Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Análisis Estadístico de Datos Climáticos
Análisis de agrupamiento (o clusters) M. Barreiro – M. Bidegain – A. Díaz Facultad de Ciencias – Facultad de Ingeniería 2009
 M. Barreiro – M. Bidegain – A. Díaz. Facultad de Ciencias – Facultad de Ingeniería")
2
Objetivo Idear una clasificación o esquema de agrupación que permita dividir datos en grupos o clases, llamados agrupamientos o clusters, de modo que los datos que estén dentro de una clase o grupo sean “semejantes” entre sí, u “homogéneos”, en tanto que los que pertenezcan a grupos diferentes no sean “semejantes” a los de los otros grupos. (“cohesión interna y aislamiento externo”) Nota: no debe confundirse este método con el análisis discriminante, en el cual, desde un principio se sabe cuántos grupos existen, y se tienen datos que provienen de cada uno de estos grupos.
 Nota: no debe confundirse este método con el análisis discriminante, en el cual, desde un principio se sabe cuántos grupos existen, y se tienen datos que provienen de cada uno de estos grupos.")
3
Este método se utiliza en muchas áreas (biología, sicología, estudios climáticos, etc).
En principio, supondremos que hay N datos, cada uno dado por un vector de M atributos o características (vector de RM). Por ejemplo, un conjunto de N personas se puede clasificar de acuerdo a tres atributos: edad, nivel educativo y nivel de ingreso. O sea que M = 3, y podemos imaginar que tenemos N “puntos” u “observaciones” en el espacio de M = 3 dimensiones. Podremos organizar nuestros datos en una matriz de N x 3. Nuestro problema será agrupar los N “puntos” en G grupos (donde G no es conocido a priori).
. Por ejemplo, un conjunto de N personas se puede clasificar de acuerdo a tres atributos: edad, nivel educativo y nivel de ingreso. O sea que M = 3, y podemos imaginar que tenemos N puntos u observaciones en el espacio de M = 3 dimensiones. Podremos organizar nuestros datos en una matriz de N x 3. Nuestro problema será agrupar los N puntos en G grupos (donde G no es conocido a priori).")
4
Hablamos de “semejanza” entre los datos
Hablamos de “semejanza” entre los datos. También podríamos hablar de “cercanía” (o “lejanía”) entre los datos, de acuerdo a algún criterio. Es deseable que, una vez formados los clusters, se cumpla que la distancia entre elementos dentro de un cluster sea menor que la distancia entre clusters. Entonces es necesario definir de alguna forma la “distancia” entre datos, y luego entre clusters.
 entre los datos, de acuerdo a algún criterio. Es deseable que, una vez formados los clusters, se cumpla que la distancia entre elementos dentro de un cluster sea menor que la distancia entre clusters. Entonces es necesario definir de alguna forma la distancia entre datos, y luego entre clusters.")
5
Algunas definiciones usuales de distancia
Sean dos datos: x = (x1, x2, …, xM) e y = (y1, y2, …, yM) Distancia euclidiana entre x e y : Es la distancia más usual, pero no necesariamente la mejor en todos los casos; en particular, si los elementos de x e y tienen unidades diferentes (como en el ejemplo anterior). Por eso se define también: Distancia euclidiana ponderada entre x e y : donde wi son los coeficientes de ponderación o “pesos”
 e y = (y1, y2, …, yM) Distancia euclidiana entre x e y : Es la distancia más usual, pero no necesariamente la mejor en todos los casos; en particular, si los elementos de x e y tienen unidades diferentes (como en el ejemplo anterior). Por eso se define también: Distancia euclidiana ponderada entre x e y : donde wi son los coeficientes de ponderación o pesos")
6
Los wi se pueden definir de varias formas.
Un caso particular importante se da cuando los atributos tienen unidades diferentes, u órdenes de magnitudes diferentes. En ese caso es imprescindible usar ponderaciones. Una ponderación posible es: siendo la varianza asociada al atributo i En este caso, tenemos la distancia de Karl-Pearson.

7
Ejemplo: se tienen 4 personas con tres atributos: edad, nivel de ingreso y nivel educativo. Es decir que hay 4 datos observados o puntos, con 3 atributos (N=4, M=3). Si usamos la distancia euclidiana con los datos tal como vienen, la columna del ingreso tendría una mayor influencia (no deseada). Para ponderar, calculamos el vector de varianzas: [ ] Y se calcula la matriz de distancias:
. Para ponderar, calculamos el vector de varianzas: [ ] Y se calcula la matriz de distancias:")
8
Sea cual sea la definición de distancia, siempre será posible construir una matriz de distancias (NxN), que tendrá N*(N-1)/2 valores potencialmente diferentes entre sí y diferentes de 0. Existen varias otras definiciones de distancia (ver p. ej., en Matlab función pdist, y también zscore para la ponderación). En particular, a veces se usa la correlación entre x e y, pero esta es una medida de semejanza, de modo que cuanto más grande sea, menor es la distancia entre x e y. Entonces, una posible definición de distancia es: 1 – corr(x,y) Es importante señalar que la definición de distancia que se elija condiciona considerablemente los agrupamientos que se van a obtener.
/2 valores potencialmente diferentes entre sí y diferentes de 0. Existen varias otras definiciones de distancia (ver p. ej., en Matlab función pdist, y también zscore para la ponderación). En particular, a veces se usa la correlación entre x e y, pero esta es una medida de semejanza, de modo que cuanto más grande sea, menor es la distancia entre x e y. Entonces, una posible definición de distancia es: 1 – corr(x,y) Es importante señalar que la definición de distancia que se elija condiciona considerablemente los agrupamientos que se van a obtener.")
9
Métodos jerárquicos En estos métodos, en etapas sucesivas se va construyendo una jerarquía de conjuntos de grupos, donde cada nuevo grupo se obtiene uniendo un par de grupos de la etapa anterior. A) Métodos aglomerativos usando la matriz de distancias. 1) Se comienza con N grupos, cada uno formado por un punto o dato observado. Con la matriz de distancias, se encuentran los dos puntos más próximos entre sí, de acuerdo a la distancia elegida. Se unen estos dos puntos, formándose así un grupo con 2 puntos, quedando en total (N-1) grupos.
 Métodos aglomerativos usando la matriz de distancias. 1) Se comienza con N grupos, cada uno formado por un punto o dato observado. Con la matriz de distancias, se encuentran los dos puntos más próximos entre sí, de acuerdo a la distancia elegida. Se unen estos dos puntos, formándose así un grupo con 2 puntos, quedando en total (N-1) grupos.")
10
Métodos jerárquicos (cont.)
2) Se buscan los dos grupos más cercanos y se unen. Para ello, previamente hay que definir lo que se entiende por “distancia entre grupos”, cuando estos contienen más de un dato. Hay también varias formas de definir la distancia entre grupos. Algunas de ellas son: Enlace simple (la distancia más corta entre un punto de uno y otro grupo) Enlace completo (la distancia más grande entre un punto de uno y otro grupo) Enlace promedio (la distancia promedio de todas las posibles distancias entre puntos de uno y otro grupo)
 Se buscan los dos grupos más cercanos y se unen. Para ello, previamente hay que definir lo que se entiende por distancia entre grupos , cuando estos contienen más de un dato. Hay también varias formas de definir la distancia entre grupos. Algunas de ellas son: Enlace simple (la distancia más corta entre un punto de uno y otro grupo) Enlace completo (la distancia más grande entre un punto de uno y otro grupo) Enlace promedio (la distancia promedio de todas las posibles distancias entre puntos de uno y otro grupo)")
11
Distancia entre centroides de ambos grupos (los centroides son los promedios de los vectores en cada grupo). En Matlab, la función linkage hace estas agrupaciones según distintos criterios. 3) Se repite el paso 2) sucesivamente hasta que todos los puntos están en un solo grupo. Lo importante no es llegar a un solo grupo (lo cual es trivial), sino detectar en qué paso intermedio detenerse.
 Se repite el paso 2) sucesivamente hasta que todos los puntos están en un solo grupo. Lo importante no es llegar a un solo grupo (lo cual es trivial), sino detectar en qué paso intermedio detenerse.")
12
Métodos jerárquicos (cont.) B) Método de Ward
No usa la matriz de distancias. En cada paso, se elige la unión de grupos que minimice la suma de varianzas sobre todos los grupos. (También el resultado de los agrupamientos depende de qué distancia se utilice.)
")
13
El diagrama de árbol jerárquico
Muestra los pasos intermedios de formación de los grupos y puede proporcionar un criterio subjetivo para detener el proceso. . x5 . x1 . x4 . . x3 x2 Primero se unen x3 y x4 (son los más cercanos entre los 5), luego x1 con x2 y finalmente {x3, x4} con x5 .
, luego x1 con x2 y finalmente {x3, x4} con x5 .")
14
El diagrama de árbol jerárquico
Primero se unen x3 y x4 (son los más cercanos entre los 5), luego x1 con x2 y finalmente {x3, x4} con x5 . . x1 x2 x3 x4 x5 En Matlab, la función dendrogram construye el árbol.
, luego x1 con x2 y finalmente {x3, x4} con x5 . . x1. x2. x3. x4. x5. En Matlab, la función dendrogram construye el árbol.")
15
¿Cuántos clusters retener?
En general, en los métodos de agrupación jerárquica, no es obvio cuál es el número óptimo de clusters. A veces, la existencia de información previa o la propia naturaleza del problema pueden sugerir una determinada partición en grupos. En ausencia de toda otra información, existen varios criterios, algunos basados en las matrices de covarianza intra-grupos o inter-grupos. Veremos aquí un criterio parcialmente subjetivo.

16
Se trata de considerar, en cada etapa, la distancia entre los clusters que se combinan.
Si se puede detectar alguna etapa del proceso en la que la distancia entre los clusters que se unen presenta un salto más o menos notorio, parece razonable detener el proceso allí ya que seguir agrupando implicaría unir grupos que están relativamente lejanos. Es recomendable reiterar el proceso cambiando la definición de distancia entre puntos y/o entre grupos, y comparar los distintos resultados finales obtenidos. La función cluster de Matlab permite detectar agrupamientos naturales de datos o cortar el árbol en un punto arbitrario. También la función clusterdata reúne a las funciones pdist, linkage y cluster.

17
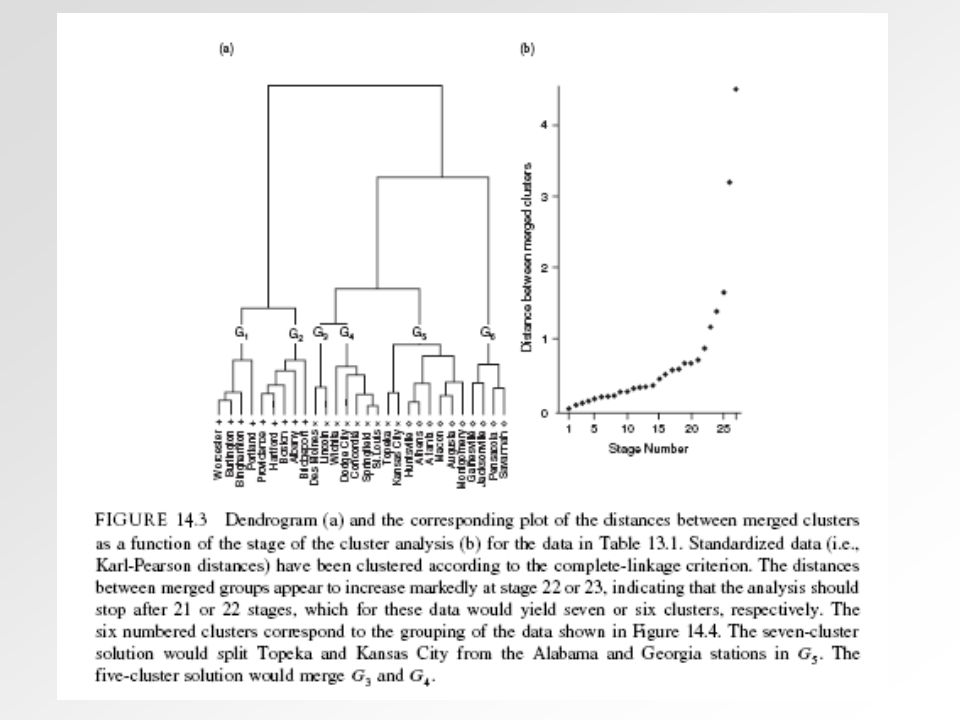
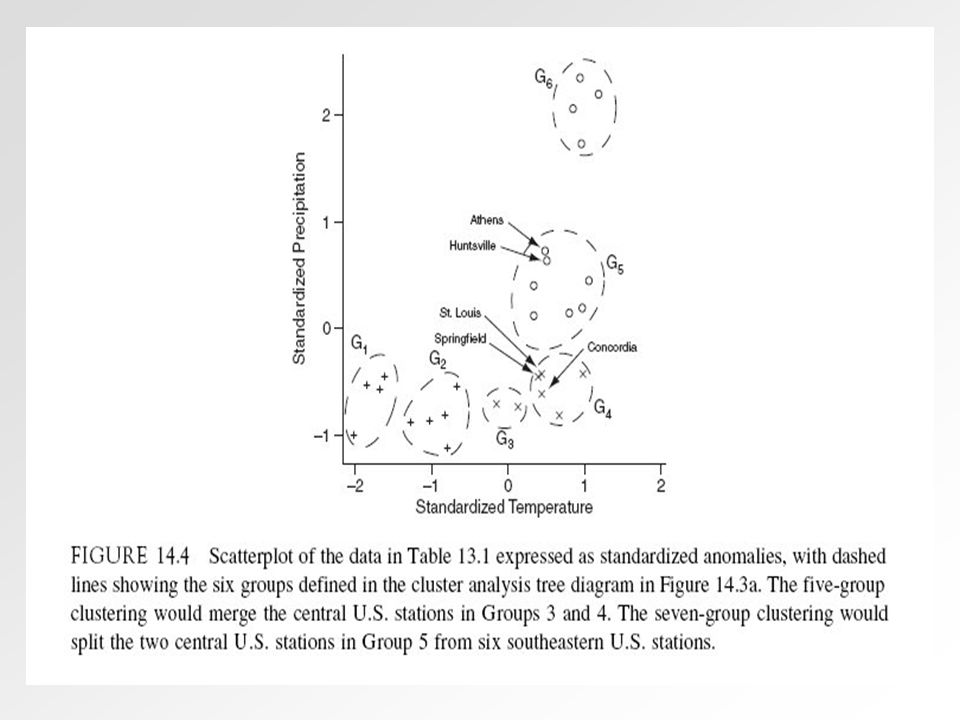
Ejemplo: 28 estaciones caracterizadas por su temperatura y precipitación medias en Julio ( ) (Wilks, Cap. 14) (N = 28, M = 2) Se usa la distancia de Karl-Pearson entre puntos, y el criterio de enlace completo para la distancia entre grupos
 Se usa la distancia de Karl-Pearson entre puntos, y el criterio de enlace completo para la distancia entre grupos.")
20
Métodos no jerárquicos
Una desventaja potencial de los métodos jerárquicos es que los puntos que en alguna etapa quedan en un mismo cluster, permanecerán juntos en adelante, no permitiendo reubicar puntos que pudieran haber sido mal clasificados. Los métodos no jerárquicos permiten esa reubicación.

21
El método de K-medias (K-means)
El método presupone conocido el número final K de clusters al que se quiere llegar (lo cual podría verse como una desventaja del método). Se comienza eligiendo K puntos como “semillas” Esos K puntos se tomarán como centroides de clusters. Alternativamente, se puede comenzar con K clusters. Esta elección inicial condiciona el resultado final. 2) Cada uno de los datos es asignado al centroide más cercano. Se tienen así clasificados todos los datos en K clusters. 3) Dentro de cada cluster se recalculan los centroides y se repite el paso 2. 4) Se reiteran los pasos 2) y 3) hasta que no se producen más reasignaciones. En Matlab, esto lo hace la función kmeans
. Se comienza eligiendo K puntos como semillas Esos K puntos se tomarán como centroides de clusters. Alternativamente, se puede comenzar con K clusters. Esta elección inicial condiciona el resultado final. 2) Cada uno de los datos es asignado al centroide más cercano. Se tienen así clasificados todos los datos en K clusters. 3) Dentro de cada cluster se recalculan los centroides y se repite el paso 2. 4) Se reiteran los pasos 2) y 3) hasta que no se producen más reasignaciones. En Matlab, esto lo hace la función kmeans.")
22
Agrupamientos aglomerativos nucleados
Es una combinación de un método jerárquico aglomerativo y uno no jerárquico (el de K-medias). Por un procedimiento iterativo se obtienen secuencialmente agrupaciones en un rango de número de clusters. Dado Gfinal (el número de clusters final deseado), se comienza con un número mayor (Ginicial > Gfinal). Se realiza el procedimiento K-medias para ese Ginicial y luego: 1) siguiendo alguno de los métodos vistos (p. ej. el de Ward), se unen los dos clusters más cercanos.
. Por un procedimiento iterativo se obtienen secuencialmente agrupaciones en un rango de número de clusters. Dado Gfinal (el número de clusters final deseado), se comienza con un número mayor (Ginicial > Gfinal). Se realiza el procedimiento K-medias para ese Ginicial y luego: 1) siguiendo alguno de los métodos vistos (p. ej. el de Ward), se unen los dos clusters más cercanos.")
23
2) Con los clusters obtenidos en 1), se aplica el K-medias
2) Con los clusters obtenidos en 1), se aplica el K-medias. Se repiten 1) y 2) hasta llegar a tener un número de clusters igual a Gfinal . (En los pasos intermedios se obtienen agrupaciones con número de clusters entre Ginicial y Gfinal .) Con este procedimiento, se disminuye en parte la influencia de la elección inicial arbitraria de semillas, permitiendo también reasignar puntos a los grupos.
 Con los clusters obtenidos en 1), se aplica el K-medias. Se repiten 1) y 2) hasta llegar a tener un número de clusters igual a Gfinal . (En los pasos intermedios se obtienen agrupaciones con número de clusters entre Ginicial y Gfinal .) Con este procedimiento, se disminuye en parte la influencia de la elección inicial arbitraria de semillas, permitiendo también reasignar puntos a los grupos.")
24
Ejemplo: Regionalización del Uruguay según el ciclo anual de precipitaciones (R. Terra y G. Pisciottano, 1994) Ciclo anual Rivera Ciclo anual Melo

25
Se utilizaron datos mensuales de 100 estaciones pluviométricas en Uruguay en el período 1933-1978.
Cada estación se caracterizó por su ciclo anual promedio en ese período (un vector de R12 para cada estación). Podemos considerar entonces que partimos de una matriz de 100 x 12. (100 puntos y 12 atributos o variables.) Se realizó una partición del Uruguay según el área de influencia de cada estación. Antes de aplicar técnicas de cluster analysis, se realizó un análisis de componentes principales para eliminar la variabilidad ruidosa y redundante de menor escala. Al mismo tiempo, se disminuye el volumen computacional.
. Podemos considerar entonces que partimos de una matriz de 100 x 12. (100 puntos y 12 atributos o variables.) Se realizó una partición del Uruguay según el área de influencia de cada estación. Antes de aplicar técnicas de cluster analysis, se realizó un análisis de componentes principales para eliminar la variabilidad ruidosa y redundante de menor escala. Al mismo tiempo, se disminuye el volumen computacional.")
26
Para ello, primero se obtuvo la matriz de anomalías, es decir que se calculó el ciclo anual promedio de las 100 estaciones y se restó al ciclo anual de cada una. Las series no fueron estandarizadas ya que era de interés tanto la forma del ciclo anual como su intensidad. Se obtuvieron los 12 EOFs, autovalores y PCs, (estos de longitud 100). Se retuvieron los dos primeros modos, que explican respectivamente el 54.7% y el 29.7% de la varianza total. Entonces, para el análisis de clusters se tienen 100 puntos o datos, con 2 atributos cada uno. Se utilizó el método de agrupamientos aglomerativos nucleados.
. Se retuvieron los dos primeros modos, que explican respectivamente el 54.7% y el 29.7% de la varianza total. Entonces, para el análisis de clusters se tienen 100 puntos o datos, con 2 atributos cada uno. Se utilizó el método de agrupamientos aglomerativos nucleados.")
27
Para elegir el número final de clusters, se tuvieron en cuenta:
la pequeña desviación estándar de la muestra el hecho de que se explica más del 84% de la varianza con sólo dos modos lo pequeño de la superficie a regionalizar el objetivo del trabajo (obtener una regionalización adecuada para estudios de variabilidad climática regional, donde no son relevantes detalles locales) Se determinó a priori en 4 el número de clusters finales. Se comenzó con 50 semillas (eligiéndolas de formas diferentes y llegando al mismo resultado final)
 Se determinó a priori en 4 el número de clusters finales. Se comenzó con 50 semillas (eligiéndolas de formas diferentes y llegando al mismo resultado final)")
28
Correlaciones entre los ciclos anuales medios de las 4 regiones
Se usaron 2 métodos jerárquicos distintos: enlace promedio y Ward, y también se usó el método no jerárquico hallando 5 y 6 clusters. Se observa que las regiones son bastante robustas respecto del método, excepto la región sur que no se unifica en ninguno de los procedimientos alternativos. Los ciclos anuales medios para cada una de las 4 regiones muestra tanto la diferencia de regímenes pluviométricos en distintas épocas del año, como las distintas intensidades de los mismos. Correlaciones entre los ciclos anuales medios de las 4 regiones

29
Regionalización de la precipitación en Uruguay según su ciclo anual
Terra y Pisciottano 1994

Presentaciones similares










 Gastón Sabatelli (85523)>")




 Gastón Sabatelli (85523)>")

>")

