Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Regulación de la transcripción en eucariontes.

2
El control génico en eucarióticos
En organismos multicelulares su propósito es la ejecución de decisiones evolutivas precisas Los genes convenientes se expresan en células adecuadas durante el desarrollo y la diferenciación. Es el medio principal para regular la expresión génica en eucariontes. Los elementos de control se encuentran a varias kilobases del sito de inicio de transcripción.

3
El control génico en eucarióticos
Poseen tres tipos de RNA polimerasas. Tiene subunidades grandes que tienen homología con b y b´y pequeñas que tiene homología con la a de la RNA pol de bacterias. Presentan otras subunidades pequeñas. La RNA pol I sintetiza pre-RNA ribosomal La RNA pol II sintetiza mensajeros, RNA pequeños nucleares La RNA pol III sintetiza RNAr 5S, tRNA y RNAs estables y cortos.

4
RNA polimerasas Figure Schematic representation of the subunit structure of yeast nuclear RNA polymerases and comparison with E. coli RNA core polymerase. All three yeast polymerases have four core subunits that exhibit some homology with the b, b´, and α subunits in E. coli RNA polymerase. The largest subunit (L´) of RNA polymerase II also contains an essential C-terminal domain (CTD). RNA polymerases I and III contain the same two nonidentical a-like subunits, whereas polymerase II has two copies of a different α-like subunit. All three polymerases share five other common subunits (two copies of the largest of these). In addition, each yeast polymerase contains four to seven unique smaller subunits.
 of RNA polymerase II also contains an essential C-terminal domain (CTD). RNA polymerases I and III contain the same two nonidentical a-like subunits, whereas polymerase II has two copies of a different α-like subunit. All three polymerases share five other common subunits (two copies of the largest of these). In addition, each yeast polymerase contains four to seven unique smaller subunits.")
5
Tyr-Ser-Pro-Thr-Ser-Pro-Ser
Subunidad L´ de Pol II Contiene un extremo carboxilo terminal que es una repetición de la secuencia Tyr-Ser-Pro-Thr-Ser-Pro-Ser Conocido como el dominio carboxi-terminal o CTD. Levaduras contiene 26 repeticiones o más, mamíferos 52 repeticiones otros eucariontes intermedia.

6
CTD Se fosforila durante la iniciación de la transcripción
Permanece fosforilada durante la transcripción.

7
Foto fosforilación de CTD
Polimerasa no fosforilada verde Polimerasa fosforilada roja Figure Experimental demonstration that carboxyl-terminal domain (CTD) of RNA polymerase II is phosphorylated during in vivo transcription. Salivary gland polytene chromosomes were prepared from Drosophila larvae just before molting. The preparation was treated with a rabbit antibody specific for phosphorylated CTD and with a goat antibody specific for unphosphorylated CTD. The preparation then was stained with fluorescein-labeled anti-goat antibody (green) and rhodamine-labeled anti-rabbit antibody (red). Thus polymerase molecules with an unphosphorylated CTD stain green and those with a phosphorylated CTD stain red. The molting hormone ecdysone induces very high rates of transcription in the puffed regions labeled 74EF and 75B; note that only phosphorylated CTD is present in these regions. Smaller puffed regions transcribed at high rates also are visible. Nonpuffed sites that stain red (up arrow) or green (horizontal arrow) also are indicated, as is a site staining both red and green, producing a yellow color (down arrow). [From J. R. Weeks, 1993, Genes & Dev. 7:2329; courtesy of J. R. Weeks and A. L. Greenleaf.]
 of RNA polymerase II is phosphorylated during in vivo transcription. Salivary gland polytene chromosomes were prepared from Drosophila larvae just before molting. The preparation was treated with a rabbit antibody specific for phosphorylated CTD and with a goat antibody specific for unphosphorylated CTD. The preparation then was stained with fluorescein-labeled anti-goat antibody (green) and rhodamine-labeled anti-rabbit antibody (red). Thus polymerase molecules with an unphosphorylated CTD stain green and those with a phosphorylated CTD stain red. The molting hormone ecdysone induces very high rates of transcription in the puffed regions labeled 74EF and 75B; note that only phosphorylated CTD is present in these regions. Smaller puffed regions transcribed at high rates also are visible. Nonpuffed sites that stain red (up arrow) or green (horizontal arrow) also are indicated, as is a site staining both red and green, producing a yellow color (down arrow). [From J. R. Weeks, 1993, Genes & Dev. 7:2329; courtesy of J. R. Weeks and A. L. Greenleaf.]")
8
Figure Approximate mapping of transcription initiation site by analysis of nascent transcripts synthesized in vivo. A section of DNA in the act of being transcribed is depicted at the top. After cells are labeled for a brief time, producing labeled nascent RNAs, the cells are disrupted and the isolated RNA is separated on the basis of chain length by velocity sedimentation centrifugation. Each size fraction is then hybridized to restriction fragments A-E shown in the top diagram. The shortest labeled RNA transcripts hybridize to the restriction fragment (B) that contains the initiation site; the exact nucleotide at which transcription starts cannot be determined. Successively longer RNAs hybridize to fragments downstream from the initiation site. The longest labeled RNAs hybridize to the fragment (D) containing the termination site.
 that contains the initiation site; the exact nucleotide at which transcription starts cannot be determined. Successively longer RNAs hybridize to fragments downstream from the initiation site. The longest labeled RNAs hybridize to the fragment (D) containing the termination site..")
9
Figure Precise mapping of initiation site of adenovirus late transcription unit by in vitro transcription. (Left) The top line shows restriction sites for HindIII (black), XmaIII (blue), and SmaI (red) in the region of the adenovirus genome where the transcription-initiation site was located by nascent-transcript analysis (near 16 map units). The HindIII, XmaIII, and SmaI restriction fragments that encompass the initiation site were individually incubated with a nuclear extract prepared from HeLa cells and α-[32P]-labeled ribonucleoside triphosphates. Transcription of each fragment begins at the start site; when an RNA polymerase II molecule transcribing a fragment reaches a cut end, it “runs off” the template. (Right) The resulting run-off transcripts were then subjected to gel electrophoresis and autoradiography. Since the positions of the restriction sites in the DNA template were known, the lengths of the run-off transcripts (in nucleotides, nt) produced from the SmaI (lane 1), XmaIII (lane 2), and HindIII (lane 3) fragments precisely map the start site at 16.4 map units on the adenovirus genome. The sequences of this region of adenovirus DNA and of the capped 5′ end of the corresponding mRNAs and RNA transcripts produced in vitro are shown in the lower left. Thus the starting point for in vitro transcription by RNA polymerase II corresponds to the cap site in mRNA. The sample in lane 1a is the same as that in lane 1, except that α-amanitin, an inhibitor of RNA polymerase II, was included in the transcription mixture. The bands at the top and bottom of the gel represent high- and low-molecular-weight RNA transcripts that are formed under the conditions of this experiment. [See R. M. Evans and E. Ziff, 1978, Cell 15:1463; P. A. Weil et al., 1979,Cell 18:469. Photograph courtesy of R. G. Roeder.]
 The top line shows restriction sites for HindIII (black), XmaIII (blue), and SmaI (red) in the region of the adenovirus genome where the transcription-initiation site was located by nascent-transcript analysis (near 16 map units). The HindIII, XmaIII, and SmaI restriction fragments that encompass the initiation site were individually incubated with a nuclear extract prepared from HeLa cells and α-[32P]-labeled ribonucleoside triphosphates. Transcription of each fragment begins at the start site; when an RNA polymerase II molecule transcribing a fragment reaches a cut end, it runs off the template. (Right) The resulting run-off transcripts were then subjected to gel electrophoresis and autoradiography. Since the positions of the restriction sites in the DNA template were known, the lengths of the run-off transcripts (in nucleotides, nt) produced from the SmaI (lane 1), XmaIII (lane 2), and HindIII (lane 3) fragments precisely map the start site at 16.4 map units on the adenovirus genome. The sequences of this region of adenovirus DNA and of the capped 5′ end of the corresponding mRNAs and RNA transcripts produced in vitro are shown in the lower left. Thus the starting point for in vitro transcription by RNA polymerase II corresponds to the cap site in mRNA. The sample in lane 1a is the same as that in lane 1, except that α-amanitin, an inhibitor of RNA polymerase II, was included in the transcription mixture. The bands at the top and bottom of the gel represent high- and low-molecular-weight RNA transcripts that are formed under the conditions of this experiment. [See R. M. Evans and E. Ziff, 1978, Cell 15:1463; P. A. Weil et al., 1979,Cell 18:469. Photograph courtesy of R. G. Roeder.].")
10
Núcleos aislados se incuban con 32P-NTP (periodo corto).
Se marcan entre nucleótidos del RNA naciente. Hibridizando el RNA marcado con el DNA clonado para un gen específico, se puede saber cual es la fracción de transcripción de un gen. Figure Nascent-chain (run-on) assay for transcription rate of a gene. Isolated nuclei are incubated with 32P-labeled ribonucleoside triphosphates for a brief period. During this period RNA polymerase molecules that were transcribing a gene when the nuclei were isolated add 300 – 500 nucleotides to nascent RNA chains. Very little new initiation occurs. By hybridizing the labeled RNA to the cloned DNA for a specific gene (A in this case), the fraction of total RNA produced from that gene (i.e., its relative transcription rate) can be measured. [See J. Weber et al., 1977, Cell 10:611.]
 assay for transcription rate of a gene. Isolated nuclei are incubated with 32P-labeled ribonucleoside triphosphates for a brief period. During this period RNA polymerase molecules that were transcribing a gene when the nuclei were isolated add 300 – 500 nucleotides to nascent RNA chains. Very little new initiation occurs. By hybridizing the labeled RNA to the cloned DNA for a specific gene (A in this case), the fraction of total RNA produced from that gene (i.e., its relative transcription rate) can be measured. [See J. Weber et al., 1977, Cell 10:611.]")
11
Figure Experimental demonstration of differential synthesis of 12 mRNAs encoding liver-specific proteins. Nuclei from mouse liver, kidney, and brain cells were exposed to 32P-UTP, and the resulting labeled RNA was hybridized to various cDNAs fixed to nitrocellulose. After removal of unhybridized RNAs, the hybrids were revealed by autoradiography. The cDNAs labeled 1 – 12 encode proteins synthesized actively in liver (e.g., 4 = albumin; 3 = α1-antitrypsin; 6 = transferrin) but not in most other tissues. The other cDNAs tested were actin (A) and α- and β-tubulin (αT, βT), which are proteins found in almost all cell types. Methionine tRNA and the plasmid DNA (pB) in which the cDNAs were cloned were included as controls. The intensity of spots generated by hybridization of RNA synthesized during in vitro run-on transcription in nuclei isolated from the three tissues indicates that genes expressed specifically in hepatocytes are transcribed in liver and are not transcribed in the cells of other tissues. [See E. Derman et al., 1981, Cell 23:731; D. J. Powell et al., 1984,J. Mol. Biol. 197:21.]
 but not in most other tissues. The other cDNAs tested were actin (A) and α- and β-tubulin (αT, βT), which are proteins found in almost all cell types. Methionine tRNA and the plasmid DNA (pB) in which the cDNAs were cloned were included as controls. The intensity of spots generated by hybridization of RNA synthesized during in vitro run-on transcription in nuclei isolated from the three tissues indicates that genes expressed specifically in hepatocytes are transcribed in liver and are not transcribed in the cells of other tissues. [See E. Derman et al., 1981, Cell 23:731; D. J. Powell et al., 1984,J. Mol. Biol. 197:21.].")
12
Figure Construction and analysis of a 5´ -deletion series to locate transcription-control sequences in DNA upstream of a eukaryotic gene. A DNA fragment (yellow) containing a transcription-start site is cloned into a plasmid vector (upper left). The plasmid is linearized by digestion with a restriction enzyme (A) that cleaves at the upstream end of the fragment being analyzed. The linearized DNA is then digested with an exonuclease for different periods of time so that increasing lengths of DNA are removed from each end. After addition of a synthetic oligonucleotide linker and digestion with restriction enzymes B and C, the deleted fragments are cloned into a plasmid vector with an easily assayed reporter gene (light blue). Plasmids with deletions of various lengths 5′ to the transcription-start site are then transfected into cultured cells (or used to prepare transgenic organisms) and expression of the reporter gene is assayed. The results of this hypothetical example (bottom) indicate that the test fragment contains two control elements. The 5´ end of one lies between deletions 2 and 3; the 5´ end of the other lies between deletions 4 and 5.
 containing a transcription-start site is cloned into a plasmid vector (upper left). The plasmid is linearized by digestion with a restriction enzyme (A) that cleaves at the upstream end of the fragment being analyzed. The linearized DNA is then digested with an exonuclease for different periods of time so that increasing lengths of DNA are removed from each end. After addition of a synthetic oligonucleotide linker and digestion with restriction enzymes B and C, the deleted fragments are cloned into a plasmid vector with an easily assayed reporter gene (light blue). Plasmids with deletions of various lengths 5′ to the transcription-start site are then transfected into cultured cells (or used to prepare transgenic organisms) and expression of the reporter gene is assayed. The results of this hypothetical example (bottom) indicate that the test fragment contains two control elements. The 5´ end of one lies between deletions 2 and 3; the 5´ end of the other lies between deletions 4 and 5..")
13
Identificación de RNA polimerasas de eucariontes
Cromatografía en DEAE sefadex. Figure The separation and identification of the three eukaryotic RNA polymerases by column chromatography. A protein extract from the nuclei of cultured frog cells was passed through a DEAE Sephadex column to which charged proteins absorb differentially. Adsorbed proteins were eluted (black curve) with a solution of constantly increasing NaCl concentration. Fractions containing the eluted proteins were assayed for the ability to transcribe DNA (red curve) in the presence of the four ribonucleoside triphosphates. The synthesis of RNA by each fraction in the presence of 1 μg/ml of α-amanitin also was measured (blue curve). At this concentration, α-amanitin inhibits polymerase II activity but has no effect on polymerases I and III. (Polymerase III is sensitive to 10 μg/ml of α-amanitin, whereas polymerase I is unaffected even at this higher concentration). [See R. G. Roeder, 1974, J. Biol. Chem. 249:241.]
 with a solution of constantly increasing NaCl concentration. Fractions containing the eluted proteins were assayed for the ability to transcribe DNA (red curve) in the presence of the four ribonucleoside triphosphates. The synthesis of RNA by each fraction in the presence of 1 μg/ml of α-amanitin also was measured (blue curve). At this concentration, α-amanitin inhibits polymerase II activity but has no effect on polymerases I and III. (Polymerase III is sensitive to 10 μg/ml of α-amanitin, whereas polymerase I is unaffected even at this higher concentration). [See R. G. Roeder, 1974, J. Biol. Chem. 249:241.]")
14
Inicio de transcripción.
La RNA pol II suele iniciar la transcripción en un par de bases específicos o alternativos cercanos a una plantilla. El nucleótido 5´que tienen el capuchón en un mRNA es el nucleótido en dónde inición la transcripción.

15
Iniciador en vez de caja TATA
Algunos genes no presentan caja TATA. Presentan una secuencia relativamente degenerada con A en +1, Y es una pirimidina, N es cualquier base. 5’Y-Y-A+1-NT/A-Y-Y-Y(3’) Instead of a TATA box, some eukaryotic genes contain an alternative promoter element called an initiator. Most naturally occurring initiator elements have a cytosine (C) at the -1 position and an adenine (A) residue at the transcription-start site (+1). Directed mutagenesis of mammalian genes with an initiator-containing promoter has revealed that the nucleotide sequence immediately surrounding the start site determines the strength of such promoters. Unlike the highly conserved TATA box sequence, however, only an extremely degenerate initiator consensus sequence has been defined: where A+1 is the base at which transcription starts, Y is either pyrimidine (C or T), N is any of the four bases, and T/A is T or A at position +3.
 Instead of a TATA box, some eukaryotic genes contain an alternative promoter element called an initiator. Most naturally occurring initiator elements have a cytosine (C) at the -1 position and an adenine (A) residue at the transcription-start site (+1). Directed mutagenesis of mammalian genes with an initiator-containing promoter has revealed that the nucleotide sequence immediately surrounding the start site determines the strength of such promoters. Unlike the highly conserved TATA box sequence, however, only an extremely degenerate initiator consensus sequence has been defined: where A+1 is the base at which transcription starts, Y is either pyrimidine (C or T), N is any of the four bases, and T/A is T or A at position +3.")
16
Hay genes que no presentan ni caja TATA ni Iniciador
Se presenta en genes de mantenimiento (housekeeping). Es una región de 20 a 200 pares de base Da origen a mensajeros con extremos 5´ múltiples. Son genes que generalmente se transcriben a bajas tasas. Presentan un segmento de 20 a 50 pb rico en GC Este sitio es reconocido por un factor de transcripción llamado SP1 transcription of many protein-coding genes has been shown to begin at any one of multiple possible sites over an extended region, often 20 – 200 base pairs in length. As a result, such genes give rise to mRNAs with multiple alternative 5′ ends. These genes, which generally are transcribed at low rates (e.g., genes encoding the enzymes of intermediary metabolism, often called “housekeeping genes”), do not contain a TATA box or an initiator. Most genes of this type contain a CG-rich stretch of 20 – 50 nucleotides within ≈100 base pairs upstream of the start-site region. As we discuss later, a transcription factor called SP1 recognizes these CG-rich sequences.
. Es una región de 20 a 200 pares de base. Da origen a mensajeros con extremos 5´ múltiples. Son genes que generalmente se transcriben a bajas tasas. Presentan un segmento de 20 a 50 pb rico en GC. Este sitio es reconocido por un factor de transcripción llamado SP1. transcription of many protein-coding genes has been shown to begin at any one of multiple possible sites over an extended region, often 20 – 200 base pairs in length. As a result, such genes give rise to mRNAs with multiple alternative 5′ ends. These genes, which generally are transcribed at low rates (e.g., genes encoding the enzymes of intermediary metabolism, often called housekeeping genes ), do not contain a TATA box or an initiator. Most genes of this type contain a CG-rich stretch of 20 – 50 nucleotides within ≈100 base pairs upstream of the start-site region. As we discuss later, a transcription factor called SP1 recognizes these CG-rich sequences.")
17
Islas CpG Las secuencias ricas en CG son pocas en el genoma eucariótico Estas regiones justo antes de un gen presentan una distribución no al azar. Pueden ser identificadas por su susceptibilidad a la enzima de restricción HpaII. La presencia de islas CpG sugiere una zona de iniciación de transcripción. The dinucleotide CG is statistically underrepresented in vertebrate DNAs, and the presence of CG-rich regions just upstream from start sites is a distinctly nonrandom distribution. Such CpG islands, as they often are called, can be identified by their susceptibility to restriction enzymes (e.g., HpaII) that have CG in their recognition sequences. The presence of a CpG island in a newly cloned DNA fragment suggests that it may contain a transcription-initiation region.
 that have CG in their recognition sequences. The presence of a CpG island in a newly cloned DNA fragment suggests that it may contain a transcription-initiation region.")
18
Figure Comparison of nucleotide sequences upstream of the start site in 60 different vertebrate protein-coding genes. Each sequence was aligned to maximize homology in the region from -35 to -20. The tabulated numbers are the percentage frequency of each base at each position. Maximum homology occurs over a six-base region, referred to as the TATA box, whose consensus sequence is shown at the bottom. The initial base in mRNAs encoded by genes containing a TATA box most frequently is an A. [See R. Breathnach and P. Chambon, 1981, Ann. Rev. Biochem. 50:349; P. Bucher, 1990,J. Mol. Biol. 212:563.]

19
Figure Analysis of linker scanning mutations to identify transcription-control elements. A region of eukaryotic DNA (yellow) that supports high level expression of a reporter gene (light blue) is cloned in a plasmid vector as diagrammed at the top. Overlapping linker scanning (LS) mutations (crosshatch) are introduced from one end of the region being analyzed to the other. These mutations result from scrambling the nucleotide sequence in a short stretch of the DNA. The mutant plasmids are transfected separately into cultured cells, and the activity of the reporter-gene product is assayed. In the hypothetical example shown here, LS mutations 1, 4, 6, 7, and 9 have little or no effect on expression of the reporter gene, indicating that the regions altered in these mutants contain no control elements. Reporter-gene expression is significantly reduced in mutants 2, 3, 5, and 8, indicating that control elements (brown) lie in the intervals shown at the bottom.
 that supports high level expression of a reporter gene (light blue) is cloned in a plasmid vector as diagrammed at the top. Overlapping linker scanning (LS) mutations (crosshatch) are introduced from one end of the region being analyzed to the other. These mutations result from scrambling the nucleotide sequence in a short stretch of the DNA. The mutant plasmids are transfected separately into cultured cells, and the activity of the reporter-gene product is assayed. In the hypothetical example shown here, LS mutations 1, 4, 6, 7, and 9 have little or no effect on expression of the reporter gene, indicating that the regions altered in these mutants contain no control elements. Reporter-gene expression is significantly reduced in mutants 2, 3, 5, and 8, indicating that control elements (brown) lie in the intervals shown at the bottom..")
22
Figure 10-33. Identification of SV40 enhancer region
Figure Identification of SV40 enhancer region. Plasmids containing the β-globin gene with or without a 366-bp fragment of SV40 DNA were constructed. Each plasmid was transfected separately into cultured fibroblasts, which do not normally express β-globin (step 1 ). The amount of β-globin mRNA synthesized by transfected cells was assayed by the S1 nuclease-protection method (see Figure 7-36b). The probe used in this assay was a restriction fragment, generated from a β-globin cDNA clone, that was complementary to the 5′ end of β-globin mRNA (step 2 ). The 5′ end of the probe was labeled with 32P (red dot). When β-globin mRNA hybridized to the probe, an ≈340-nucleotide fragment of the probe was protected from digestion by S1 nuclease (step 3 ). Autoradiography of electrophoresed S1-protected fragments (step 4 ) revealed that cells transfected with plasmid 1 (lane 1) produced much more β-globin mRNA than those transfected with plasmid 2 (lane 2). Lane C is a control assay of β-globin mRNA isolated from reticulocytes, which actively synthesize β-globin. These results show that the SV40 DNA fragment contains an element, called an enhancer, that greatly stimulates synthesis of β-globin mRNA. [Adapted from J. Banerji et al., 1981, Cell 27:299.]
. The amount of β-globin mRNA synthesized by transfected cells was assayed by the S1 nuclease-protection method (see Figure 7-36b). The probe used in this assay was a restriction fragment, generated from a β-globin cDNA clone, that was complementary to the 5′ end of β-globin mRNA (step 2 ). The 5′ end of the probe was labeled with 32P (red dot). When β-globin mRNA hybridized to the probe, an ≈340-nucleotide fragment of the probe was protected from digestion by S1 nuclease (step 3 ). Autoradiography of electrophoresed S1-protected fragments (step 4 ) revealed that cells transfected with plasmid 1 (lane 1) produced much more β-globin mRNA than those transfected with plasmid 2 (lane 2). Lane C is a control assay of β-globin mRNA isolated from reticulocytes, which actively synthesize β-globin. These results show that the SV40 DNA fragment contains an element, called an enhancer, that greatly stimulates synthesis of β-globin mRNA. [Adapted from J. Banerji et al., 1981, Cell 27:299.]")
24
El enhancer del SV40 Estimula la transcripción de proteínas virales en la infección. Estimula la transcripción de todos los genes eucariontes en que se ha probado. Funciona en cualquier orientación Funciona hasta a miles de pares de bases de sitio de iniciación Está compuesto de muchos elementos individuales que contribuyen individualmente a la actividad. In SV40, this enhancer sequence functions to stimulate transcription from viral promoters. The SV40 enhancer, however, stimulates transcription from all mammalian promoters that have been tested when it is inserted in either orientation anywhere on a plasmid carrying the test promoter, even when it is thousands of base pairs from the start site. An extensive linker scanning mutational analysis of the SV40 enhancer indicated that it is composed of multiple individual elements each of which contributes to the total activity of the enhancer. As discussed later, each of these regulatory elements is a protein-binding site.

25
Características de los enhancers
Se han encontrado a más de 50 kilobases del promotor que controlan. Pueden estar río arriba del promotor, río abajo del promotor, dentro de un intrón o de un exón o hasta después del último exón. Algunos son específicos de un tipo celular. En los genes de las inmunoglobulinas en los linfocitos B, hay un enhancer dentro del segundo intrón pero funciona solo en linfos B. Some of these control elements were located 50 or more kilobases from the promoter they controlled. Analyses of many different eukaryotic cellular enhancers have shown that they can occur upstream from a promoter, downstream from a promoter within an intron, or even downstream from the final exon of a gene. Like promoter-proximal elements, many enhancers are cell-type specific. For example, the genes encoding antibodies (immunoglobulins) contain an enhancer within the second intron that can stimulate transcription from all promoters tested, but only in B lymphocytes, the type of cells that normally express antibodies. Analyses of the effects of deletions and linker scanning mutations in cellular enhancers have shown that, like the SV40 enhancer, they generally are composed of multiple elements that contribute to the overall activity of the enhancer.
 contain an enhancer within the second intron that can stimulate transcription from all promoters tested, but only in B lymphocytes, the type of cells that normally express antibodies. Analyses of the effects of deletions and linker scanning mutations in cellular enhancers have shown that, like the SV40 enhancer, they generally are composed of multiple elements that contribute to the overall activity of the enhancer.")
26
Elementos de control cercanos y lejanos
Se creía que eran diferentes Se pueden invertir su colocación y siguen estimulando la transcripción. Son célula específico Ahora se piensa que son un espectro de elementos de control que regulan la transcripción. Initially, enhancers and promoter-proximal elements were thought to be distinct types of transcription-control elements. However, as more enhancers and promoter-proximal elements were analyzed, the distinctions between them became less clear. For example, both types of element generally can stimulate transcription even when inverted, and both types often are cell-type specific. The general consensus now is that a spectrum of control elements regulate transcription by RNA polymerase II. At one extreme are enhancers, which can stimulate transcription from a promoter tens of thousands of base pairs away (e.g., the SV40 enhancer). At the other extreme are promoter-proximal elements, such as the upstream elements controlling the HSV tk gene, which lose their influence when moved an additional 30 – 50 base pairs farther from the promoter. Researchers have identified a large number of transcription-control elements that can stimulate transcription from distances between these two extremes.
. At the other extreme are promoter-proximal elements, such as the upstream elements controlling the HSV tk gene, which lose their influence when moved an additional 30 – 50 base pairs farther from the promoter. Researchers have identified a large number of transcription-control elements that can stimulate transcription from distances between these two extremes.")
27
Figure General pattern of cis-acting control elements that regulate gene expression in yeast and multicellular organisms (invertebrates, vertebrates, and plants). (a) Genes of multicellular organisms contain both promoter-proximal elements and enhancers as well as a TATA box or other promoter element. The latter positions RNA polymerase II to initiate transcription at the start site and influences the rate of transcription. Enhancers may be either upstream or downstream and as far away as 50 kb from the transcription start site. In some cases, promoter-proximal elements occur downstream from the start site as well. (b) Most yeast genes contain only one regulatory region, called an upstream activating sequence (UAS), and a TATA box, which is ≈90 base pairs upstream from the start site.
. (a) Genes of multicellular organisms contain both promoter-proximal elements and enhancers as well as a TATA box or other promoter element. The latter positions RNA polymerase II to initiate transcription at the start site and influences the rate of transcription. Enhancers may be either upstream or downstream and as far away as 50 kb from the transcription start site. In some cases, promoter-proximal elements occur downstream from the start site as well. (b) Most yeast genes contain only one regulatory region, called an upstream activating sequence (UAS), and a TATA box, which is ≈90 base pairs upstream from the start site..")
28
Resumen La expresión de los genes que codifican para proteínas en eucariontes están regulado por múltiples regiones de control que actúan en cis. Algunos de estos elementos de control son cercanos al sitio de inicio y otros lejanos. Los promotores determinan el sitio de inicio de transcripción y dirigen la unión de la RNA polimentasa II. Expression of eukaryotic protein-coding genes generally is regulated through multiple cis-acting transcription- control regions (see Figure 10-34). Some control elements are located close to the start site (promoter-proximal elements), whereas others lie more distant (enhancers). Promoters determine the site of transcription initiation and direct binding of RNA polymerase II. Three types of promoter sequences have been identified in eukaryotic DNA. The TATA box, the most common, is prevalent in rapidly transcribed genes. Initiator promoters infrequently are found in some genes, and CpG islands are characteristic of transcribed genes. Promoter-proximal elements occur within ≈200 base pairs of the start site. Several such elements, containing up to ≈20 base pairs, may help regulate a particular gene. Enhancers, which are usually ≈100 – 200 base pairs in length, contain multiple 8- to 20-bp control elements. They may be located from 200 base pairs to tens of kilobases upstream or downstream from a promoter, within an intron, or downstream from the final exon of a gene. Promoter-proximal elements and enhancers often are cell-type specific, functioning only in specific differentiated cell types.
. Some control elements are located close to the start site (promoter-proximal elements), whereas others lie more distant (enhancers). Promoters determine the site of transcription initiation and direct binding of RNA polymerase II. Three types of promoter sequences have been identified in eukaryotic DNA. The TATA box, the most common, is prevalent in rapidly transcribed genes. Initiator promoters infrequently are found in some genes, and CpG islands are characteristic of transcribed genes. Promoter-proximal elements occur within ≈200 base pairs of the start site. Several such elements, containing up to ≈20 base pairs, may help regulate a particular gene. Enhancers, which are usually ≈100 – 200 base pairs in length, contain multiple 8- to 20-bp control elements. They may be located from 200 base pairs to tens of kilobases upstream or downstream from a promoter, within an intron, or downstream from the final exon of a gene. Promoter-proximal elements and enhancers often are cell-type specific, functioning only in specific differentiated cell types.")
29
Resumen Se han identificado tres tipos de secuencias promotoras en eucariontes. Caja TATA Promotores diferentes poco frecuentes Islas CpG Expression of eukaryotic protein-coding genes generally is regulated through multiple cis-acting transcription- control regions (see Figure 10-34). Some control elements are located close to the start site (promoter-proximal elements), whereas others lie more distant (enhancers). Promoters determine the site of transcription initiation and direct binding of RNA polymerase II. Three types of promoter sequences have been identified in eukaryotic DNA. The TATA box, the most common, is prevalent in rapidly transcribed genes. Initiator promoters infrequently are found in some genes, and CpG islands are characteristic of transcribed genes.
. Some control elements are located close to the start site (promoter-proximal elements), whereas others lie more distant (enhancers). Promoters determine the site of transcription initiation and direct binding of RNA polymerase II. Three types of promoter sequences have been identified in eukaryotic DNA. The TATA box, the most common, is prevalent in rapidly transcribed genes. Initiator promoters infrequently are found in some genes, and CpG islands are characteristic of transcribed genes.")
30
Los elementos proximales
Están dentro de los ≈200 pares de bases. Contiene hasta 20 pares de bases cada uno. Promoter-proximal elements occur within ≈200 base pairs of the start site. Several such elements, containing up to ≈20 base pairs, may help regulate a particular gene.

31
Los enhancers, Usualmente contienen entre 100 y 200 pb de longitud. Tienen elementos de control individuales de 8 a 20 pb. Se localizan a más de 200 y hasta decenas de kilobases río arriba o abajo del promotor. Puede estar dentro de un intron o más lejos del último exón del gen. Enhancers, which are usually ≈100 – 200 base pairs in length, contain multiple 8- to 20-bp control elements. They may be located from 200 base pairs to tens of kilobases upstream or downstream from a promoter, within an intron, or downstream from the final exon of a gene. Promoter-proximal elements and enhancers often are cell-type specific, functioning only in specific differentiated cell types.

32
Aislamiento bioquímico de los factores de transcripción
Una vez que el elemento regulatorio se ha identificado por análisis mutacional, Se puede: Identificar a la proteína cognada que se une específicamente a ella. En esta técnica, un extracto del núcleo se pasa por varias cromatografías y se realiza un footprinting con Dnasa tipo I o un ensayo de cambio en la movilidad electroforética (EMSA) Once a DNA regulatory element has been identified by the kinds of mutational analyses described in the previous section, it can be used to identify cognate proteins that bind specifically to it. In this approach, an extract of cell nuclei is subjected to several chromatographic steps (Figure 10-35a); fractions are assayed by DNase I footprinting or an electrophoretic mobility shift assay using DNA fragments containing the identified regulatory element (see Figures 10-6 and 10-7).
 Once a DNA regulatory element has been identified by the kinds of mutational analyses described in the previous section, it can be used to identify cognate proteins that bind specifically to it. In this approach, an extract of cell nuclei is subjected to several chromatographic steps (Figure 10-35a); fractions are assayed by DNase I footprinting or an electrophoretic mobility shift assay using DNA fragments containing the identified regulatory element (see Figures 10-6 and 10-7).")
33
Las fracciones que contienen proteínas que se unen a elementos regulatorios probablemente contienen factores putativos de transcripción. La técnica más poderosa para purificar factores de transcripción es la cromatografía de afinidad en dónde se inmovilizan las secuencias de los elementos regulatorios a un soporte. Fractions containing protein that binds to the regulatory element in these assays probably contain a putative transcription factor (Figure 10-35b). A powerful technique commonly used for the final step in purifying transcription factors is sequence-specific DNA affinity chromatography, a particular type of affinity chromatography (Section 3.5). As a final test, the ability of the isolated protein to stimulate transcription of a template containing the corresponding protein-binding sites is assayed in an in vitro transcription reaction (Figure 10-36).
. A powerful technique commonly used for the final step in purifying transcription factors is sequence-specific DNA affinity chromatography, a particular type of affinity chromatography (Section 3.5). As a final test, the ability of the isolated protein to stimulate transcription of a template containing the corresponding protein-binding sites is assayed in an in vitro transcription reaction (Figure 10-36).")
34
Figure 10-35. Transcription-factor purification
Figure Transcription-factor purification. (a) Several chromatographic steps are used to purify a transcription factor (cognate protein) that binds to a specific regulatory element in DNA. Final purification is obtained by affinity chromatography on a column that is coupled to long DNA strands containing multiple copies of the transcription factor–binding site. A partially purified protein preparation containing the transcription factor is applied to the column in a low-salt buffer (100 mM KCl). Proteins that do not bind to the specific binding site are washed off the column with additional low-salt buffer. Proteins with low affinity for the binding site are eluted with an intermediate salt concentration buffer (e.g., 300 mM KCl). Finally, highly purified transcription factor is eluted with a high salt concentration buffer (e.g., 1 M KCl). (b) Proteins separated by column chromatography are assayed for their ability to bind to an identified regulatory element. In this example, DNase I footprinting assays of protein fractions eluted from an ion-exchange column indicate that the transcription factor of interest is in fractions 9 – 12. Specific DNA-binding proteins can also be conveniently assayed by EMSA (see Figure 10-7). [For sequence-specific DNA-affinity chromatography see J. T. Kadonaga and R. Tjian, 1986, Proc. Nat’l. Acad. Sci. USA 83:5889. Part (b) from S. Yoshinage et at., 1989,J. Biol. Chem. 264:10529.]
 Several chromatographic steps are used to purify a transcription factor (cognate protein) that binds to a specific regulatory element in DNA. Final purification is obtained by affinity chromatography on a column that is coupled to long DNA strands containing multiple copies of the transcription factor–binding site. A partially purified protein preparation containing the transcription factor is applied to the column in a low-salt buffer (100 mM KCl). Proteins that do not bind to the specific binding site are washed off the column with additional low-salt buffer. Proteins with low affinity for the binding site are eluted with an intermediate salt concentration buffer (e.g., 300 mM KCl). Finally, highly purified transcription factor is eluted with a high salt concentration buffer (e.g., 1 M KCl). (b) Proteins separated by column chromatography are assayed for their ability to bind to an identified regulatory element. In this example, DNase I footprinting assays of protein fractions eluted from an ion-exchange column indicate that the transcription factor of interest is in fractions 9 – 12. Specific DNA-binding proteins can also be conveniently assayed by EMSA (see Figure 10-7). [For sequence-specific DNA-affinity chromatography see J. T. Kadonaga and R. Tjian, 1986, Proc. Nat’l. Acad. Sci. USA 83:5889. Part (b) from S. Yoshinage et at., 1989,J. Biol. Chem. 264:10529.]")
35
Si la transcripción del gen reportero es mayor en presencia de l plásmido que codifica para la proteína X, esta es un activador. Si es menor, X es un represor. Figure In vivo assay for transcription factor activity. The assay system requires two plasmids. One plasmid contains the gene encoding the putative transcription factor (X protein). The second plasmid contains a reporter gene and one or more binding sites for X protein. Both plasmids are simultaneously introduced into host cells that lack the gene encoding X protein and the reporter gene. The production of reporter-gene RNA transcripts is measured; alternatively, the activity of the encoded protein can be assayed. If reporter-gene transcription is greater in the presence of the X-encoding plasmid, then the protein is an activator; if transcription is less, then it is a repressor. By use of plasmids encoding a mutated or rearranged transcription factor, important domains of the protein can be identified.
. The second plasmid contains a reporter gene and one or more binding sites for X protein. Both plasmids are simultaneously introduced into host cells that lack the gene encoding X protein and the reporter gene. The production of reporter-gene RNA transcripts is measured; alternatively, the activity of the encoded protein can be assayed. If reporter-gene transcription is greater in the presence of the X-encoding plasmid, then the protein is an activator; if transcription is less, then it is a repressor. By use of plasmids encoding a mutated or rearranged transcription factor, important domains of the protein can be identified.")
36
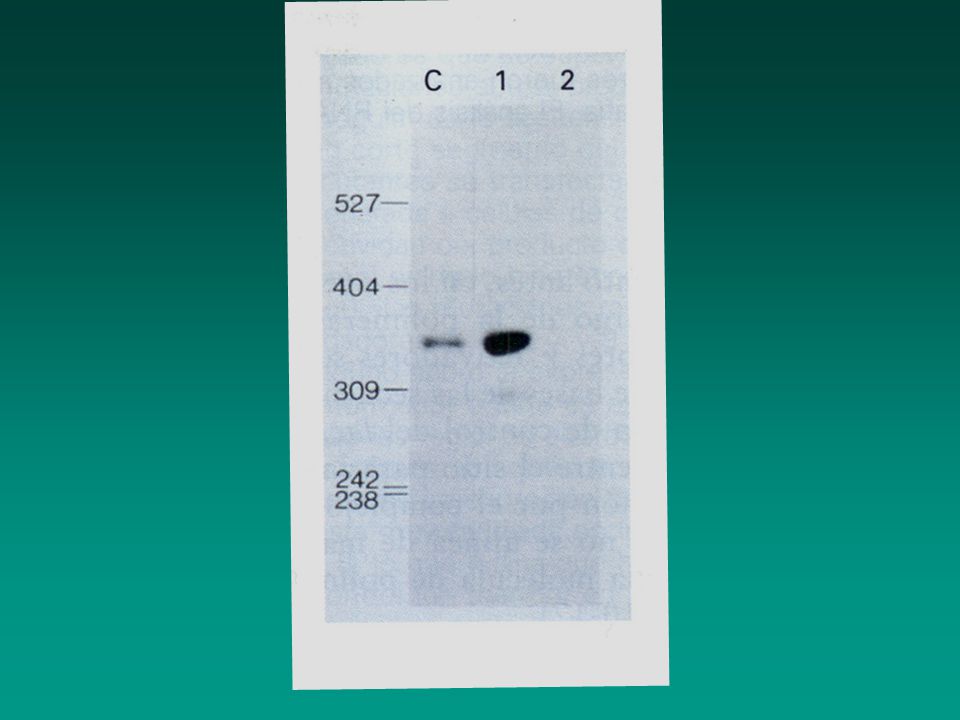
Figure Results of an electrophoretic mobility shift assay (EMSA) for DNA-binding proteins. In this example, fractions from an ion-exchange column were assayed for a protein that binds to the promoter region of a eukaryotic tRNA gene. An aliquot of the protein fraction loaded onto the column (ON) and of fractions eluted off the column with increasing salt concentration (numbers) were incubated with a radiolabeled restriction-fragment probe that included the promoter region; each sample was then subjected to electrophoresis through a polyacrylamide gel. Free probe not bound by protein migrated to the bottom of the gel. A protein in column fractions 7 and 8 bound to the probe, forming a DNA-protein complex that migrated more slowly than the free probe (arrow). [From S. Yoshinaga et al., 1989, J. Biol. Chem. 264:10529.]
 and of fractions eluted off the column with increasing salt concentration (numbers) were incubated with a radiolabeled restriction-fragment probe that included the promoter region; each sample was then subjected to electrophoresis through a polyacrylamide gel. Free probe not bound by protein migrated to the bottom of the gel. A protein in column fractions 7 and 8 bound to the probe, forming a DNA-protein complex that migrated more slowly than the free probe (arrow). [From S. Yoshinaga et al., 1989, J. Biol. Chem. 264:10529.].")
37
Figure DNase I footprinting, a common technique for identifying protein-binding sites in DNA. (Top) A DNA fragment is labeled at one end with 32P (red dot) as in the Maxam-Gilbert sequencing method (see Figure 7-25). Portions of the sample then are digested with DNase I in the presence and absence of a protein that binds to a specific sequence in the fragment. DNase I randomly hydrolyzes the phosphodiester bonds of DNA between the 3′ oxygen on the deoxyribose of one nucleotide and the 5′ phosphate of the next nucleotide. A low concentration of DNase I is used so that on average each DNA molecule is cleaved just once (vertical arrows). In the absence of a DNA-binding protein, the sample is cleaved at all possible positions between the labeled and unlabeled ends of the original fragment. The two samples of DNA then are separated from protein, denatured to separate the strands, and electrophoresed. The resulting gel is analyzed by autoradiography, which detects only labeled strands and reveals fragments extending from the labeled end to the site of cleavage by DNase I. (Bottom) Diagram of hypothetical autoradiogram of the gel for the minus protein sample above reveals bands corresponding to all possible fragments produced by DNase I cleavage (-lane). In the sample digested in the presence of a DNA-binding protein, two bands are missing (+lane); these correspond to the DNA region protected from digestion by bound protein and are referred to as the footprint of that protein. This protected region can be precisely aligned with the DNA sequence if sequencing reactions are performed on the original end-labeled DNA and the products electrophoresed on the same gel. In this example, the products of four Maxam-Gilbert sequencing reactions are shown.
 A DNA fragment is labeled at one end with 32P (red dot) as in the Maxam-Gilbert sequencing method (see Figure 7-25). Portions of the sample then are digested with DNase I in the presence and absence of a protein that binds to a specific sequence in the fragment. DNase I randomly hydrolyzes the phosphodiester bonds of DNA between the 3′ oxygen on the deoxyribose of one nucleotide and the 5′ phosphate of the next nucleotide. A low concentration of DNase I is used so that on average each DNA molecule is cleaved just once (vertical arrows). In the absence of a DNA-binding protein, the sample is cleaved at all possible positions between the labeled and unlabeled ends of the original fragment. The two samples of DNA then are separated from protein, denatured to separate the strands, and electrophoresed. The resulting gel is analyzed by autoradiography, which detects only labeled strands and reveals fragments extending from the labeled end to the site of cleavage by DNase I. (Bottom) Diagram of hypothetical autoradiogram of the gel for the minus protein sample above reveals bands corresponding to all possible fragments produced by DNase I cleavage (-lane). In the sample digested in the presence of a DNA-binding protein, two bands are missing (+lane); these correspond to the DNA region protected from digestion by bound protein and are referred to as the footprint of that protein. This protected region can be precisely aligned with the DNA sequence if sequencing reactions are performed on the original end-labeled DNA and the products electrophoresed on the same gel. In this example, the products of four Maxam-Gilbert sequencing reactions are shown..")
38
Figure Experimental demonstration of separate functional domains in yeast Gal4 protein. (a) Diagram of DNA construct containing a lacZ reporter gene with an added TATA box ligated to UASGAL, a regulatory element that contains several Gal4-binding sites. The reporter-gene construct and DNA encoding wild-type or mutant Gal4 were simultaneously introduced into mutant (gal4) yeast cells and the β-galactosidase activity was assayed. Activity will be high if the introduced GAL4 DNA encodes a functional protein. (b) Schematic diagrams of wild-type Gal4 and various mutant forms. Small numbers refer to positions in the wild-type sequence. Deletion of 50 amino acids from the N-terminal end destroyed the ability of Gal4 to bind to UASGAL and to stimulate expression of β-galactosidase from the reporter gene. Proteins with extensive deletions from the C-terminal end still bound to UASGAL. These results localize the DNA-binding domain to the N-terminal end of Gal4. Proteins with a deletion of 58 amino acids from the C-terminal end had no decrease in the ability to stimulate expression of β-galactosidase; those with a deletion of 89 amino acids exhibited a small decrease. The ability to activate β-galactosidase expression was not entirely eliminated unless 126–189 or more amino acids were deleted. Thus, the activation domain lies in the C-terminal region of Gal4. Deleted proteins containing the N-terminal and C-terminal segments also were able to stimulate expression of β-galactosidase, indicating that the central region of Gal4 is not crucial for its function in this assay. [See J. Ma and M. Ptashne, 1987, Cell 48:847; I. A. Hope and K. Struhl, 1986,Cell 46:885; and R. Brent and M. Ptashne, 1985,Cell 43:729.]
 Diagram of DNA construct containing a lacZ reporter gene with an added TATA box ligated to UASGAL, a regulatory element that contains several Gal4-binding sites. The reporter-gene construct and DNA encoding wild-type or mutant Gal4 were simultaneously introduced into mutant (gal4) yeast cells and the β-galactosidase activity was assayed. Activity will be high if the introduced GAL4 DNA encodes a functional protein. (b) Schematic diagrams of wild-type Gal4 and various mutant forms. Small numbers refer to positions in the wild-type sequence. Deletion of 50 amino acids from the N-terminal end destroyed the ability of Gal4 to bind to UASGAL and to stimulate expression of β-galactosidase from the reporter gene. Proteins with extensive deletions from the C-terminal end still bound to UASGAL. These results localize the DNA-binding domain to the N-terminal end of Gal4. Proteins with a deletion of 58 amino acids from the C-terminal end had no decrease in the ability to stimulate expression of β-galactosidase; those with a deletion of 89 amino acids exhibited a small decrease. The ability to activate β-galactosidase expression was not entirely eliminated unless 126–189 or more amino acids were deleted. Thus, the activation domain lies in the C-terminal region of Gal4. Deleted proteins containing the N-terminal and C-terminal segments also were able to stimulate expression of β-galactosidase, indicating that the central region of Gal4 is not crucial for its function in this assay. [See J. Ma and M. Ptashne, 1987, Cell 48:847; I. A. Hope and K. Struhl, 1986,Cell 46:885; and R. Brent and M. Ptashne, 1985,Cell 43:729.].")
39
Figure Schematic diagrams illustrating the modular structure of eukaryotic transcription activators. These transcription factors may contain more than one activation domain but rarely contain more than one DNA-binding domain. Gal4 and Gcn4 are yeast transcription activators. The glucocorticoid receptor (GR), which also contains a hormone-binding domain (not shown), activates transcription of target genes in the presence of certain hormones. SP1 binds to GC-rich promoter elements in a large number of mammalian genes. The relatively unstructured, highly flexible protein domains in activators are extremely sensitive to digestion by proteases.
, which also contains a hormone-binding domain (not shown), activates transcription of target genes in the presence of certain hormones. SP1 binds to GC-rich promoter elements in a large number of mammalian genes. The relatively unstructured, highly flexible protein domains in activators are extremely sensitive to digestion by proteases..")
40
Clasificación de los dominios de unión al DNA
Proteínas con: Homeodominio Proteínas con dedos de zinc Hélice alada (en lengüeta de flecha) Con cremallera o zipper de leucina Con hélice-bucle-hélice
 Con cremallera o zipper de leucina. Con hélice-bucle-hélice.")
41
Homeodominio Proteína de Engrailed de Drosophila
Nombre de genes homeóticos (produce la transformación de una parte del cuerpo en otro en el desarrollo. Región de 60 residuos de aa muy conservada

43
Figure Homeodomain from Engrailed protein interacting with its specific DNA recognition site. The Engrailed transcription factor is expressed during Drosophila embryogenesis. Base pairs in the recognition site that directly contact the protein are shown in white type. Lighter regions in the protein contain residues that contact the major groove. [Adapted from S. C. Harrison, 1991, Nature 353:715.]

44
Proteínas con dedos de zinc
Dominio estructurado con un ion Zn2+ en el centro de un plegamiento de residuos de aa. Secuencia consenso Tyr/Phe-Cys-X2-4-Cys-X3-Phe/Tyr-X5-Leu-X2-His-X3-4-His La forma de dedo se ve en un diagrama bidimensional El zinc se fija entre las 2 Cys y la 2 His. Se le llama dedo C2H2

45
Proteínas con dedos de zinc
El alfa-hélice que se forma es muy compacto Se inserta en el surco mayor del DNA Otro tipo de dedos de zinc C4 se encuentra en otros factores de trascripción (receptores a esteroides-nucleares) Cys-X2-Cys-X13-Cys-X2-Cys-X14-15-Cys-X5-Cys-X9-Cys-X2-Cys
 Cys-X2-Cys-X13-Cys-X2-Cys-X14-15-Cys-X5-Cys-X9-Cys-X2-Cys.")
46
Proteínas con dedos de zinc
Los dominios C2H2 y C4 son estructuralmente distintos. Los C2H2 tienen tres dedos repetitivos o más y se fijan como monómeros. Los C4 tienen en general dos dedos y se fijan como homodímeros o heterodímeros. Con simetría rotacional doble (fig. siguiente b)
")
47
Dedos de zinc C2H2 (a)y C4(b)
Figure Interaction of C2H2 and nuclear receptor (C4) zinc-finger domains with DNA (blue). (a) A five-finger C2H2 protein called GL1. This monomeric protein is encoded by a gene that is amplified in a number of human tumors. Helical regions are represented by cylinders, and β strands by broad ribbons. Finger 1 does not interact with DNA, whereas the other four fingers do. Small black circles indicate Zn2+ ions. (b) The glucocorticoid receptor, a homodimeric C4 protein. Helical regions are shown as spirals, and β strands as broad arrows. Two α helices (darker shade), one in each monomer, interact with the DNA. Like all C4 zinc-finger homodimers, this transcription factor has twofold rotational symmetry; the center of symmetry is shown by the yellow ellipse. Black circles indicate Zn2+ ions. [Part (a) adapted from N. P. Pavletich and C. O. Pabo, 1993, Science 261:1701; part (b) adapted from B. F. Luisi et al., 1991,Nature 352:497.] Proteína GL1 Receptor a glucocorticoides
 zinc-finger domains with DNA (blue). (a) A five-finger C2H2 protein called GL1. This monomeric protein is encoded by a gene that is amplified in a number of human tumors. Helical regions are represented by cylinders, and β strands by broad ribbons. Finger 1 does not interact with DNA, whereas the other four fingers do. Small black circles indicate Zn2+ ions. (b) The glucocorticoid receptor, a homodimeric C4 protein. Helical regions are shown as spirals, and β strands as broad arrows. Two α helices (darker shade), one in each monomer, interact with the DNA. Like all C4 zinc-finger homodimers, this transcription factor has twofold rotational symmetry; the center of symmetry is shown by the yellow ellipse. Black circles indicate Zn2+ ions. [Part (a) adapted from N. P. Pavletich and C. O. Pabo, 1993, Science 261:1701; part (b) adapted from B. F. Luisi et al., 1991,Nature 352:497.] Proteína GL1. Receptor a glucocorticoides.")
48
Interacción entre Gal4 y el DNA
Proteína con dedos de zinc C6 . Es un homodímero que se forma por una hélice enrollada . Figure Trace diagram of interaction between Gal4, a C6 zinc-finger protein, and DNA. This protein binds DNA as a homodimer with the monomers interacting to form a coiled coil that lies perpendicular to the DNA helix. Binding of cysteine residues to two Zn2+ ions (yellow) in each monomer forms two globular domains that interact with DNA. [From R. Marmorstein et al., 1992, Nature 356:408.]
 in each monomer forms two globular domains that interact with DNA. [From R. Marmorstein et al., 1992, Nature 356:408.]")
49
Proteínas con hélice alada
Dominios de fijación de la histona H5 Se unen al DNA como monómeros Pueden unirse al DNA Z.

50
Estructura cristalina del dominio de unión al DNA Z de la proteína Dlm-1 unida al DNA.

51
Cremallera o zipper de leucina
Hay un residuo de leucina cada 7 aminoácidos en la región C terminal del dominio de unión. Se unen al DNA en forma de dímeros, la leucina es necesaria para la dimerización. Presenta dos a-hélices extendidas que agarran al DNA como pinzas en dos surcos mayores en la región N terminal. Pueden ser homodímeros o heterodímeros.

52
Interacción de Gnc4 con el DNA
Figure Two views of the interaction of yeast Gcn4, a homodimeric leucine-zipper protein, with DNA. The extended α-helical regions of the monomers grip the DNA at adjacent major grooves. The coiled-coil dimerization domain in Gcn4 contains precisely spaced leucine residues. Some DNA-binding proteins with this same general motif contain other hydrophobic amino acids in these positions; hence, this structural motif is generally called a basic zipper. [From T. E. Ellenberger et al., 1992, Cell 71:1223.]

53
Hélice bucle hélice Un bucle no helicoidal de la cadena polipeptídica separa dos regiones a-helicoidales. Tienen aminoácidos básicos para aumentar la interacción con el DNA.

54
Interacción de un dominio hélice-bucle-hélice con el DNA
Figure Interaction of the helix-loop-helix domain in the homodimeric Max protein with DNA. The helix-loophelix motif extends from the DNA-binding helices on the left (N-termini of the monomers) to approximately where the chains first cross; this is followed immediately by a leucine-zipper coiled-coil region in the dimeric protein. [See A. R. Ferre-D’Amare et al., 1993, Nature 363:38; courtesy of A. R. Ferre-D´ Amare and S. K. Burley.]
 to approximately where the chains first cross; this is followed immediately by a leucine-zipper coiled-coil region in the dimeric protein. [See A. R. Ferre-D’Amare et al., 1993, Nature 363:38; courtesy of A. R. Ferre-D´ Amare and S. K. Burley.]")
55
Los factores de transcripción heterodiméricos aumentan las opciones de control génico.
Cada monómero tiene un dominio de fijación al DNA con especificidad de secuencia equivalente. No influye en la unión al DNA. Permite que los dominios de activación asociados con cada monómero se reúnan para formar un solo factor de transcripción.

56
Figure Combinatorial possibilities due to formation of heterodimeric transcription factors. (a) In the hypothetical example shown, transcription factors A, B, and C can each interact with each other, permitting the three factors to bind to six different DNA sequences (sites 1–6) and creating six combinations of activation domains. (Note that each binding site is divided into two half-sites, and that a single heterodimeric factor contains the activation domains of each of its constituent monomers.) Four different factor monomers could combine to make 10 homo- and heterodimeric factors; five monomers could make 15 dimeric factors; and so forth. (b) When an inhibitory factor (green) is expressed that interacts only with factor A, binding to sites 1, 4, and 5 is inhibited, but binding to sites 2, 3, and 6 is unaffected.
 In the hypothetical example shown, transcription factors A, B, and C can each interact with each other, permitting the three factors to bind to six different DNA sequences (sites 1–6) and creating six combinations of activation domains. (Note that each binding site is divided into two half-sites, and that a single heterodimeric factor contains the activation domains of each of its constituent monomers.) Four different factor monomers could combine to make 10 homo- and heterodimeric factors; five monomers could make 15 dimeric factors; and so forth. (b) When an inhibitory factor (green) is expressed that interacts only with factor A, binding to sites 1, 4, and 5 is inhibited, but binding to sites 2, 3, and 6 is unaffected..")
57
Dominios de activación
Secuencia polipeptídica que activa la transcripción cuando está fusionada a un dominio de fijación del DNA Muchos dominios pueden activar la transcripción. Casi el 1% de las proteínas de fusión resultantes (Gal4 y segmento al azar) activaron la transcripción de un gen con UASgal en 5´.
 activaron la transcripción de un gen con UASgal en 5´.")
58
Figure Structure of the phosphorylated CREB acidic activation domain complexed to the interacting domain of its co-activator, CBP. The polypeptide backbone of the phosphorylated CREB acidic activation domain is represented as a pink spiral. Amino acid residues in CREB that interact with the surface of CBP are indicated by the single-letter abbreviations. The water-accessible surface of the interacting domain of CBP is represented at the back of the figure with regions of positive and negative electrical potential shaded blue and red, respectively (see Figure 3-4 for a comparison of this type of surface representation to other representations of protein structure). [From I. Radhakrishnan et al., 1997, Cell 91:741; courtesy of Peter Wright.]
. [From I. Radhakrishnan et al., 1997, Cell 91:741; courtesy of Peter Wright.].")
59
Figure Model of the enhancesome that forms on the β-interferon enhancer. Heterodimeric cJun/ATF-2, IRF-3, IRF-7, and NF-κB (a heterodimer of p50 and p65) bind to the four control elements in the ≈70-bp enhancer. Cooperative binding of these transcription factors is facilitated by HMGI, which binds to the minor groove of DNA. The cJun, ATF-2, p50, and p65 proteins all appear to interact directly with an HMGI bound adjacent to them. Bending of the enhancer sequence resulting from HMGI binding is critical to formation of an enhancesome. Different DNA-bending proteins act similarly at other enhancers. [Adapted from D. Thanos and T. Maniatis, 1995, Cell 83:1091 and M. A. Wathel et al., 1998,Mol. Cell 1:507.]
 bind to the four control elements in the ≈70-bp enhancer. Cooperative binding of these transcription factors is facilitated by HMGI, which binds to the minor groove of DNA. The cJun, ATF-2, p50, and p65 proteins all appear to interact directly with an HMGI bound adjacent to them. Bending of the enhancer sequence resulting from HMGI binding is critical to formation of an enhancesome. Different DNA-bending proteins act similarly at other enhancers. [Adapted from D. Thanos and T. Maniatis, 1995, Cell 83:1091 and M. A. Wathel et al., 1998,Mol. Cell 1:507.].")
60
Figure Diagram of the control region of the gene encoding EGR-1, a transcription activator. The binding sites for WT1, an eukaryotic repressor protein, do not overlap the binding sites for SRF and AP1, two ubiquitous activators, or the start site. Thus repression by WT1 does not involve interference with binding of other proteins.

Presentaciones similares





















 Falta el enzima Phehidroxilasa No se produce Tyr.>")
