Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Unsupervised visual learning of three-dimensional objects using a modular network architecture Ando, Suzuki, Fujita Neural Networks 12 (1999) 1037-1051
")
2
Indice Introduccion Descripción de la red modular Experimentos y discusión

3
Introducción Objetivo: reconocimiento 3D de objetos invariante a pose Aproximación: basada en vistas (view-based) Los objetos se representan por un conjunto de vistas en el sistema de coordenadas centradas en el observador Un conjunto de vistas se usan para el entrenamiento, y se obtiene la invarianza mediante interpolación
 Los objetos se representan por un conjunto de vistas en el sistema de coordenadas centradas en el observador Un conjunto de vistas se usan para el entrenamiento, y se obtiene la invarianza mediante interpolación")
4
Introducción Justificación biológica: –Estudios sicofisiolócos demuestran que las representaciones de objetos 3D en el humano son especificas del punto de vista –Experimentos electrofisiológicos: el cortex inferotemporal de los primates emplea representaciones centradas en el punto de vista

5
Introducción Aportación: modelo de aprendizaje no supervisado para el agrupamiento automático de las vistas en clases de objetos

6
Introducción Dificultades: –Alta dimensionalidad –La distribución de las vistas en el espacio de los datos es muy compleja –Las distribuciones de las vistas de objetos distintos no son facilmente separables

7
Introducción Propiedades favorables de los datos –Los datos de las vistas de un objeto a menudo residen en un subespacio de baja dimensión –La distribución de las vistas de un objeto es continua inherentemente

8
Introducción Estrategia: identificar multiples sub- espacios no lineales La distancia de los datos se calcula respecto de un sub-espacio no lineal que contiene multiples vistas Cuando se identifica el subespacio, la vista se clasifica en la clase de objetos más cercana

9
Introducción Realización: red de arquitectura modular que consiste en una combinación de autoencoders Cada autoencoder descubre el sub-espacio no lineal de cada clase de objetos Los pesos se estiman iterativamente en base a la estimación de máxima verosimilitud

10
Modelo de red modular K-means Gaussian mixture models Mezclas de autoencoders –Reducción de dimensión –Red modular

11
Red modular K-means –Busca K vectores dados N puntos –Particiona los datos enK clases, minimizando la distorsion Batch (Isodata) Online (SCL)
 Online (SCL)")
12
Red modular Mezclas de gaussianas –Cada clase de objetos corresponde con una distribución gausiana de las caracteristicas –Se estiman los parametros de las mezclas y de los componentes mediante Estimación de máxima verosimilitud Expectation-maximization –Inconveniente: clases con distribuciones unimodales

13
Red modular Estimación de máxima verosimilitud –Se estiman las medias, varianzas y probabilidades a priori. –Minimización de la energía por descenso del gradiente estocástico. –Para estimar la probabilidad a priori se introduce una restricción de probabilidad

14
Red modular Expectación-maximización –El paso E de expectación corresponde con el cálculo de las probabilidades a posteriori –El paso M de maximización consiste en el cálculo de la actualización de las estimaciones de los centros, varianzas y probabilidades a priori.

15
Red modular Mezclas de autoencoders –Cuando los datos son vistas de un objeto 3D, los datos están distribuidos continuamente en el espacio de los datos –Cada objeto se corresponde con una variedad que no puede separarse facilmente –Los autoencoders modelan las variedades por un proceso de compresión descompresión

16
Red modular Autoencoder: MLP con una capa hidden de dimensión reducida –Implementa la compresión/recuperación de los datos –Cada autoencoder se entrena minimizando el error de recuperación –Cada autoencoder modela inplícitamente una variedad posiblemente no lineal

17
Red modular Autoencoders –La distancia a la variedad se corresponde con la diferencia entre la entrada y la salida –3 capas: corresponde a la proyección lineal –5 capas: modelo no lineal

18
Red modular Mezcla de autoencoders –Cada módulo se entrena con multiples vistas del mismo objeto –La clasificación está dada por el softmax de las diferencias entre las entradas y las salidas de los autoencoders

20
Red modular Entrenamiento no supervisado de máxima verosimilitud –Las vistas son agrupadas (clustered) sin conocimiento de la identidad de los objetos –Para definir la función de verosimilitud se consideran distribuciones gausianas de varianza unitaria y media la salida del autoencoder –Se minimiza mediante descenso por el gradiente
 sin conocimiento de la identidad de los objetos –Para definir la función de verosimilitud se consideran distribuciones gausianas de varianza unitaria y media la salida del autoencoder –Se minimiza mediante descenso por el gradiente")
21
Red modular El aprendizaje fuerza a que al menos un módulo se identifique con el dato y trate de ajustarlo, mientras los otros módulos aumentan su distancia Asigna distintos módulos a distintas regiones input

22
Experimentos Múltiples vistas de los objetos 3D se presentan aleatoriamente, sin etiquetar Dificultad: a veces vistas de diferentes objetos son más similares que vistas del mismo objeto La red aprende a discriminar los objetos

23
Experimentos Indice –Agrupamiento de modelos de mallas Información disponible: vertices y ángulos Análisis de la representación interna –Imágenes en niveles de gris de objetos reales

24
Wire-frame objects Los objetos consisten de 5 segmentos cuyos 6 vértices son aleatoriamente selecionados en el cubo unidad

26
Wire-frames La vista está definida por dos parámetros de elvación y azimut Dos tipos de caracteristicas –Las coordenadas de los vértices –Los cosenos de los ángulos

27
Wire-frames Número de módulos: número de objetos Número de unidades en la capa intermedia: número de parámetros de la vista (2) En el entrenamiento los objetos y las vistas se seleccionan aleatoriamente El número de unidades en las capas no centrales llega hasta las 20 unidades
 En el entrenamiento los objetos y las vistas se seleccionan aleatoriamente El número de unidades en las capas no centrales llega hasta las 20 unidades")
28
Wire-frame Las vistas se inician en rango reducido que se va ampliando durante el entrenamiento La generalización se estudia restringiendo las vistas de entrenamiento Inicialmente con tres objetos

30
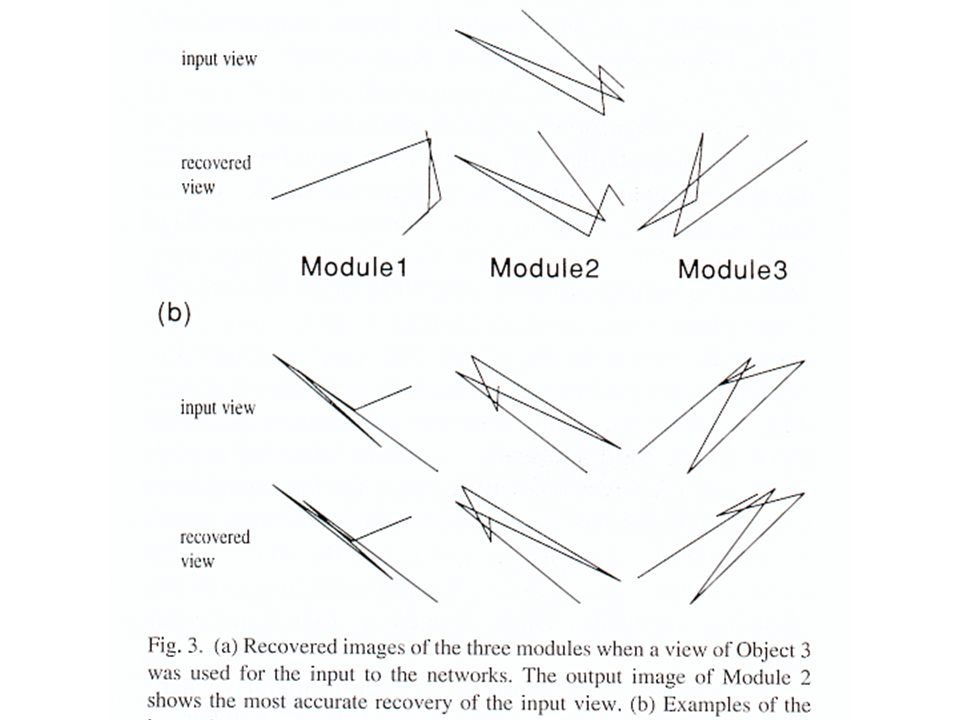
Wire-frame Los dos tipos de características dan resultados similares Resultados de presentarle 2500 vistas, al observar el error de recuperación se puede asocia modulo2 y objeto 3

32
Wire-frame Analisis de la información en la capa oculta intermedia –La información de pose se extrae y describe en la capa intermedia –Hay correspondencia uno a uno entre los datos de las vistas y la representación en la capa oculta

34
Wire frame Gereralización: entrenamiento con un rango reducido de vistas –Buenos resultados fuera de la región de entrenamiento

36
Wire-frame Aumentar el número de objetos 3,5 y 10 12 réplicas con conjuntos distintos d edatos Para cada intento el ratio de clasificación es el mejor de todas las posibles combinaciones de objetos y clases.

38
Imganes reales Una muñea y peluches V istas: mesa motorizada 1 cada grado Iluminación: dos fuentes en el frente Filtrado Gausiano de 4.0 Submuestreo 16x15 Distancia euclidea entre las mismas vistas de distintos objetos

40
Real images Autoasociadores de 5 capas, 240 input/output units, 5 para las capas ocultas y 2 para la intermedia Los resultados muestran la capacidad de identificar el objeto A en la clase 1, el B en la clase 2 Razones para la mala clasificación: los objetos B y C son muy simialres

Presentaciones similares
























 Microsoft SQL Server 2008 R2 Suscribase a o escríbanos a>")



>")



