Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Universida mariano galvez de guatemala
DISEÑO DE BASE DE DATOS Juan Carlos Rodas Ruiz Margaret Marian Paredes de la Cruz Gustavo Adolfo Alvarez Wong

2
BASE DE DATOS DISTRIBUIDA
La "base de datos distribuida" es en realidad una especie de objeto virtual, cuyas partes componentes se almacenan físicamente en varias bases de datos "reales" distintas ubicadas en diferentes sitios. De hecho, es la unión lógica de esas bases de datos. En otras palabras, cada sitio tiene sus propias bases de datos "reales" locales, sus propios usuarios locales, sus propios DBMS y programas para la administración de transacciones ( incluyendo programas de bloqueo, bitácoras, recuperación, etc ), y su propio administrador local de comunicación de datos ( administrador DC ). En particular un usuario dado puede realizar operaciones sobre los datos en su propio sitio local exactamente como si ese sitio no participara en absoluto en el sistema distribuido ( al menos, ése es uno de los objetivos ).
, y su propio administrador local de comunicación de datos ( administrador DC ). En particular un usuario dado puede realizar operaciones sobre los datos en su propio sitio local exactamente como si ese sitio no participara en absoluto en el sistema distribuido ( al menos, ése es uno de los objetivos ).")
3
Así pues, el sistema de bases de datos distribuidas puede considerarse como una especie de sociedad entre los DBMS individuales locales de todos los sitios. Un nuevo componente de software en cada sitio ( en el aspecto lógico, una extensión del DBMS local ) realiza las funciones de sociedad necesarias; y es la combinación de este nuevo componente y el DBMS ya existente lo que constituye el llamado "sistema de administración de bases de datos distribuidas" (DDBMS, distributed database management system )
 realiza las funciones de sociedad necesarias; y es la combinación de este nuevo componente y el DBMS ya existente lo que constituye el llamado sistema de administración de bases de datos distribuidas (DDBMS, distributed database management system ).")
4
Base de Datos Distribuida geográficamente dispersada

5
BASE DE DATOS DISTRIBUIDA

6
Base de Datos Distribuidas en una LAN

7
BDD sistema multiproceso

8
La razón para no considerar esta una base de datos distribuida: aún cuando la información se encuentra físicamente distribuida en diferentes procesadores, su distribución, no es relevante desde el punto de vista de la aplicación. Lo que perdemos aquí es la existencia de aplicaciones locales, en el sentido de que la integración del sistema ha alcanzado el punto donde ninguno de los computadores será capaz de ejecutar una transacción por si mismo.

9
El principio fundamental de las bases de datos distribuidas :
Desde el punto de vista del usuario, un sistema distribuido deberá ser idéntico un sistema no distribuido. En otras palabras, los usuarios de un sistema distribuido deberán comportarse exactamente como si el sistema no estuviera distribuido. Todos los problemas de los sistemas distribuidos son (o deberían ser ) internos o a nivel de realización, no externos o a nivel del usuario. Llamaremos al principio fundamental recién identificado la "regla cero" de los sistemas distribuidos. La regla cero conduce a varios objetivos o reglas secundarios - doce en realidad- siguientes :
 internos o a nivel de realización, no externos o a nivel del usuario. Llamaremos al principio fundamental recién identificado la regla cero de los sistemas distribuidos. La regla cero conduce a varios objetivos o reglas secundarios - doce en realidad- siguientes :")
10
·Autonomía local. ·No dependencia de un sitio central.
·Operación continua. ·Independencia con respecto a la localización. ·Independencia con respecto a la fragmentación. ·Independencia de réplica. ·Procesamiento distribuido de consultas. ·Manejo distribuido de transacciones. ·Independencia con respecto al equipo. ·Independencia con respecto al sistema operativo. ·Independencia con respecto a la red. ·Independencia con respecto al DBMS.

11
LAS 12 REGLAS DE CODD Determinan la fidelidad de un sistema relacional . 1º Información: La regla de la información, toda la información de la base de datos debe estar representada explícitamente en el esquema lógico. Es decir, todos los datos están en las tablas. 2º Acceso garantizado: Todo dato es accesible sabiendo el valor de su clave y el nombre de la columna o atributo que contiene el dato. 3º Tratamiento sistemático de los valores nulos: El DBMS debe permitir el tratamiento adecuado de estos valores.

12
4º Catálogo en línea basado en el modelo relacional: Los metadatos deben de ser accesibles usando un esquema relacional. 5º Sub lenguaje de datos completo: Al menos debe existir un lenguaje que permita el manejo completo de la base de datos. Este lenguaje, por lo tanto, debe permitir realizar cualquier operación. 6º Actualización de vistas: El DBMS debe encargarse de que las vistas muestren la última operación. 7º Inserciones, modificaciones y eliminaciones de dato nivel: Cualquier operación de modificación debe actuar sobre conjuntos de filas, nunca deben actuar registro a registro.

13
8º Independencia física: Los datos deben de ser accesibles desde la lógica de la base de datos aún cuando se modifique el almacenamiento. 9º Independencia lógica: Los programas no deben verse afectados por cambios en las tablas. 10º Independencia de integridad: Las reglas de integridad deben almacenarse en la base de datos (en el diccionario de datos), no en los programas de aplicación. 11º Independencia de la distribución: El sub lenguaje de datos debe permitir que sus instrucciones funcionen igualmente en una base de datos distribuida que en una que no lo es. 12º No subversión: Si el DBMS posee un lenguaje que permite el recorrido registro a registro, éste no puede utilizarse para incumplir las reglas relacionales.
, no en los programas de aplicación. 11º Independencia de la distribución: El sub lenguaje de datos debe permitir que sus instrucciones funcionen igualmente en una base de datos distribuida que en una que no lo es. 12º No subversión: Si el DBMS posee un lenguaje que permite el recorrido registro a registro, éste no puede utilizarse para incumplir las reglas relacionales.")
14
COMMIT DE DOS FASES En interconexion de computadoras y bases de datos, el protocolo commit de dos fases es un algoritmo distribuido que permite a todos los nodos de un sistema distribuido ponerse de acuerdo para hacer commit a una transaccion. El resultado del protocolo en que todos los nodos realizan commit de la transacción o abortan, incluso en el caso de fallos en la red o fallos en nodos. Sin embargo, de acuerdo con el trabajo de Dale Skeen y Michael Stonebraker, el protocolo no manejará más que el fallo de un sitio aleatorio a la vez. Las dos fases del algoritmo son la fase de petición de commit, en el cual el coordinador intenta preparar a todos los demás, y la fase commit, en la cual el coordinador completa las transacciones a todos los demás participantes.

15
El protocolo funciona de la manera siguiente: un nodo es llamado el coordinator, el cual es el site maestro, y el resto de los nodos en la red son designados los participantes. El protocolo asume que hay almacenamiento estable en cada nodo con un sistema de log write-ahead, que los nodos no están siempre caídos, que los datos en el log write-ahead nunca se han perdido o corrompido en una caída(crash), y que dos nodos cualquiera pueden comunicarse unos con los otros. La última suposición no es muy restrictiva, ya que la comunicación de redes puede ser reenrutada normalmente. Las primeras dos suposiciones son mucho más fuertes; si un nodo está totalmente destruido entonces los datos pueden perderse. El protocolo es iniciado por el Coordinador después de alcanzar el último paso de la transacción. Los Participantes entonces responden con un mensaje de acuerdo o un mensaje abortar dependiendo del éxito.

16
FASE DE PETICION DEL COMMIT
Exito 1, El coordinador envía un mensaje commit a todos los participantes. 2, Cada participante completa la operación, y libera todos los bloqueos y recursos mantenidos durante la transacción. 3, Cada participante envía un reconocimiento(ack) al coordinador. 4, El coordinador completa la transacción cuando ha recibido todos los reconocimientos. Fracaso 1, Si algún participante envió un mensaje abortar durante la fase de petición de commit: 2, El coordinador envía un mensaje rollback a todos los participantes. 3, Cada participante deshace la transacción usando el log undo(log de deshacer), y libera los recursos y bloqueos mantenidos durante la transacción. 4, Cada participante envía un reconocimiento(ack) al coordinador. 5, El Coordinador completa la transacción cuando han sido recibidos los reconocimientos.
 al coordinador. 4, El coordinador completa la transacción cuando ha recibido todos los reconocimientos. Fracaso. 1, Si algún participante envió un mensaje abortar durante la fase de petición de commit: 2, El coordinador envía un mensaje rollback a todos los participantes. 3, Cada participante deshace la transacción usando el log undo(log de deshacer), y libera los recursos y bloqueos mantenidos durante la transacción. 4, Cada participante envía un reconocimiento(ack) al coordinador. 5, El Coordinador completa la transacción cuando han sido recibidos los reconocimientos.")
17
DESVENTAJAS La mayor desventaja del protocolo commit en dos fases es el hecho de que es un protocolo bloqueante. Un nodo estará bloqueado mientras esté esperando un mensaje. Esto significa que otros procesos compiten por los bloqueos de recursos mantenidos por los procesos bloqueados tendrán que esperar a que los bloqueos sean liberados. Un nodo individual continuará incluso si otros sites han fallado. Si el coordinador falla permanentemente, algunos participantes nunca resolverán sus transacciones. Esto tiene el efecto de que los recursos están siempre comprometidos.

18
EJEMPLO

19
CONSISTENCIA Y DIVERGENCIA
La consistencia es una propiedad que asegura que una transacción no romperá con la integridad de una base de datos, pues respeta todas las reglas y directrices de ésta. Una base de datos está en un estado consistente si obedece todas las restricciones de integridad (significa que cuando un registro en una tabla haga referencia a un registro en otra tabla, el registro correspondientes debe existir) definidas sobre ella. La convergencia de los datos significa que todos los elementos que participen en las replicaciones deben tener el mismo juego de datos, que no es necesariamente el que se obtendría si todas las replicaciones se hubieran desarrollado sobre el mismo servidor.
 definidas sobre ella. La convergencia de los datos significa que todos los elementos que participen en las replicaciones deben tener el mismo juego de datos, que no es necesariamente el que se obtendría si todas las replicaciones se hubieran desarrollado sobre el mismo servidor.")
20
DISTRIBUCION DE LOS DATOS
Un sistema distribuido se define como una colección de computadores autónomos conectados por una red, y con el software distribuido adecuado para que el sistema sea visto por los usuarios como una única entidad capaz de proporcionar facilidades de computación. [ Colouris 1994 ] El desarrollo de los sistemas distribuidos vino de la mano de las redes locales de alta velocidad a principios de Mas recientemente, la disponibilidad de computadoras personales de altas prestaciones, estaciones de trabajo y ordenadores servidores ha resultado en un mayor desplazamiento hacia los sistemas distribuidos en detrimento de los ordenadores centralizados multiusuario. Esta tendencia se ha acelerado por el desarrollo de software para sistemas distribuidos, diseñado para soportar el desarrollo de aplicaciones distribuidas. Este software permite a los ordenadores coordinar sus actividades y compartir los recursos del sistema - hardware, software y datos. Los sistemas distribuidos se implementan en diversas plataformas hardware, desde unas pocas estaciones de trabajo conectadas por una red de área local, hasta Internet, una colección de redes de área local y de área extensa interconectados, que en lazan millones de ordenadores.

21
CARACTERISTICAS CLAVE DE LOS SISTEMAS DISTRIBUIDOS
Características clave de los sistemas distribuidos [Colouris 1994] establece que son seis las características principales responsables de la utilidad de los sistemas distribuidos. Se trata de comparición re recursos, apertura (openness), concurrencia, escalabilidad, tolerancia a fallos y transparencia. En las siguientes líneas trataremos de abordar cada una de ellas. Compartición de Recursos El término 'recurso' es bastante abstracto, pero es el que mejor caracteriza el abanico de entidades que pueden compartirse en un sistema distribuido. El abanico se extiende desde componentes hardware como discos e impresoras hasta elementos software como ficheros, ventanas, bases de datos y otros objetos de datos.
, concurrencia, escalabilidad, tolerancia a fallos y transparencia. En las siguientes líneas trataremos de abordar cada una de ellas. Compartición de Recursos. El término recurso es bastante abstracto, pero es el que mejor caracteriza el abanico de entidades que pueden compartirse en un sistema distribuido. El abanico se extiende desde componentes hardware como discos e impresoras hasta elementos software como ficheros, ventanas, bases de datos y otros objetos de datos.")
22
Los recursos en un sistema distribuido están físicamente encapsulados en una de las computadoras y sólo pueden ser accedidos por otras computadoras mediante las comunicaciones (la red). Para que la compartición de recursos sea efectiva, ésta debe ser manejada por un programa que ofrezca un interfaz de comunicación permitiendo que el recurso sea accedido, manipulado y actualizado de una manera fiable y consistente. Surge el término genérico de gestor de recursos. Un gestor de recursos es un modulo software que maneja un conjunto de recursos de un tipo en particular. Cada tipo de recurso requiere algunas políticas y métodos específicos junto con requisitos comunes para todos ellos. Éstos incluyen la provisión de un esquema de nombres para cada clase de recurso, permitir que los recursos individuales sean accedidos desde cualquier localización; la traslación de nombre de recurso a direcciones de comunicación y la coordinación de los accesos concurrentes que cambian el estado de los recursos compartidos para mantener la consistencia.

23
Apertura (opennesss) Un sistema informático es abierto si el sistema puede ser extendido de diversas maneras. Un sistema puede ser abierto o cerrado con respecto a extensiones hardware (añadir periféricos, memoria o interfaces de comunicación, etc... ) o con respecto a las extensiones software ( añadir características al sistema operativo, protocolos de comunicación y servicios de compartición de recursos, etc... ). La apertura de los sistemas distribuidos se determina primariamente por el grado hacia el que nuevos servicios de compartición de recursos se pueden añadir sin perjudicar ni duplicar a los ya existentes.
 o con respecto a las extensiones software ( añadir características al sistema operativo, protocolos de comunicación y servicios de compartición de recursos, etc... ). La apertura de los sistemas distribuidos se determina primariamente por el grado hacia el que nuevos servicios de compartición de recursos se pueden añadir sin perjudicar ni duplicar a los ya existentes.")
24
Concurrencia Cuando existen varios procesos en una única maquina decimos que se están ejecutando concurrentemente. Si el ordenador esta equipado con un único procesador central, la concurrencia tiene lugar entrelazando la ejecución de los distintos procesos. Si la computadora tiene N procesadores, entonces se pueden estar ejecutando estrictamente a la vez hasta N procesos. En los sistemas distribuidos hay muchas maquinas, cada una con uno o mas procesadores centrales. Es decir, si hay M ordenadores en un sistema distribuido con un procesador central cada una entonces hasta M procesos estar ejecutándose en paralelo. En un sistema distribuido que esta basado en el modelo de compartición de recursos, la posibilidad de ejecución paralela ocurre por dos razones: 1, Muchos usuarios interactuan simultáneamente con programas de aplicación. 2, Muchos procesos servidores se ejecutan concurrentemente, cada uno respondiendo a diferentes peticiones de los procesos clientes. El caso (1) es menos conflictivo, ya que normalmente las aplicaciones de interacción se ejecutan aisladamente en la estación de trabajo del usuario y no entran en conflicto con las aplicaciones ejecutadas en las estaciones de trabajo de otros usuarios. El caso (2) surge debido a la existencia de uno o mas procesos servidores para cada tipo de recurso. Estos procesos se ejecutan en distintas maquinas, de manera que se están ejecutando en paralelo diversos servidores, junto con diversos programas de aplicación.
 es menos conflictivo, ya que normalmente las aplicaciones de interacción se ejecutan aisladamente en la estación de trabajo del usuario y no entran en conflicto con las aplicaciones ejecutadas en las estaciones de trabajo de otros usuarios. El caso (2) surge debido a la existencia de uno o mas procesos servidores para cada tipo de recurso. Estos procesos se ejecutan en distintas maquinas, de manera que se están ejecutando en paralelo diversos servidores, junto con diversos programas de aplicación.")
25
Escalabilidad Los sistemas distribuidos operan de manera efectiva y eficiente a muchas escalas diferentes. La escala más pequeña consiste en dos estaciones de trabajo y un servidor de ficheros, mientras que un sistema distribuido construido alrededor de una red de área local simple podría contener varios cientos de estaciones de trabajo, varios servidores de ficheros, servidores de impresión y otros servidores de propósito especifico. A menudo se conectan varias redes de área local para formar internetworks, y éstas podrían contener muchos miles de ordenadores que forman un único sistema distribuido, permitiendo que los recursos sean compartidos entre todos ellos.

26
Tolerancia a Fallos Los sistemas informáticos a veces fallan. Cuando se producen fallos en el software o en el hardware, los programas podrían producir resultados incorrectos o podrían pararse antes de terminar la computación que estaban realizando. El diseño de sistemas tolerantes a fallos se basa en dos cuestiones, complementarias entre sí: Redundancia hardware (uso de componentes redundantes) y recuperación del software (diseño de programas que sean capaces de recuperarse de los fallos). En los sistemas distribuidos la redundancia puede plantearse en un grano mas fino que el hardware, pueden replicarse los servidores individuales que son esenciales para la operación continuada de aplicaciones criticas. La recuperación del software tiene relación con el diseño de software que sea capaz de recuperar (roll-back) el estado de los datos permanentes antes de que se produjera el fallo.
 y recuperación del software (diseño de programas que sean capaces de recuperarse de los fallos). En los sistemas distribuidos la redundancia puede plantearse en un grano mas fino que el hardware, pueden replicarse los servidores individuales que son esenciales para la operación continuada de aplicaciones criticas. La recuperación del software tiene relación con el diseño de software que sea capaz de recuperar (roll-back) el estado de los datos permanentes antes de que se produjera el fallo.")
27
Transparencia La transparencia se define como la ocultación al usuario y al programador de aplicaciones de la separación de los componentes de un sistema distribuido, de manera que el sistema se percibe como un todo, en vez de una colección de componentes independientes. La transparencia ejerce una gran influencia en el diseño del software de sistema. Hay 8 tipos de transparencia, son los siguientes: Transparencia de Acceso : Permite el acceso a los objetos de información remotos de la misma forma que a los objetos de información locales. Transparencia de Localización: Permite el acceso a los objetos de información sin conocimiento de su localización Transparencia de Concurrencia: Permite que varios procesos operen concurrentemente utilizando objetos de información compartidos y de forma que no exista interferencia entre ellos. Transparencia de Replicación: Permite utilizar múltiples instancias de los objetos de información para incrementar la fiabilidad y las prestaciones sin que los usuarios o los programas de aplicación tengan por que conoces la existencia de las replicas. Transparencia de Fallos: Permite a los usuarios y programas de aplicación completar sus tareas a pesar de la ocurrencia de fallos en el hardware o en el software. Transparencia de Migración: Permite el movimiento de objetos de información dentro de un sistema sin afectar a los usuarios o a los programas de aplicación. Transparencia de Prestaciones. Permite que el sistema sea reconfigurado para mejorar las prestaciones mientras la carga varia. Transparencia de Escalado: Permite la expansión del sistema y de las aplicaciones sin cambiar la estructura del sistema o los algoritmos de la aplicación. Las dos mas importantes son las transparencias de acceso y de localización; su presencia o ausencia afecta fuertemente a la utilización de los recursos distribuidos.

28
Fragmentación La fragmentación de una base de datos consiste en descomponer en partes los datos, siguiendo algún patrón conveniente y relacionado con la forma como estos serán alimentados y explotados. Tipos primitivos de fragmentación: Horizontal Vertical * Ambos tipos pueden ser mezclados.

29
Ventajas de la Fragmentación
La fragmentación es necesaria por razones de rendimiento. Los usuarios deben comportarse como si los datos no estuvieran fragmentados Los datos pueden estar almacenados en la ubicación donde son usados más frecuentemente para que la mayoría de las operaciones sean locales y se reduzca el tráfico de la Red. La fragmentación de datos puede ser beneficiosa en el entorno OLTP

30
TIPOS DE FRAGMENTACION

31
Ventajas de la fragmentación
Horizontal permite el procesamiento paralelo de una relación permite que una tabla global pueda estar donde se utiliza mas frecuentemente Vertical permite que una tabla pueda ser distribuida en función del uso de sus atributos. permite descomposiciones adicionales que se pueden conseguir con normalización. el atributo especial facilita la mezcla de fragmentos verticales

32
REPLICACION Transporte de datos entre dos o más servidores.
Permite que ciertos datos de la base de datos sean almacenados en más de un sitio. VENTAJAS Aumenta la disponibilidad de datos. Mejora rendimiento de las consultas.

33
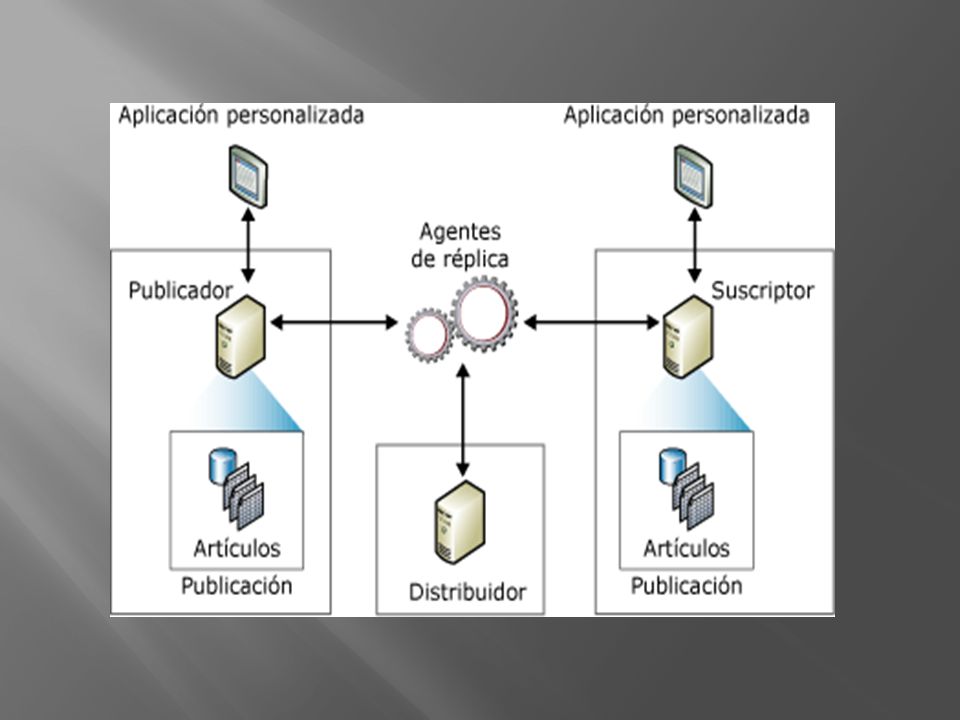
FORMADO POR: OBJETOS: AGENTES: Publicador. Distribuidor. Suscriptor.
Publicación. Artículo. Suscripción. AGENTES: Agente de instantáneas. Agente de distribución. Agente del lector del registro. Agente del lector de cola. Agente de mezcla.

34
Publicador: Servidor que pone los datos a disposición de otros servidores.
Distribuidor: Servidor que aloja la base de datos de distribución y almacena los datos históricos, transacciones y metadatos a replicar. Suscriptor: Servidor que recibe los datos replicados. Publicación: Conjunto de artículos de una base de datos que se ponen a disposición de la replicación por parte de los publicadores. Artículo: Un artículo de una publicación puede ser una vista o una tabla de datos la cual puede contar con todas las filas o algunas (filtrado horizontal) y simultáneamente contar de todas las columnas o algunas (filtrado vertical). Suscripción: Petición de copia de datos o de objetos de base de datos para replicar. Agentes de replicación: Procesos encargados de la copia de datos entre el publicador y el suscriptor.
 y simultáneamente contar de todas las columnas o algunas (filtrado vertical). Suscripción: Petición de copia de datos o de objetos de base de datos para replicar. Agentes de replicación: Procesos encargados de la copia de datos entre el publicador y el suscriptor.")
36
TIPOS DE REPLICACION Instantánea Transaccional Mezcla

37
EJEMPLO DE REPLICACIÓN

Presentaciones similares

 El Sistema de Gestión>")

















