. Y el número de estructuras de proteínas. Y una serie de otros tipos de información. Y la cantidad de publicaciones. Bases de datos de bases de datos.

21
Bioinformática: perspectiva histórica

22
Pronto aparecieron los repositorios de información. Paralelamente, algoritmos crecientemente complejos: ensamblado de genomas detección de genes en las secuencias alineamiento de secuencias predicción de estructura 2d y/o 3d

23
Bioinformática: perspectiva histórica Además de aumentar el volumen, aumentó la complejidad: Genes escritos en trozos Genes con más de un producto Interacciones complejas de regulación Genes saltarines RNA con funciones “propias de proteínas”

24
Bioinformática: perspectiva histórica Un torrente de información que ha crecido de manera exponencial, cada vez con más matices y más complejidad. No cesan de aparecer cosas nuevas, ya sea por disponibilidad de datos o por nuevos descubrimientos: Metagenómica Epigenética Variación en la población (SNPs) interferencia de RNA (microRNA)...
 interferencia de RNA (microRNA)....")
25
Bioinformática: perspectiva histórica Se ha ido refinando y especializando el nivel de las aplicaciones computacionales: De repositorios, a bases de datos anotadas, a protocolos para interoperabilidad De hacer regresiones lineales, a construir modelos complejos vía machine learning De gráficos simples a minería de datos De revistas en papel, a textos online semánticamente anotados (y cuando no, procesamiento de lenguaje natural) Pero: Los datos nos llevan la delantera.
 Pero: Los datos nos llevan la delantera.")
26
Bioinformática: perspectiva histórica

27
Toda la biología se ha “molecularizado”, y por lo tanto, “informatizado”: la biología es hoy una “ciencia de la información” Esto afecta toda la investigación en ámbito biológico, incluyendo la agropecuaria, ecológica, etc. La biotecnología es una industria en crecimiento, y no sólo en el mundo desarrollado. Bioinformática: perspectiva histórica

28
Bioinformática: Chile Chile produce madera, salmones, productos agrícolas.... Pero incluso para el cobre la bioinformática resulta importante: Biolixiviacion : se logró aumentar la velocidad con que la bacteria Thiobacillus ferrooxidans recupera cobre a partir de desechos de la explotación primaria.

29
Problemas clásicos (siempre vigentes) Ensamblar DNA: dada una serie de fragmentos secuenciados, reconstruir el genoma completo. Una versión aún más complicada, ahora que existe la metagenómica: dada una serie de fragmentos provenientes de muchos genomas distintos, reconstruir cada uno (o por lo menos clasificar bien los fragmentos!)
.")
30
Problemas clásicos (siempre vigentes) Alineamiento de secuencias (DNA o proteínas): Encontrar la ruta más corta que pudo convertir una secuencia en otra 10 20 30 40 50 Sec. 1 KVYGYDSNIHKCVYCDNAKRLLTVKKQPFEFINIMPEKGV---FDD—EKIAELLTKLGR..::.. :: :.: :: :.:.:.... :: ::. :... Sec. 2 EIYGIPEDVAKCSGCISAIRLCFEKGYDYEIIPVLKKANNQLGFDYILEKFDECKARANM 10 20 30 40 50 60 --T—-CC-C-AGT—-TATGT-CAGGGGACACG—A-GCATGCAGA-GAC | || | || | | | ||| || | | | | |||| | AATTGCCGCC-GTCGT-T-TTCAG----CA-GTTATG—T-CAGAT--C

31
Problemas clásicos (siempre vigentes) Se detectan relaciones de parentesco, o eventualmente similitud funcional Dada una secuencia de consulta, se encuentran las más cercanas en una base de datos Alineamiento múltiple: para familias de secuencias
 Se detectan relaciones de parentesco, o eventualmente similitud funcional Dada una secuencia de consulta, se encuentran las más cercanas en una base de datos Alineamiento múltiple: para familias de secuencias")
32
Problemas clásicos (siempre vigentes) También se hace alineamiento de estructuras (para reconocer familias de proteínas)
 También se hace alineamiento de estructuras (para reconocer familias de proteínas)")
33
Problemas clásicos (siempre vigentes) Búsqueda en secuencias: Inicialmente, encontrar genes (secuencias que codifican proteínas) En el genoma humano, son el 3%. Con estadística y un poco más, se puede hacer bastante. Complicación: hay otras cosas que encontrar, y son más sutiles redes neuronales, modelos markovianos, largo etc

34
Problemas clásicos (siempre vigentes) Predicción de estructura bi- y tridimensional: No es trivial ni siquiera para RNA; para proteínas, es extremadamente difícil. Y, por otro lado, es vital (para discernir la función, relaciones de interacción, parentezcos...) Incluso una simplificación extrema es NP
 Incluso una simplificación extrema es NP.")
35
ProblemasProblemas Detección de la expresión : ¿Bajo qué circunstancias se expresa un gen? ¿Qué gen se expresa bajo una circunstancia dada? ¿Cuáles se expresan siempre juntos (o vinculados por algún patrón)? Una tipo de experimento que se ha vuelto popular: microarrays
. Una tipo de experimento que se ha vuelto popular: microarrays.")
36
DATOSINFORMACION

37
ProblemasProblemas Detección de regulación y construcción de redes: ¿Quién regula a quién? Los microarrays también pueden ayudar (como series de tiempo: se saca “la foto” en momentos distintos) Determinando las redes de regulación es posible además analizarlas: ¿Qué tan robustas son? ¿Cómo pueden evolucionar? ¿Cómo se las puede intervenir?
 Determinando las redes de regulación es posible además analizarlas: ¿Qué tan robustas son. ¿Cómo pueden evolucionar. ¿Cómo se las puede intervenir .")
38
ProblemasProblemas

39
ProblemasProblemas Se pueden aproximar los estados mediante variable booleanas (binarias): encendido o apagado El resultado será un grafo en cuyos nodos se ponen funciones lógicas. Ha sido un modelo muy productivo.

40
ProblemasProblemas

41
ProblemasProblemas Modelamiento y simulación: Dinámica celular Morfogénesis Interacción en organismos multicelulares (o entre unicelulares) Evolución...
 Evolución...")
42
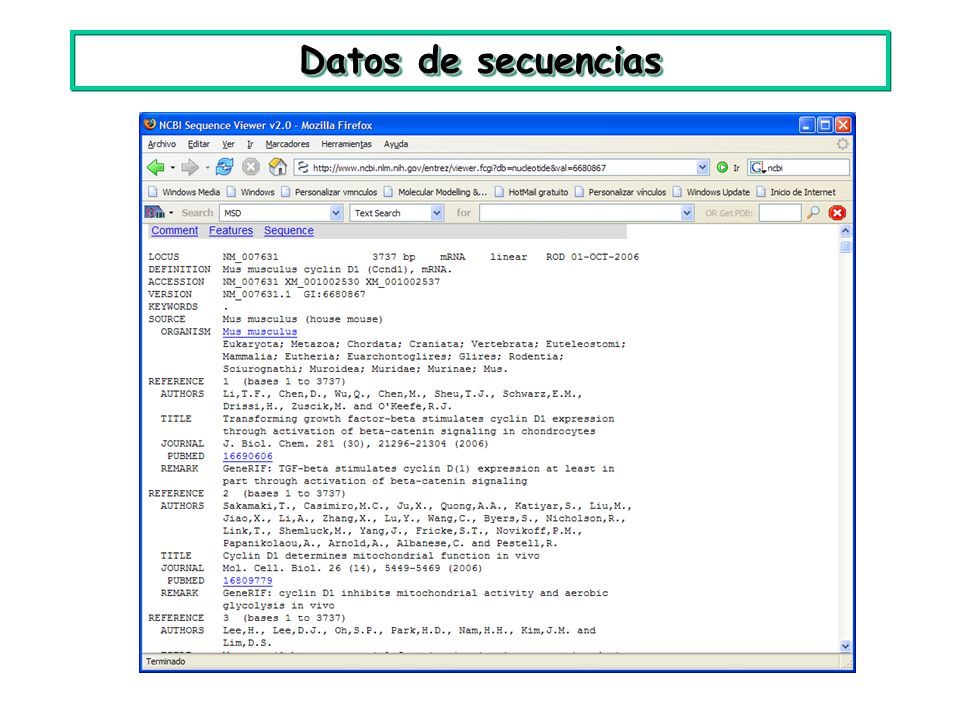
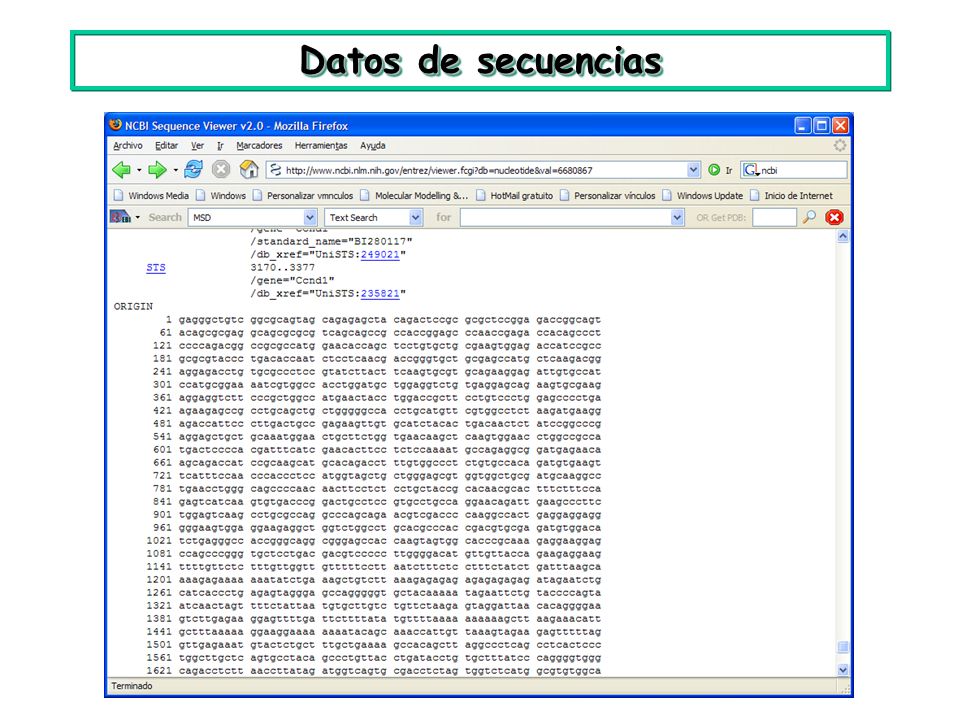
Datos de secuencias GenBank, en el National Center of Biotechnology Information, National Library of Medicine, EEUU (nucleotidos y proteinas) http://www.ncbi.nlm.nih.gov/Entrez http://www.ncbi.nlm.nih.gov/Entrez European Molecular Biology Laboratory (EMBL) Outstation en Hixton, England http://www.ebi.ac.uk/embl/index.htmlhttp://www.ebi.ac.uk/embl/index.html DNA DataBank of Japan (DDBJ) en Mishima, Japan http://www.ddbj.nig.ac.jp/ http://www.ddbj.nig.ac.jp/ Protein International Resource (PIR) en la National Biomedical Research Foundation, EEUU http://www- nbrf.georgetown.edu/pirwww/http://www- nbrf.georgetown.edu/pirwww/ SwissProt (secuencias de proteínas) Swiss Institute for Experimental Cancer Research, en Epalinges/Lausanne http://www.expasy.ch/cgi-bin/sprot-search-de http://www.expasy.ch/cgi-bin/sprot-search-de
 European Molecular Biology Laboratory (EMBL) Outstation en Hixton, England DNA DataBank of Japan (DDBJ) en Mishima, Japan Protein International Resource (PIR) en la National Biomedical Research Foundation, EEUU nbrf.georgetown.edu/pirwww/ nbrf.georgetown.edu/pirwww/ SwissProt (secuencias de proteínas) Swiss Institute for Experimental Cancer Research, en Epalinges/Lausanne")
43
Datos de secuencias

48
Datos de estructuras RCSB Protein Data Bank (PDB): www.rcsb.org BioMagResBank: http://www.bmrb.wisc.edu/ MMDB: http://www.ncbi.nlm.nih.gov/Structure/MMDB/mmdb.shtml http://www.ncbi.nlm.nih.gov/Structure/MMDB/mmdb.shtml RNA: http://www.rnabase.org/
: BioMagResBank: MMDB: RNA:")
49
Datos de estructuras: PDB

51
DatosDatos Datos... de tipos de estructuras de proteínas (SCOP, CATH, Dali, VAST) de dominios funcionales de proteínas de familias de RNAs (RNABASE) de redes de regulación genética de redes de interacción de proteínas de literatura (PubMed) de bases de datos... También bases de datos especializadas en organismos (moscas, ratón, levadura...). Y muchas más.
 de dominios funcionales de proteínas de familias de RNAs (RNABASE) de redes de regulación genética de redes de interacción de proteínas de literatura (PubMed) de bases de datos... También bases de datos especializadas en organismos (moscas, ratón, levadura...). Y muchas más..")
52
DatosDatos Niveles de expresión:

53
Cruce de datos

55
Datos: Índices

56
Datos: ejemplos >gi|1040960|gb|U35641.1|MMU35641 Mus musculus Brca1 mRNA, complete cds GGCACGAGGATCCAGCACCTCTCTTGGGGCTTCTCCGTCCTCGGCGCTTGGAAGTACGGATCTTTTTTCT CGGAGAAAAGTTCACTGGAACTGGAAGAAATGGATTTATCTGCCGTCCAAATTCAAGAAGTACAAAATGT CCTTCATGCTATGCAGAAAATCTTAGAGTGTCCGATCTGTTTGGAACTGATCAAAGAACCTGTTTCCACA AAGTGTGACCACATATTTTGCAAATTTTGTATGCTGAAACTTCTTAACCAGAAGAAAGGGCCTTCACAAT GTCCTTTGTGTAAGAATGAGATAACCAAAAGGAGCCTACAGGGAAGCACAAGGTTTAGTCAGCTTGCTGA AGAGCTGCTGAGAATAATGGCTGCTTTTGAGCTTGACACGGGAATGCAGCTTACAAATGGTTTTAGTTTT TCAAAAAAGAGAAATAATTCTTGTGAGCGTTTGAATGAGGAGGCGTCGATCATCCAGAGCGTGGGCTACC GGAACCGTGTCAGAAGGCTTCCCCAGGTCGAACCTGGAAATGCCACCTTGAAGGACAGCCTAGGTGTCCA GCTGTCTAACCTTGGAATCGTGAGATCAGTGAAGAAAAACAGGCAGACCCAACCTCGAAAGAAATCTGTC TACATTGAACTAGACTCTGATTCTTCTGAAGAGACAGTAACTAAGCCAGGTGATTGCAGTGTGAGAGACC … FASTA Un comentario, seguido por la secuencia

57
Datos: ejemplos SWISS-PROT Incluye anotación y otras informaciones (al igual que Genbank) ID BRC1_MOUSE STANDARD; PRT; 1812 AA. AC P48754; Q60957; Q60983; DT 01-FEB-1996 (Rel. 33, Created) DT 01-NOV-1997 (Rel. 35, Last sequence update) DT 16-OCT-2001 (Rel. 40, Last annotation update) DE Breast cancer type 1 susceptibility protein homolog. GN BRCA1. OS Mus musculus (Mouse). OC Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; OC Mammalia; Eutheria; Rodentia; Sciurognathi; Muridae; Murinae; Mus. OX NCBI_TaxID=10090; RN [1] RP SEQUENCE FROM N.A. RC STRAIN=C57BL/6; TISSUE=Embryo; RX MEDLINE=96177659; PubMed=8634697; RA Abel K.J., Xy J., Yin G.Y., Lyons R.H., Meisler M.H., Weber B.L.; RT "Mouse Brca1: localization sequence analysis and identification of RT evolutionarily conserved domains."; RL Hum. Mol. Genet. 4:2265-2273(1995). …
 DT 01-NOV-1997 (Rel. 35, Last sequence update) DT 16-OCT-2001 (Rel. 40, Last annotation update) DE Breast cancer type 1 susceptibility protein homolog. GN BRCA1. OS Mus musculus (Mouse). OC Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; OC Mammalia; Eutheria; Rodentia; Sciurognathi; Muridae; Murinae; Mus. OX NCBI_TaxID=10090; RN [1] RP SEQUENCE FROM N.A. RC STRAIN=C57BL/6; TISSUE=Embryo; RX MEDLINE= ; PubMed= ; RA Abel K.J., Xy J., Yin G.Y., Lyons R.H., Meisler M.H., Weber B.L.; RT Mouse Brca1: localization sequence analysis and identification of RT evolutionarily conserved domains. ; RL Hum. Mol. Genet. 4: (1995). ….")
58
Datos: ejemplos ASN.1: un estándar internacional Formato semiestructurado Es el formato base para GenBank Seq-entry ::= set { level 1, class nuc-prot, descr { title "Mus musculus Brca1 mRNA, and translated products", source { org { taxname "Mus musculus", db { { db "taxon", tag id 10090 } }, orgname { name binomial { genus "Mus", species "musculus" }, …

59
Datos: ejemplos XML MMU35641 5538 0 5 1 ROD 18-OCT-1996 25-OCT-1995 Mus musculus Brca1 mRNA, complete cds U35641 U35641.1

60
DatosDatos SBML: System Biology Markup Language, representa modelos de reacciones bioquímicas OBO: Open Biomedical Ontologies Gene Ontology: la más conocida de las ontologías biológicas; describe los genes y productos de genes de cualquier organismo

Presentaciones similares