Descargar la presentación
La descarga está en progreso. Por favor, espere

1
I A 5. Inferencia e Incertidumbre Jorge Cabrera Gámez
Departamento de Informática y Sistemas Universidad de Las Palmas de Gran Canaria © Todos los derechos reservados

2
Contenidos 5. Inferencia e Incertidumbre. (10 horas)
5.1 Modelo Bayesiano 5.2 Factores de certeza en sistemas basados en reglas. 5.3 Inferencia en redes probabilísticas. 5.4 Introducción a la Lógica Borrosa. 5.5 Bibliografía básica: [Rich-91], [Gonz-93]. 2

3
Objetivos: Evidenciar la necesidad de obtener métodos de
tratamiento de la incertidumbre. Conocer algunas de las soluciones clásicas al problema de la incertidumbre. 3

4
Incertidumbre Incertidumbre debida al “azar”:
El mundo no siempre es predecible Incertidumbre debida a desconocimiento: El modelo no describe perfectamente “el mundo” 4

5
El enfoque Bayesiano Toda medida de probabilidad sobre un evento xi debe cumplir: 1. La probabilidad de cualquier evento xi 0, 1 2. La probabilidad total sobre todo el conjunto de eventos posibles es 1 3. Si los eventos x1,x2 , ..., xk son mutuamente exclusivos, entonces la probabilidad de que al menos uno de estos eventos se verifique es igual a la suma de las probabilidades individuales. 5

6
siempre que p(x) no sea cero. De manera similar,
Dados dos eventos x e y, nos preguntamos por la probabilidad con la que ambos eventos pueden verificarse simultáneamente (Probabilidad condicionada p(y|x)). Por definición: siempre que p(x) no sea cero. De manera similar, pero como p(x y) = p(y x), despejando de la expresión anterior, y sustituyendo más arriba tenemos, que es el teorema de Bayes 6
). Por definición: siempre que p(x) no sea cero. De manera similar, pero como p(x y) = p(y x), despejando de la expresión anterior, y sustituyendo más arriba tenemos, que es el teorema de Bayes. 6.")
7
es posible obtener la expresión,
Si conocemos las probabilidades condicionadas de un evento dado cualquier otro evento, es intuitivo que la probabilidad del primer evento independientemente de lo que ocurra con el segundo es: Como sabemos que, es posible obtener la expresión, y sustituyendo más arriba tenemos, Si sustituimos en la expresión anterior del teorema de Bayes tenemos: 7

8
Probabilidad y el Teorema de Bayes
Estadística Bayesiana Noción fundamental: Probabilidad condicionada p(hi|e): Probabilidad de la hipótesis hi si se presenta la evidencia e. Para calcular esta probabilidad necesitamos conocer: La probabilidad a priori de hi, p(hi): la probabilidad que se asignaría a hi si no se tiene ninguna otra evidencia. La probabilidad p(e|hi): con que se verifica la evidencia e cuando se verifica la hipótesis hi Teorema de Bayes: donde k es el número de posibles hipótesis. 8
: Probabilidad de la hipótesis hi si se presenta la evidencia e. Para calcular esta probabilidad necesitamos conocer: La probabilidad a priori de hi, p(hi): la probabilidad que se asignaría a hi si no se tiene ninguna otra evidencia. La probabilidad p(e|hi): con que se verifica la evidencia e cuando se verifica la hipótesis hi. Teorema de Bayes: donde k es el número de posibles hipótesis. 8.")
9
THEN se concluye Y con probabilidad P
Ejemplo: IF X s cierto THEN se concluye Y con probabilidad P IF el paciente tiene gripe THEN al paciente le gotea la nariz con probabilidad 0.75 Supongamos que observamos que al paciente le gotea la nariz, ¿cuál es la probabilidad de que tenga gripe? p(h) = p(tener gripe) = 0.2 p(e|h) = p(goteo nasal | tener gripe) = 0.75 p(e|¬h) = p(goteo nasal | no tener gripe) = 0.2 p(e) = p(goteo nasal) = p(e|h)*p(h) + p(e|¬h)*p(¬h) = = 0.75* *0.8 = 0.31 9
 = p(tener gripe) = 0.2. p(e|h) = p(goteo nasal | tener gripe) = p(e|¬h) = p(goteo nasal | no tener gripe) = 0.2. p(e) = p(goteo nasal) = p(e|h)*p(h) + p(e|¬h)*p(¬h) = = 0.75* *0.8 =")
10
p(h|¬e) = p(tener gripe| no goteo nasal)
Ejemplo: Podríamos incluso calcular la probabilidad con la que se puede tener gripe sin que gotee la nariz. p(h|¬e) = p(tener gripe| no goteo nasal) p(h) = p(tener gripe) = 0.2 p(e|h) = p(goteo nasal | tener gripe) = 0.75 p(e|¬h) = p(goteo nasal | no tener gripe) = 0.2 p(e) = p(goteo nasal) = p(e|h)*p(h) + p(e|¬h)*p(¬h) = = 0.75* *0.8 = 0.31 10
 = p(tener gripe| no goteo nasal) p(h) = p(tener gripe) = 0.2. p(e|h) = p(goteo nasal | tener gripe) = p(e|¬h) = p(goteo nasal | no tener gripe) = 0.2. p(e) = p(goteo nasal) = p(e|h)*p(h) + p(e|¬h)*p(¬h) = = 0.75* *0.8 =")
11
Propagación de la Incertidumbre en un esquema Bayesiano
El esquema presentado hasta ahora es muy limitado, pues se restringe a una única evidencia que afecta a una única hipótesis. Este esquema puede extenderse para considerar m hipótesis y n evidencias. Debe notarse que esta expresión es válida sólo si las evidencias Ei pueden considerarse independientes. 11

12
Probabilidades a priori y condicionadas gripe alergia fotosensibilidad
Ejemplo: Probabilidades a priori y condicionadas gripe alergia fotosensibilidad (i=1) (i=2) (i=3) p(Hi) p(E1|Hi) p(E2|Hi) Hipótesis destilación tos E1 : al paciente le gotea la nariz E2 : el paciente tose Evidencias 12
 (i=2) (i=3) p(Hi) p(E1|Hi) p(E2|Hi) Hipótesis. destilación. tos. E1 : al paciente le gotea la nariz. E2 : el paciente tose. Evidencias. 12.")
13
Factores de certeza en reglas
El conocimiento en SBRs que emplean factores de certeza se expresa de acuerdo con el siguiente formato: SI Evidencia ENTONCES Hipótesis (CF) donde Evidencia es uno o más hechos que soportan la conclusión representada por Hipótesis. El factor de certeza o CF representa numéricamente la medida en que la Hipótesis se puede concluir de la Evidencia. Normalmente CF [-1, 1] 13
 donde Evidencia es uno o más hechos que soportan la conclusión representada por Hipótesis. El factor de certeza o CF representa numéricamente la medida en que la Hipótesis se puede concluir de la Evidencia. Normalmente CF [-1, 1] 13.")
14
Factores de certeza en reglas
La inferencia mediante Factores de Certeza (CF) hace uso de tres medidas diferentes: 1. La medida de Credibilidad, MB(h,e), que es un valor entre 0 y 1 que representa el grado con que la observación de la evidencia e soporta la credibilidad de la hipótesis h. Puede definirse “ad hoc” o emplear la siguiente definición: 2. La medida de incredulidad, MD(h,e), que es un valor entre 0 y 1 que representa el grado con que la observación de la evidencia e soporta la incredulidad en la hipótesis h. Puede definirse “ad hoc” o emplear la siguiente definición: 14
 hace uso de tres medidas diferentes: 1. La medida de Credibilidad, MB(h,e), que es un valor entre 0 y 1 que representa el grado con que la observación de la evidencia e soporta la credibilidad de la hipótesis h. Puede definirse ad hoc o emplear la siguiente definición: 2. La medida de incredulidad, MD(h,e), que es un valor entre 0 y 1 que representa el grado con que la observación de la evidencia e soporta la incredulidad en la hipótesis h. Puede definirse ad hoc o emplear la siguiente definición: 14.")
15
Factores de certeza en reglas
3. El factor de certeza, CF, que es un valor entre -1 (negación de la hipótesis h) y 1 (confirmación de la hipótesis). Este valor se obtiene como: Una evidencia sólo puede confirmar o negar una hipótesis. Por ello es suficiente un único número para definir tanto MB como MD y, por tanto, CF. 15
 y 1 (confirmación de la hipótesis). Este valor se obtiene como: Una evidencia sólo puede confirmar o negar una hipótesis. Por ello es suficiente un único número para definir tanto MB como MD y, por tanto, CF. 15.")
16
Propagación de los factores de certeza
Durante la ejecución, múltiples reglas podrá activarse que concluyan en la misma hipótesis o conclusión y será necesario actualizar el factor de certeza asociado. 16

17
Incertidumbre en las evidencias
La expresión anterior para la propagación de la incertidumbre asume que se tiene una absoluta confianza en la validez de las premisas o evidencias empleadas para obtener estos valores. REGLA 1 SI A ENTONCES Q (CF=0.75) REGLA 2 SI B AND C AND D ENTONCES Q (CF=0.7) REGLA 3 SI E OR F OR G CF(A)*CF Min(CF(A),CF(B),CF(C))*CF Max(CF(E),CF(F),CF(G))*CF 17
 REGLA 2 SI B AND C AND D. ENTONCES Q (CF=0.7) REGLA 3 SI E OR F OR G. CF(A)*CF. Min(CF(A),CF(B),CF(C))*CF. Max(CF(E),CF(F),CF(G))*CF. 17.")
18
REGLA 1: Si las huellas del inculpado están en el arma del crimen
Ejemplo: REGLA 1: Si las huellas del inculpado están en el arma del crimen Entonces el inculpado es culpable (Cfcon1=0.75) La seguridad de que las huellas pertenecen al inculpado es muy grande, Así CFevid1 = 0.9. La certeza asociada a la conclusión de la regla es entonces: CFcomb1 = CFcon1 * CFevid1 = 0.75 * 0.90 = 0.675 La siguiente evidencia la aporta un testigo (la suegra del inculpado) que asegura que éste tenía un motivo para el crimen. REGLA 2: Si el inculpado tenía un motivo Entonces el inculpado es culpable (Cfcon2=0.60) 18
 La seguridad de que las huellas pertenecen al inculpado es muy grande, Así CFevid1 = 0.9. La certeza asociada a la conclusión de la regla es entonces: CFcomb1 = CFcon1 * CFevid1. = 0.75 * = La siguiente evidencia la aporta un testigo (la suegra del inculpado) que asegura que éste tenía un motivo para el crimen. REGLA 2: Si el inculpado tenía un motivo. Entonces el inculpado es culpable. (Cfcon2=0.60) 18.")
19
La certeza asociada a la conclusión de la regla es entonces:
Ejemplo: Aparentemente las relaciones entre el inculpado y su suegra no son buenas, por lo que la certeza que el jurado asigna a esta evidencia es sólo de 0.5. Así CFevid2 = 0.5 La certeza asociada a la conclusión de la regla es entonces: CFnew = CFcomb2 = CFcon2 * CFevid2 = 0.6 * 0.50 = 0.30 Esta evidencia debe ser combinada con la obtenida anteriormente: CFrevised = CFold + CFnew * ( 1 - CFold ) = * ( ) = 19
 = * ( ) =")
20
REGLA 3: Si el acusado tiene una coartada
En este momento el acusado se siente perdido y todo parece estar en su contra. Sin embargo todavía hay una esperanza. Existe un testigo que puede proporcionarle al acusado una coartada. Dice el testigo que el momento del crimen el acusado se encontraba con él. REGLA 3: Si el acusado tiene una coartada Entonces el inculpado (no) es culpable (Cfcon3= - 0.8) Este testigo es una persona muy respetable (es un juez) y en consecuencia el jurado le otorga una certeza muy alta, Así CFevid3 = 0.95 La certeza asociada a la conclusión de la regla es entonces: CFnew = CFcomb3 = CFcon3 * CFevid3 = (-0.8 ) * 0.95 = Esta evidencia debe ser combinada con la obtenida anteriormente: 20
 es culpable. (Cfcon3= - 0.8) Este testigo es una persona muy respetable (es un juez) y en consecuencia el jurado le otorga una certeza muy alta, Así CFevid3 = La certeza asociada a la conclusión de la regla es entonces: CFnew = CFcomb3 = CFcon3 * CFevid3. = (-0.8 ) * = Esta evidencia debe ser combinada con la obtenida anteriormente: 20.")
21
Ventajas y desventajas de los Factores de Certeza
1. Simplicidad computacional. 2. Permite expresar tanto credibilidad como incredibilidad. 3. Permite un SBR con incertidumbre. 4. No se requiere una evaluación estadística para obtener los CFs. (se obtienen de un experto). Inconvenientes 1. Las evidencias que no son independientes sólo pueden combinarse dentro de una misma regla. 2. La adición o eliminación de conocimiento de la base de conocimiento puede requerir cambios de los CFs asociados a las reglas. 21
. Inconvenientes. 1. Las evidencias que no son independientes sólo pueden. combinarse dentro de una misma regla. 2. La adición o eliminación de conocimiento de la base de. conocimiento puede requerir cambios de los CFs. asociados a las reglas. 21.")
22
Modelos difusos de representación y tratamiento de la incertidumbre
Introducción a la Lógica Borrosa Teoría de conjuntos difusos / borrosos (Fuzzy set theory) L. Zadeh, 1965 Modelos difusos de representación y tratamiento de la incertidumbre Definición. Conjunto: La reunión de todos los elementos que verifican una condición “El conjunto de todos los elementos de Y que verifican A(x)” 22
 L. Zadeh, Modelos difusos de representación y tratamiento de la incertidumbre. Definición. Conjunto: La reunión de todos los elementos que verifican una condición. El conjunto de todos los elementos de Y que verifican A(x) 22.")
23
Introducción a la Lógica Borrosa
Definición. Conjunto: La reunión de todos los elementos que verifican una condición “El conjunto de todos los elementos de Y que verifican A(x)” Teoría de conjuntos difusos (Fuzzy set theory) Teoría clásica de conjuntos (Crisp set theory) “No pertenece” pertenencia de x al conjunto A “Sí pertenece” Existe un rango de grados de pertenencia entre las posibilidades extremas 23
 Teoría de conjuntos difusos (Fuzzy set theory) Teoría clásica de conjuntos (Crisp set theory) No pertenece pertenencia de x al conjunto A. Sí pertenece Existe un rango de grados de pertenencia entre las posibilidades extremas. 23.")
24
Introducción a la Lógica Borrosa
Idea Un conjunto difuso es un conjunto cuya fronteras no están bien definidas (subjetividad, vaguedad, imprecisión, ...) y, por tanto, la pertenencia o no de un elemento al mismo contiene una cierta incertidumbre Bayes Conjuntos Difusos Aleatoriedad de eventos definidos de manera precisa Subjetividad en la calificación de eventos no aleatorios 24
 y, por tanto, la pertenencia o no de un elemento al mismo contiene una cierta incertidumbre. Bayes. Conjuntos Difusos. Aleatoriedad de eventos definidos de manera precisa. Subjetividad en la calificación de eventos no aleatorios. 24.")
25
Ejemplo: Sea el conjunto de las personas consideradas “altas” definido sobre el conjunto de la población española, y consideremos un elemento del mismo denominado “pepe”. La cuestión de si pepe pertenece o no al conjunto de las personas “altas” puede resolverse atendiendo a la medida altura(pepe) y una función que mide la posibilidad de ser considerado alto en base a la altura. 1.0 0.5 0.0 alto(altura) 1.5 2.0 altura (m) 25
 y una función que mide la posibilidad de ser considerado alto en base a la altura alto(altura) altura (m) 25.")
26
Definición de la Función de posibilidad (Función de pertenencia)
1. Como una función de cualquier conjunto de parámetros pk(x) del elemento x. 2. Por enumeración de pares definidos sobre elementos discretos del conjunto donde no representa una suma, sino una agregación de pares. a(x)/x no representa ningún cociente, sino un par (posibilidad/elemento) Ejemplo: Sea el ejemplo anterior donde se definía el conjunto de personas “altas”. Si el conjunto de posibles alturas se representa por un conjunto de alturas discretas, U, tal que, U= { 1.30, 1.50, 1.70, 1.90, 2.10 } podemos definir la distribución de posibilidad de “ser alto” sobre el conjunto U como: ALTO = 0.0/ / / / /2.10 26
 del elemento x. 2. Por enumeración de pares definidos sobre elementos discretos del conjunto. donde. no representa una suma, sino una agregación de pares. a(x)/x no representa ningún cociente, sino un par (posibilidad/elemento) Ejemplo: Sea el ejemplo anterior donde se definía el conjunto de personas altas . Si el conjunto de posibles alturas se representa por un conjunto de alturas discretas, U, tal que, U= { 1.30, 1.50, 1.70, 1.90, 2.10 } podemos definir la distribución de posibilidad de ser alto sobre el conjunto U como: ALTO = 0.0/ / / / /")
27
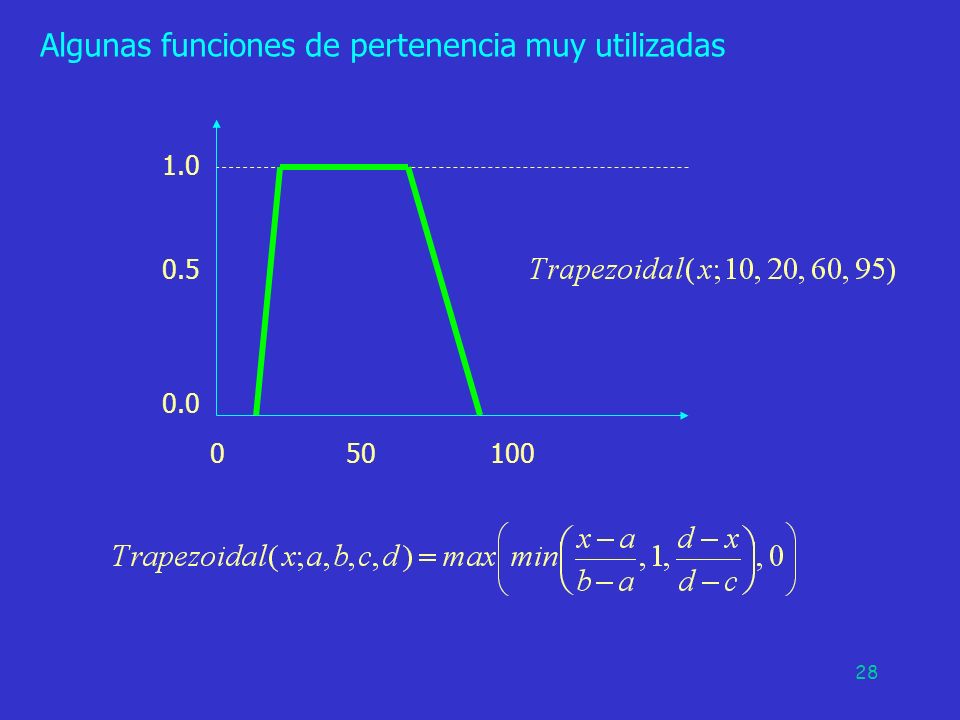
Algunas funciones de pertenencia muy utilizadas
1.0 0.5 0.0 50 100 27

28
Algunas funciones de pertenencia muy utilizadas
1.0 0.5 0.0 50 100 28
29
Algunas funciones de pertenencia muy utilizadas
1.0 0.5 0.0 50 100 29

30
Algunas funciones de pertenencia muy utilizadas
1.0 0.5 0.0 50 100 30

31
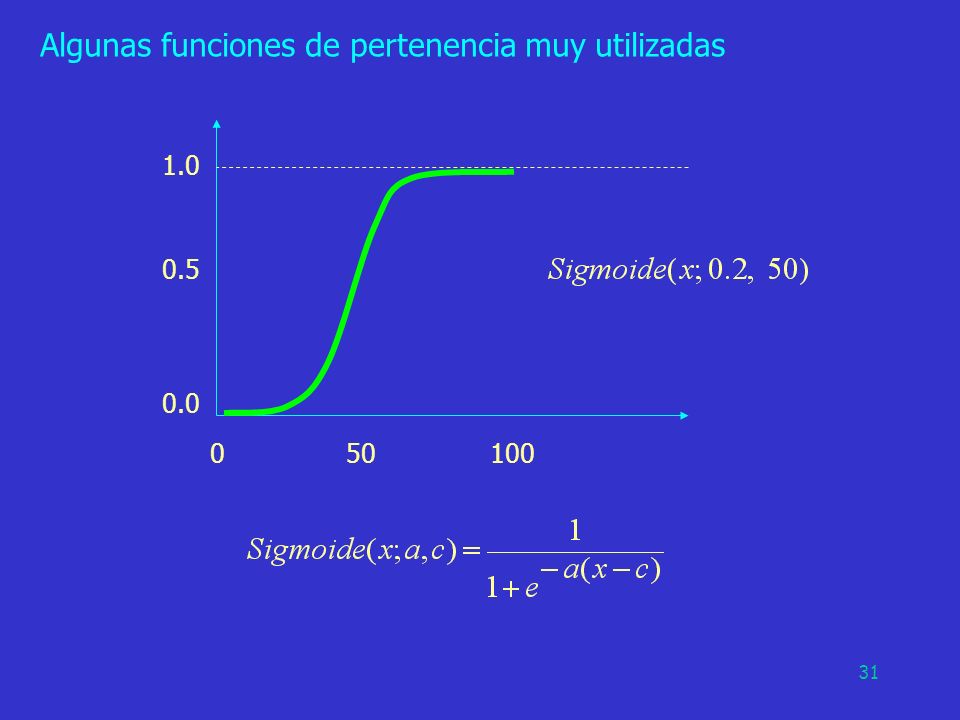
Algunas funciones de pertenencia muy utilizadas
1.0 0.5 0.0 50 100 31
32
Modificadores (Hedges)
Es posible introducir conjuntos difusos por transformación lingüística de uno dado. Algunos de los más frecuentes son: muy A más_o_menos A no A En general, pueden introducirse nuevas clases de cualificadores o modificadores en la forma: 32

33
Extensión cilíndrica En el caso de que se quiera realizar la composición de dos conjuntos cuyas bases de parámetros sean diferentes, será necesario definir una base de parámetros comunes. A este proceso se le denomina Extensión Cilíndrica. Sea una distribución posibilista del conjunto A sobre el parámetro definido por U1, dada por: U1 = { 1, 2, 5 } Y sea otra distribución posibilista del conjunto B sobre el parámetro definido por U2, tal que: U2 = { 8, 10, 15 } 33

34
Extensión cilíndrica Se define la extensión cilíndrica de A sobre el producto cartesiano de los parámetros U1 y U2, dado por U3 = U1xU2 como: U2 1 (1,8) (1,10) (1,15) U1 2 (2,8) (2,10) (2,15) 5 (5,8) (5,10) (5,15) 34
 (1,10) (1,15) U1 2 (2,8) (2,10) (2,15) 5 (5,8) (5,10) (5,15) 34.")
35
Proyección Es el proceso inverso al de Extensión cilíndrica. De él se obtiene una distribución posibilista sobre un conjunto de parámetros inferior de acuerdo con: donde sup es el valor supremo sobre el parámetro xn. Ejemplo: Sea la distribución posibilista A(x,y) dada por: A = 1.0/(1, 3) + 0.9/(1, 6) + 0.8/(1, 9) 0.7/(5, 3) + 0.6/(5, 6) + 0.5/(5, 9) 0.4/(8, 3) + 0.3/(8, 6) + 0.2/(8, 9) tiene una proyección sobre Y, A´(x), dada por: A´= 1.0/ / /8 35
 dada por: A = 1.0/(1, 3) + 0.9/(1, 6) + 0.8/(1, 9) 0.7/(5, 3) + 0.6/(5, 6) + 0.5/(5, 9) 0.4/(8, 3) + 0.3/(8, 6) + 0.2/(8, 9) tiene una proyección sobre Y, A´(x), dada por: A´= 1.0/ / /")
36
Reglas de Composición Dados los conjuntos A y B, cuyas distribuciones de posibilidad son conocidas se define la distribución de posibilidad de una composición de ambas como: A*B(x) = F*(A(x), B(x)) Unión: AB(x) = F(A(x), B(x)) Intersección: AB(x) = F(A(x), B(x)) Complemento: ¬A(x) = F ¬(A(x)) F(A(x), B(x)) S-norma F(A(x), B(x)) T-norma Normalmente las funciones AB(x), AB(x) y ¬A(x) serán dependientes de la semántica del conjunto. Sin embargo, se puede simplificar tales funciones suponiendo que dependen solamente de las distribuciones de los conjuntos A y B por separado. 36
 = F*(A(x), B(x)) Unión: AB(x) = F(A(x), B(x)) Intersección: AB(x) = F(A(x), B(x)) Complemento: ¬A(x) = F ¬(A(x)) F(A(x), B(x)) S-norma. F(A(x), B(x)) T-norma. Normalmente las funciones AB(x), AB(x) y ¬A(x) serán dependientes de la semántica del conjunto. Sin embargo, se puede simplificar tales funciones suponiendo que dependen solamente de las distribuciones de los conjuntos A y B por separado. 36.")
37
Simplificación 1: Comportamiento monótono
Por ejemplo: coches_veloces coches Dado que se verifica: A A B B A B A B A A B B entonces por la simplificación anterior deben verificarse también: A(x) AB(x) B(x) AB(x) AB(x) A(x) AB(x) B(x) Esto implica que deben cumplirse las siguienes restricciones sobre las operaciones de unión e intersección AB(x) max(A(x), B(x)) A B(x) min(A(x), B(x)) 37
 AB(x) B(x) AB(x) AB(x) A(x) AB(x) B(x) Esto implica que deben cumplirse. las siguienes restricciones sobre las operaciones de unión e intersección. AB(x) max(A(x), B(x)) A B(x) min(A(x), B(x)) 37.")
38
Simplificación 2: Definición del complementario
Para definir la distribución del conjunto complementario se asume la siguiente simplificación: Lo que equivale a: 38

39
AB(x) max(A(x), B(x)) AB(x) = max(A(x), B(x))
Operadores de Zadeh: Zadeh estableció como definición de las leyes de pertenencia a los conjuntos intersección y unión las cotas máximas y mínimas respectivamente de dichos conjuntos: AB(x) max(A(x), B(x)) AB(x) = max(A(x), B(x)) AB(x) = min(A(x), B(x)) AB(x) min(A(x), B(x)) ¬A(x) = 1 - A(x) Estas definiciones no están exentas de paradojas, por ejemplo: A¬A(x) = max(A(x), 1 - A(x)) 1 A¬A(x) = min(A(x), 1 - A(x)) 0 Un elemento puede pertenecer a un conjunto y su complementario Un elemento puede no pertenecer “del todo” a un conjunto y su complementario 39
 max(A(x), B(x)) AB(x) = max(A(x), B(x)) AB(x) = min(A(x), B(x)) AB(x) min(A(x), B(x)) ¬A(x) = 1 - A(x) Estas definiciones no están exentas de paradojas, por ejemplo: A¬A(x) = max(A(x), 1 - A(x)) 1. A¬A(x) = min(A(x), 1 - A(x)) 0. Un elemento puede pertenecer a un conjunto y su complementario. Un elemento puede no pertenecer del todo a un conjunto y su complementario. 39.")
40
Intersecciones difusas Rango
Uniones difusas Intersecciones difusas Rango 40

41
Se construye a partir de la teoría de conjuntos difusos
Lógica Difusa Se construye a partir de la teoría de conjuntos difusos El grado de verdad o certeza de una proposición p es un valor en el contínuo [0,1] proposición p: X es A p(x) = A(x) Para completar el cálculo de proposiciones se definen los conectores AND, OR y NOT p q : (X es A) (Y es B) p q : (X es A) (Y es B) p: (X es A) 41
 = A(x) Para completar el cálculo de proposiciones se definen los conectores AND, OR y NOT. p q : (X es A) (Y es B) p q : (X es A) (Y es B) p: (X es A) 41.")
42
Por otro lado debe recordarse que :
Lógica Difusa Para completar el cálculo de proposiciones se definen los conectores AND, OR y NOT p q : (X es A) (Y es B) p q : (X es A) (Y es B) p: (X es A) Puede ocurrir que las distribuciones posibilistas p y q no estén definidas sobre la misma base de parámetros. En ese caso es necesario extender cilíndricamente dichas distribuciones. Por otro lado debe recordarse que : pq(x) max(p(x), q(x)) pq(x) min(p(x), q(x)) 42
 (Y es B) p q : (X es A) (Y es B) p: (X es A) Puede ocurrir que las distribuciones posibilistas p y q no estén definidas sobre la misma base de parámetros. En ese caso es necesario extender cilíndricamente dichas distribuciones. Por otro lado debe recordarse que : pq(x) max(p(x), q(x)) pq(x) min(p(x), q(x)) 42.")
43
En general, definiremos las funciones and(), or() y not() como:
Lógica Difusa En general, definiremos las funciones and(), or() y not() como: pq(x) = or(p(x), q(x)) pq(x) = and(p(x), q(x)) ¬p(x) = not(p(x)) En el caso más general: pq(x,y) = or(p(x), q(y)) pq(x,y) = and(p(x), q(y)) Las funciones and(), or() y not() son dependientes de la semántica de las proposiciones o Universo del Discurso. Deben verificar en cualquier caso las siguientes relaciones para ser compatibles con los valores booleanos en el límite de no borrosidad: 43
, or() y not() como: pq(x) = or(p(x), q(x)) pq(x) = and(p(x), q(x)) ¬p(x) = not(p(x)) En el caso más general: pq(x,y) = or(p(x), q(y)) pq(x,y) = and(p(x), q(y)) Las funciones and(), or() y not() son dependientes de la semántica de las proposiciones o Universo del Discurso. Deben verificar en cualquier caso las siguientes relaciones para ser compatibles con los valores booleanos en el límite de no borrosidad: 43.")
44
Un conjunto muy amplio de funciones cumplen estas restricciones.
Lógica Difusa Las funciones and(), or() y not() son dependientes de la semántica de las proposiciones o Universo del Discurso. Deben verificar en cualquier caso las siguientes relaciones para ser compatibles con los valores booleanos en el límite de no borrosidad: or(1, u) = 1 or(0, u) = u and(1, u) = u and(0, u) = 0 not(1) = 0 not(0) = 1 Un conjunto muy amplio de funciones cumplen estas restricciones. Dos modelos muy empleados son los siguientes Modelo de Zadeh: or1(u, v) = max(u, v) and1(u, v) = min(u, v) not(u) = 1 - u Modelo Pseudoprobabilístico: or2(u, v) = u + v - u·v and2(u, v) = u·v not(u) = 1 - u 44
, or() y not() son dependientes de la semántica de las proposiciones o Universo del Discurso. Deben verificar en cualquier caso las siguientes relaciones para ser compatibles con los valores booleanos en el límite de no borrosidad: or(1, u) = 1. or(0, u) = u. and(1, u) = u. and(0, u) = 0. not(1) = 0. not(0) = 1. Un conjunto muy amplio de funciones cumplen estas restricciones. Dos modelos muy empleados son los siguientes. Modelo de Zadeh: or1(u, v) = max(u, v) and1(u, v) = min(u, v) not(u) = 1 - u. Modelo Pseudoprobabilístico: or2(u, v) = u + v - u·v. and2(u, v) = u·v. not(u) = 1 - u. 44.")
45
E) p (q r) (p q) (p r) F) p (q r) (p q) (p r)
or1(u, v) = max(u, v) and1(u, v) = min(u, v) not(u) = 1 - u Lógica Booleana Modelo de Zadeh A) p p 1 B) p p 0 C) p (q r) (p q) r D) p (q r) (p q) r E) p (q r) (p q) (p r) F) p (q r) (p q) (p r) G) (p q) p q H) (p q) p q A) max(u, 1- u) 1 B) min(u, 1 - u) 0 C) D) E) F) G) H) 45
 = max(u, v) and1(u, v) = min(u, v) not(u) = 1 - u. Lógica Booleana. Modelo de Zadeh. A) p p 1. B) p p 0. C) p (q r) (p q) r. D) p (q r) (p q) r. E) p (q r) (p q) (p r) F) p (q r) (p q) (p r) G) (p q) p q. H) (p q) p q. A) max(u, 1- u) 1. B) min(u, 1 - u) 0. C) D) E) F) G) H) 45.")
46
Modelo Pseudoprobabilístico
or2(u, v) = u + v -u·v and2(u, v) = u·v not(u) = 1 - u Lógica Booleana Modelo Pseudoprobabilístico A) p p 1 B) p p 0 C) p (q r) (p q) r D) p (q r) (p q) r E) p (q r) (p q) (p r) F) p (q r) (p q) (p r) G) (p q) p q H) (p q) p q A) u + (1- u) - u·(1-u) 1 B) u·(1 - u) 0 C) D) E) F) G) H) 46
 = u + v -u·v. and2(u, v) = u·v. not(u) = 1 - u. Lógica Booleana. Modelo Pseudoprobabilístico. A) p p 1. B) p p 0. C) p (q r) (p q) r. D) p (q r) (p q) r. E) p (q r) (p q) (p r) F) p (q r) (p q) (p r) G) (p q) p q. H) (p q) p q. A) u + (1- u) - u·(1-u) 1. B) u·(1 - u) 0. C) D) E) F) G) H) 46.")
47
Demostración de la primera ley de Morgan
p q=max(p,q) (p q)=1-max(p,q) p q = min(1-p,1-q) p q p p p p < q q q q p q (p q p q p+ q - p·q p - q + p·q (1 - p)(1 - q) = 1 - p - q + p·q (p q) p q 47
 (p q)=1-max(p,q) p q = min(1-p,1-q) p q p 1 - p 1 - p. p < q q 1 - q 1 - q. p q. (p q. p q. p+ q - p·q 1 - p - q + p·q (1 - p)(1 - q) = 1 - p - q + p·q. (p q) p q. 47.")
48
La operación de implicación se puede expresar en la forma:
Inferencia Difusa La operación de implicación se puede expresar en la forma: p q : si (X es A) entonces (Y es B) donde A y B son variables lingüísticas definidas como conjuntos difusos sobre los universos de discurso de X e Y respectivamente. Ejemplos: Si la presión es baja entonces el volumen es grande Si el tomate es rojo entonces está maduro Si la velocidad es alta entonces frenar ligeramente 48
 entonces (Y es B) donde A y B son variables lingüísticas definidas como conjuntos difusos sobre los universos de discurso de X e Y respectivamente. Ejemplos: Si la presión es baja entonces el volumen es grande. Si el tomate es rojo entonces está maduro. Si la velocidad es alta entonces frenar ligeramente. 48.")
49
Inferencia Difusa El principal problema para establecer un valor de certeza a este operador estriba en definir una interpretación del mismo. Sea imp() una función que proporciona la certeza en una fórmula con implicación. Veamos posibles interpretaciones: 49
 una función que proporciona la certeza en una fórmula con implicación. Veamos posibles interpretaciones: 49.")
50
A) Basada en la equivalencia siguiente, válida en el límite booleano
p q ¬ p q p q p q ¬ p ¬p q ¬ q p ¬q ¬(p ¬q) T T T F T F F T T F F F F T T F F T T T T F F T F F T T T T F T De acuerdo con esta interpretación y según los operadores ya definidos: imp1(u, v) = max(1 - u, v) imp2(u, v) = (1 - u) + v - (1 - u)·v 50
 T T T F T F F T. T F F F F T T F. F T T T T F F T. F F T T T T F T. De acuerdo con esta interpretación y según los operadores ya definidos: imp1(u, v) = max(1 - u, v) imp2(u, v) = (1 - u) + v - (1 - u)·v. 50.")
51
p (p q) q (modus ponens)
B) Basada en la idea: “La certeza del consecuente es superior o igual a la conjunción del antecedente e implicación” p (p q) q (modus ponens) B1) min(u, imp(u, v)) v B2) u * imp(u, v)) v C) Implicación de Lukasiewicz imp5(u, v) = min(1 - u + v, 1) 51
 Basada en la idea: La certeza del consecuente es superior o igual a la conjunción del antecedente e implicación p (p q) q (modus ponens) B1) min(u, imp(u, v)) v. B2) u * imp(u, v)) v. C) Implicación de Lukasiewicz. imp5(u, v) = min(1 - u + v, 1) 51.")
52
d) u v mod(u, w) mod(v, w) d) La función mod() debe ser
Modus Ponens Empleando alguna de las definiciones anteriores de implicación es posible definir el proceso de inferencia difusa empleando “modus ponens”. p (p q) q Dadas las certezas de un antecedente y la de la implicación, la determinación de la certeza del consecuente se realiza en base a una función generadora del modus ponens que denominaremos mod() La función mod() debe verificar una serie de propiedades, algunas de las cuales son las siguientes: a) mod(u, imp(u, v)) v b) mod(1, 1) = 1 c) mod(0, u) = v d) u v mod(u, w) mod(v, w) d) La función mod() debe ser monótona creciente con la certeza del antecedente c) De un antecedente completamente falso puede concluirse cualquier cosa a) La función mod() tiene como cota superior la certeza del consecuente b) Este es el límite booleano del modus ponens 52
 q. Dadas las certezas de un antecedente y la de la implicación, la determinación de la certeza del consecuente se realiza en base a una función generadora del modus ponens que denominaremos mod() La función mod() debe verificar una serie de propiedades, algunas de las cuales son las siguientes: a) mod(u, imp(u, v)) v. b) mod(1, 1) = 1. c) mod(0, u) = v. d) u v mod(u, w) mod(v, w) d) La función mod() debe ser. monótona creciente con la certeza. del antecedente. c) De un antecedente completamente. falso puede concluirse cualquier. cosa. a) La función mod() tiene como. cota superior la certeza del. consecuente. b) Este es el límite booleano del. modus ponens. 52.")
53
Funciones generadoras del modus ponens que resultan de las definiciones de la función implicación presentadas anteriormente: 53

54
regla: si (el coche es viejo) entonces (el coche es ruidoso)
premisa: (el coche es bastante viejo) (el coche es bastante ruidoso) Todas estas expresiones son válidas para la realización de inferencia en casos análogos al siguiente: regla: si (x es A) entonces (y es B) premisa: (x es A) (y es B) Y también en casos como el siguiente, donde A y A’ poseen la misma base de parámetros: regla: si (x es A) entonces (y es B) premisa: (x es A’ ) (y es B’) 54
 (el coche es bastante ruidoso) Todas estas expresiones son válidas para la realización de inferencia en casos análogos al siguiente: regla: si (x es A) entonces (y es B) premisa: (x es A) (y es B) Y también en casos como el siguiente, donde A y A’ poseen la misma base de parámetros: regla: si (x es A) entonces (y es B) premisa: (x es A’ ) (y es B’) 54.")
55
Razonamiento difuso basado en la composición Max-Min
Sean A y A’ conjuntos difusos en X y sea B otro conjunto difuso en Y. Supongamos que la implicación difusa (A B) definida sobre X x Y se expresa como: Consideremos la regla, si (x es A) entonces (y es B) y la premisa (x es A’ ) El conjunto difuso inducido B’, se define según hemos visto como Nótese que esta definición de la implicación no es sino una expresión equivalente a imp3(u, v). 55
 definida sobre X x Y se expresa como: Consideremos la regla, si (x es A) entonces (y es B) y la premisa. (x es A’ ) El conjunto difuso inducido B’, se define según hemos visto como. Nótese que esta definición de la implicación no es sino una expresión equivalente a imp3(u, v). 55.")
56
1. Una regla con un único antecedente
Para este caso la ecuación anterior se transforma en: donde w representa un índice de compatibilidad entre la premisa y el antecedente de la regla. A A’ B w B’ x x 56

57
2. Una regla con dos antecedentes
si (x es A) y (y es B) entonces (z es C) (x es A’ ) y (y es B’ ) (z es C’ ) Una regla de este tipo puede representarse por una implicación A x B C de manera que: 57
 y (y es B) entonces (z es C) (x es A’ ) y (y es B’ ) (z es C’ ) Una regla de este tipo puede representarse por una implicación A x B C de manera que: 57.")
58
donde w1 w2 se puede asociar con el grado de satisfacción
o intensidad de disparo de la regla 58

59
2. Una regla con dos antecedentes
min A A’ B B’ C w1 C’ w2 x x 59 x

60
3. Múltiples reglas con múltiples antecedentes
La interpretación de múltiples reglas se toma usualmente como la unión de las inferencias difusas obtenidas de cada una de las reglas. hecho: (x es A’ ) y (y es B’ ) regla 1: si (x es A1) y (y es B1) entonces (z es C1) regla 2: si (x es A2) y (y es B2) entonces (z es C2) consecuencia: (Z es C’ ) Resulta intuitivo observar que del caso anterior C’ = C1 C2 60
 y (y es B’ ) regla 1: si (x es A1) y (y es B1) entonces (z es C1) regla 2: si (x es A2) y (y es B2) entonces (z es C2) consecuencia: (Z es C’ ) Resulta intuitivo observar que del caso anterior C’ = C1 C")
61
min A1 A’ B1 B’ C1 w11 C’1 w12 x x x A2 A’ B2 B’ C2 w21
max C’ 61 x

62
Cuando una regla difusa asume la forma
“si (x es A) o (y es B) entonces (z es C)” la intensidad de disparo de la regla (w) viene dada por el máximo de los grados de correspondencia de los antecedentes. Esto es: donde: 62
 o (y es B) entonces (z es C) la intensidad de disparo de la regla (w) viene dada por el máximo de los grados de correspondencia de los antecedentes. Esto es: donde: 62.")
63
Métodos de concentración (Defuzzification)
x A La utilización de reglas de inferencia difusas produce, tras la evaluación, un conjunto difuso para cada variable del modelo: Ejemplo: si (x es X) entonces (D es A) si (y es Y) entonces (D es B) si (z es Z) entonces (D es C) El conjunto resultante D es un conjunto difuso que representa a una cierta variable D a la que normalmente es necesario asignar un valor escalar. B D y y C Valor escalar 63 y
 entonces (D es A) si (y es Y) entonces (D es B) si (z es Z) entonces (D es C) El conjunto resultante D es un conjunto difuso que representa a una cierta variable D a la que normalmente es necesario asignar un valor escalar. B. D. y. y. C. Valor escalar. 63. y.")
64
Métodos de concentración (Defuzzification)
Posibles medidas menor de maximos Todos son métodos heurísticos para encontrar “el valor” que mejor representa o sintetiza la información contenida en el conjunto difuso. media de maximos mayor de maximos centroide Uno de los más empleados: Centroide: x 64

65
Control Difuso de una turbina de vapor
Un caso de estudio: Control Difuso de una turbina de vapor Introducción: Se pretende controlar la inyección de combustible en una turbina de vapor al objeto de mantener constante la velocidad. La cantidad de combustible que se consume por unidad de tiempo (tasa de consumo) se incrementa o disminuye mediante la apertura o cierre, repectivamente, de la válvula de inyección en función de la temperatura y la presión en la caldera. 65
 se incrementa o disminuye mediante la apertura o cierre, repectivamente, de la válvula de inyección en función de la temperatura y la presión en la caldera. 65.")
66
Controlador de la válvula de inyección
Se pretende controlar la inyección de combustible en una turbina de vapor al objeto de mantener constante la velocidad. La cantidad de combustible que se consume por unidad de tiempo (tasa de consumo) se incrementa o disminuye mediante la apertura o cierre, repectivamente, de la válvula de inyección en función de la temperatura y la presión en la caldera. Sensor RPM RPM(t) RPM(t) Sensor RPM T(t) Sensor de temperatura Controlador de la válvula de inyección I(t) Planta de la turbina Sensor de presión P(t) Sensores 66
 se incrementa o disminuye mediante la apertura o cierre, repectivamente, de la válvula de inyección en función de la temperatura y la presión en la caldera. Sensor. RPM. RPM(t) RPM(t) Sensor. RPM. T(t) Sensor de. temperatura. Controlador de la válvula de inyección. I(t) Planta de la turbina. Sensor de. presión. P(t) Sensores. 66.")
67
1. Descomponer cada variable del modelo en un conjunto de regiones difusas (vocabulario de cada variable) MUY_BAJA MUY_ALTA OPTIMA BAJA ALTA 1 TEMPERATURA ºC 67

68
MUY_BAJA MUY_ALTA OPTIMA BAJA ALTA 1 PRESIÓN Kg/m2 68

69
ACCIONES SOBRE LA VÁLVULA
CERRAR_UN_POCO (CP) CERRAR_MUCHO (CM) ABRIR_UN_POCO (AP) ABRIR_MUCHO (AM) DEJAR_IGUAL (OK) CERRAR (C) ABRIR (A) 1 ACCIONES SOBRE LA VÁLVULA cm/sg 69
 CERRAR_MUCHO (CM) ABRIR_UN_POCO (AP) ABRIR_MUCHO (AM) DEJAR_IGUAL (OK) CERRAR (C) ABRIR (A) 1. ACCIONES SOBRE LA VÁLVULA cm/sg. 69.")
70
2. Sintetizar las reglas de control (base de conocimiento)
Por ejemplo: [R1] Si la temperatura es baja y la presión es muy_baja entonces la acción sobre la válvula es abrir_mucho [R2] Si la temperatura es baja y la presión es baja entonces la acción sobre la válvula es abrir [R3] Si la temperatura es baja y la presión es óptima entonces la acción sobre la válvula es dejar_igual [R4] Si la temperatura es baja y la presión es alta entonces la acción sobre la válvula es cerrar 70

71
3. El Algoritmo A. Leer los sensores de presión y temperatura
B. Hacer solución(x) = 0 C. Para todas la reglas cuyos antecedentes no sean nulos C.1 Obtener el mínimo de todos los predicados conectados por operadores conjuntivos (AND) en el antecedente de la regla. Pcerteza = min(E1, E2, ..., En) C.2 Obtener la certeza de la regla control(x) = min( regla(x), Pcerteza ) C.3 Asignar el conjunto difuso obtenido en control(x) al conjunto solución mediante una operación de máximo (OR) solución(x) = max( solución(x), control(x) ) D. Concentrar solución(x) (p.e. obteniendo el centroide) para obtener el valor escalar que requiere la acción de control. 71
 = 0. C. Para todas la reglas cuyos antecedentes no sean nulos. C.1 Obtener el mínimo de todos los predicados conectados por operadores conjuntivos (AND) en el antecedente de la regla. Pcerteza = min(E1, E2, ..., En) C.2 Obtener la certeza de la regla. control(x) = min( regla(x), Pcerteza ) C.3 Asignar el conjunto difuso obtenido en control(x) al conjunto solución mediante una operación de máximo (OR) solución(x) = max( solución(x), control(x) ) D. Concentrar solución(x) (p.e. obteniendo el centroide) para obtener el valor escalar que requiere la acción de control. 71.")
72
Las reglas cuyos antecedentes no son nulos son:
Veamos como funciona Supongamos que tras leer los sensores, la presión cae dentro del dominio de los conjuntos difusos OPTIMA y BAJA; y la temperatura se incluye dentro del conjunto difuso BAJA. Las reglas cuyos antecedentes no son nulos son: [R2] Si la temperatura es baja y la presión es baja entonces la acción sobre la válvula es abrir [R3] Si la temperatura es baja y la presión es óptima entonces la acción sobre la válvula es dejar_igual 72

73
CERRAR_UN_POCO (CP) CERRAR_MUCHO (CM) ABRIR_UN_POCO (AP) ABRIR_MUCHO (AM) DEJAR_IGUAL (OK) MUY_BAJA MUY_ALTA CERRAR (C) OPTIMA ABRIR (A) MUY_BAJA MUY_ALTA OPTIMA BAJA ALTA BAJA ALTA 1 1 1 ºC Kg/m2 cm/sg 73
 OPTIMA. ABRIR (A) MUY_BAJA. MUY_ALTA. OPTIMA. BAJA. ALTA. BAJA. ALTA ºC Kg/m cm/sg. 73.")
74
0.57 0.48 0.48 0.25 Temperatura Presión Centroide= 23 cm/sg
1 BAJA 1 BAJA 1 ABRIR (A) 0.57 0.48 ºC Kg/m2 cm/sg 1 BAJA 1 OPTIMA 1 DEJAR_IGUAL (OK) 0.48 0.25 ºC Kg/m2 cm/sg 1 Temperatura Presión DEJAR_IGUAL (OK) Centroide= 23 cm/sg Acciones de control sobre la vávula cm/sg 74
 ºC Kg/m cm/sg. 1. BAJA. 1. OPTIMA. 1. DEJAR_IGUAL (OK) ºC Kg/m cm/sg. 1. Temperatura. Presión. DEJAR_IGUAL (OK) Centroide= 23 cm/sg. Acciones de control. sobre la vávula cm/sg. 74.")
75
Bibliografía. [Mend-92] J. Méndez Apuntes del Curso de I.A. U.L.P.G.C.
[Rich-91] E. Rich, K. Knight Artificial Intelligence McGraw-Hill, 1991. [Gonz-93] A. J. Gonzalez, D.D. Dankel The Engineering of Knowledge-Based Systems Prentice-Hall, 1993. 75
![Bibliografía. [Mend-92] J. Méndez Apuntes del Curso de I.A. U.L.P.G.C.](http://slideplayer.es/slide/321098/2/images/75/Bibliograf%C3%ADa.+%5BMend-92%5D+J.+M%C3%A9ndez+Apuntes+del+Curso+de+I.A.+U.L.P.G.C..jpg "[Rich-91] E. Rich, K. Knight. Artificial Intelligence. McGraw-Hill, [Gonz-93] A. J. Gonzalez, D.D. Dankel. The Engineering of Knowledge-Based Systems. Prentice-Hall,")
Presentaciones similares



















