Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Redes Neuronales Perceptron, Backpropagation, Adaline, Hopfield.
Algoritmos y ejemplos. Parte 2 M.C. Ernesto Cortés Pérez. Apuntes de la materia

2
Similitudes entre una neurona biológica y una artificial
Las entradas Xi representan las señales que provienen de otras neuronas y que son capturadas por las dendritas Los pesos Wi son la intensidad de la sinápsis que conecta dos neuronas; tanto Xi como Wi son valores reales. es la función umbral que la neurona debe sobrepasar para activarse; este proceso ocurre biológicamente en el cuerpo de la célula.

3
Neurona Artificial Cada señal de entrada pasa a través de una ganancia o peso, llamado peso sináptico o fortaleza de la conexión cuya función es análoga a la de la función sináptica de la neurona biológica. Los pesos pueden ser positivos (excitatorios), o negativos (inhibitorios). Las señales de entrada a una neurona artificial X1, X2,.., Xn son variables continuas en lugar de pulsos discretos, como se presentan en una neurona biológica. El nodo sumatorio acumula todas las señales de entradas multiplicadas por los pesos o ponderadas y las pasa a la salida a través de una función umbral o función de transferencia. La entrada neta a cada unidad puede escribirse de la siguiente manera:
, o negativos (inhibitorios). Las señales de entrada a una neurona artificial X1, X2,.., Xn son variables continuas en lugar de pulsos discretos, como se presentan en una neurona biológica. El nodo sumatorio acumula todas las señales de entradas multiplicadas por los pesos o ponderadas y las pasa a la salida a través de una función umbral o función de transferencia. La entrada neta a cada unidad puede escribirse de la siguiente manera:")
4
Neurona Artificial El valor de salida (único) se obtiene como
Cada neurona calcula su entrada neta como: Cada entrada es multiplicada por el peso de arco correspondiente.

5
Funciones de Transferencia
Hardlim (limitador fuerte) Esta función crea neuronas que clasifican las entradas en dos categorías diferentes.
 Esta función crea neuronas que clasifican las entradas en dos categorías diferentes.")
6
Funciones de Transferencia
Hardlims (limitador fuerte simétrico) Esta función crea neuronas que clasifican las entradas en dos categorías diferentes.
 Esta función crea neuronas que clasifican las entradas en dos categorías diferentes.")
7
Funciones de Transferencia
Purelin (Lineal) A diferencia de las anteriores, esta función no es acotada.
 A diferencia de las anteriores, esta función no es acotada.")
8
Funciones de Transferencia
Logsig (Sigmoide) Es acotada y derivable
 Es acotada y derivable.")
9
Funciones de Transferencia

10
Arquitecturas formadas por una neurona
Comenzaremos trabajando con arquitecturas simples formadas por un único elemento de procesamiento. La neurona trabaja como una función discriminante lineal.

11
Perceptrón

12
Ejemplo Verifique si la siguiente neurona se comporta como la función lógica AND

13
Graficar la función discriminante (recta)
AND Graficar la función discriminante (recta)
")
14
Entrenamiento del perceptrón
Se busca una estrategia iterativa que permita adaptar los valores de las conexiones a medida que se presentan los datos de entrada. Ver que el estímulo de entrada se corresponde con el producto interior de los vectors X y W.

15
Ajuste del vector de pesos con taza de aprendizaje (Learning rate)
Recordemos que la salida del perceptrón es hardlim En general, si llamamos t al valor esperado y al valor obtenido Utilizando la siguiente expresión para cálcular W wnuevo = w + (t - y) x
 x.")
16
Present network with next inputs from epoch Err = t – y
While epoch produces an error Present network with next inputs from epoch Err = t – y If Err <> 0 then Wj = Wj + LR * Err * Ij End If End While

17
Entrenamiento del Perceptrón
Seleccionar el valor de y Inicializar los pesos de las conexiones con valores random (vector W) Mientras no se clasifiquen todos los patrones correctamente Ingresar un patrón a la red. Si fue clasificado incorrectamente Wnuevo = W + (t - y) x
 Mientras no se clasifiquen todos los patrones correctamente. Ingresar un patrón a la red. Si fue clasificado incorrectamente. Wnuevo = W + (t - y) x.")
18
Ejemplo 1 Entrenar un perceptrón para que se comporte como la función lógica AND. Utilice = 0.3 = 1.5 W1 = 0 W2 = 0.25

19
El proceso se repite hasta comprobar que todos los patrones son clasificados correctamente
Si Y T, W1new= W (T-Y) X1 W2new= W (T-Y) X2 Si Y = T, W no se actualiza Wnew= W + (T-Y) X AND X1 X2 T W W Y W1new W2new
 X1. W2new= W (T-Y) X2. Si Y = T, W no se actualiza. Wnew= W + (T-Y) X. AND. X1 X2 T W1 W2 Y W1new W2new")
20
Perceptrón Hardlim

21
Ejercicio Entrenar un perceptrón para que se comporte como la función lógica AND. Utilice = 0.3 W0 = 0 W1 = 0 W2 = 0.25

22
Ejercicio X0 X1 X2 T W W W2 Salida NewW0 NewW1 NewW

23
Solución X0 X1 X2 T W W W2 Salida NewW0 NewW1 NewW

24
Red Neurona Artificial, Representación con ganancia (bias)
la nueva entrada b es una ganancia que refuerza la salida del sumador n, la cual es la salida neta de la red.

25
Regla de aprendizaje del Perceptron con ganancia
There are three conditions that can occur for a single neuron once an input vector p is presented and the network’s response a is calculated: CASE 1. If an input vector is presented and the output of the neuron is correct (a = t, and e = t – a = 0), then the weight vector w is not altered. CASE 2. If the neuron output is 0 and should have been 1 (a = 0 and t = 1, and e = t – a = 1) the input vector p is added to the weight vector w. CASE 3. If the neuron output is 1 and should have been 0 (a = 1 and t = 0, and e = t – a = –1) the input vector p is subtracted from the weight vector w.
, then the weight vector w is not altered. CASE 2. If the neuron output is 0 and should have been 1 (a = 0 and t = 1, and e = t – a = 1) the input vector p is added to the weight vector w. CASE 3. If the neuron output is 1 and should have been 0 (a = 1 and t = 0, and e = t – a = –1) the input vector p is subtracted from the weight vector w.")
26
The perceptron learning rule can be written in terms of the error:
e = t – a And the change will be made to the weight vector Δw

27
CASE 1. If e = 0, then make a change Δw equal to 0.
CASE 2. If e = 1, then make a change Δw equal to pT. CASE 3. If e = –1, then make a change Δw equal to –pT. All three cases can then be written with a single expression:

28
We can get the expression for changes in a neuron’s bias, which always has an input of 1:
For the case of a layer of neurons we have:

29
The Perceptron Learning Rule can be summarized as follows:

30
Soluciones obtenidas con la ganancia “b”, a las funciones “and” y “or”

31
El algoritmo de entrenamiento del Perceptrón con bias (ganancia)
Se inicializa la matriz de pesos y el valor de la ganancia, por lo general se asignan valores aleatorios a cada uno de los pesos wi y al valor b Se presenta el primer patrón a la red, junto con la salida esperada en forma de pares entrada/salida Se calcula la salida de la red por medio de: puede ser la función hardlim o hardlims

32
Bias: por lo general se le asigna un valor inicial de 1 y se ajusta durante la etapa de aprendizaje de la red.

33
4.- Cuando la red no retorna la salida correcta, es necesario alterar el valor de los pesos y el bias, tratando de aumentar las posibilidades de que la clasificación sea correcta.

34
Ejemplo 2 1 -> 1 0 -1 -> 1 -2 1 -> -1 0 2 -> -1
> 1 > 1 > -1 > -1 En este caso las salidas toman valores bipolares de 1 o –1

35
Los valores iniciales asignados aleatoriamente a los parámetros de la red son:

36
Iteración 0 Interceptos con los ejes:

37
Iteración 1

38
Iteración 1 De la iteración 1 p1 esta mal clasificado, la actualización de pesos permite que este patrón sea clasificado correctamente.

39
Iteración 1 La iteración 1 lleva a la característica de decisión

40
Iteración 2 Se presenta p2 a la red, y es clasificado correctamente, como se observo gráficamente.

41
Iteración 2 Este patrón ha sido clasificado correctamente y por lo tanto no hay actualización del conjunto de entrenamiento:

42
Iteración 3 Se presenta p3 a la red y es clasificado correctamente, como se observó gráficamente

43
Iteración 3 Como se esperaba, no hubo error en la clasificación de este patrón, y esto lleva a que no haya actualización de los pesos de la red

44
Iteración 4 Se presenta a la red p4

45
Iteración 4 La red ha clasificado incorrectamente este patrón y por lo tanto deben modificarse pesos y ganancias

46
Iteración 4 En esta iteración la red se comportara de acuerdo a la característica de decisión

47
La red ha clasificado correctamente los patrones de entrenamiento, después de entrenada la red con los pesos y ganancias finales, cualquier otro valor de entrada será clasificado según la característica de decisión mostrada. Ejercicio: verificar a que clase pertenecen los siguientes patrones: [-2 3] [ 3 3] [ 1 1] [-1 -1] [3 2] [ 5 -2]

48
Ejercicio 1

49
The output a does not equal the target value t1, so we use the perceptron rule to find the incremental changes to the weights and biases based on the error.

50
You can calculate the new weights and bias using the Perceptron update rules shown previously.

53
Ejercicio 2 Sobre una cinta transportadora circulan naranjas y melones. Se busca obtener un clasificador de frutas que facilite su almacenamiento. Para cada fruta se conoce su diámetro en centímetros, su intensidad de color naranja, medida entre 0 y 255, y su peso en gramos. Ejemplos: Naranjas = { (10,200,150), (8,150,100), (7,170,200), (15,250,180)} Melón = {(20,30,500), (26,30,780), (24,32,900), (19,31,500)} Entrenar un perceptrón que permita resolver el problema. Utilice como W inicial (0,0,0), y b =0. Nota: etiqueta naranjas =1, Melón =0. Una vez entrenado el perceptron verificar la clase a la que pertenecen los siguientes patrones desconocidos: (14,210,150) (180,199,23)
, (8,150,100), (7,170,200), (15,250,180)} Melón = {(20,30,500), (26,30,780), (24,32,900), (19,31,500)} Entrenar un perceptrón que permita resolver el problema. Utilice como W inicial (0,0,0), y b =0. Nota: etiqueta naranjas =1, Melón =0. Una vez entrenado el perceptron verificar la clase a la que pertenecen los siguientes patrones desconocidos: (14,210,150) (180,199,23)")
54
Ejercicio 3 Una agencia de modelos publicó los resultados de la última selección de postulantes. En ella se habían presentado seis mujeres. Cada una de ellas ha sido caracterizada sólo por su peso y altura. El resultado fue el siguiente: Aceptadas = {(52,1.79), (53,1.81), (55,1.75)} Rechazadas ={(65,1.70), (68,1.65),(58,1.71)} A) Represente el criterio de selección a través de una RN formada por un único perceptrón. B) Cuál sería la respuesta del perceptrón si se presentaran estas postulantes: {(56,1.73), (70,1.60), (45,1.80)} Resuelva el problema anterior en un programa en matlab
, (53,1.81), (55,1.75)} Rechazadas ={(65,1.70), (68,1.65),(58,1.71)} A) Represente el criterio de selección a través de una RN formada por un único perceptrón. B) Cuál sería la respuesta del perceptrón si se presentaran estas postulantes: {(56,1.73), (70,1.60), (45,1.80)} Resuelva el problema anterior en un programa en matlab.")
55
Ejercicio 4 Se cree que los niños aprenden mediante un proceso llamado razonamiento por analogías, en el que intentan asociar objetos parecidos a otros que ya conocen, y los intentan agrupar por categorías. Supón que un niño ha visto alguna vez un león en el zoológico y que sabe que es peligroso, y lo ha representado internamente por el patrón ( ) Un día va por la calle y se encuentra a un gato, que representaremos por el patrón ( ), despues se encuentra con animal parecido a los dos anteriores y lo asocia con el siguiente patrón ( ) ¿Debe salir corriendo el niño porque cree al verlo que se parece demasiado a un león? Modela ésta situación mediante un perceptrón.
 Un día va por la calle y se encuentra a un gato, que representaremos por el patrón ( ), despues se encuentra con animal parecido a los dos anteriores y lo asocia con el siguiente patrón ( ) ¿Debe salir corriendo el niño porque cree al verlo que se parece demasiado a un león Modela ésta situación mediante un perceptrón.")
61
Perceptrón con Matlab (etapa de aprendizaje)
] t =[ ] plotpv(p, t)
")
62
Perceptrón con Matlab (etapa de aprendizaje)
net=newp([-2 2;-2 2],1,'hardlims','learnp'); net.adaptParam.passes = 1; net.iw{1,1}= [ ]; net.b{1} = [0.5];
; net.adaptParam.passes = 1; net.iw{1,1}= [ ]; net.b{1} = [0.5];")
63
Iteración 1 [net,a,e]=adapt(net,p{1},t{1}); a e pesos=net.iw{1,1}
bias=net.b{1}
![Iteración 1 [net,a,e]=adapt(net,p{1},t{1}); a e pesos=net.iw{1,1}](http://slideplayer.es/slide/10571950/34/images/63/Iteraci%C3%B3n+1+%5Bnet%2Ca%2Ce%5D%3Dadapt%28net%2Cp%7B1%7D%2Ct%7B1%7D%29%3B+a+e+pesos%3Dnet.iw%7B1%2C1%7D.jpg "bias=net.b{1}")
64
Resultados iteración 1 a = -1 e = 2 pesos = 3.3000 2.2000 bias =
bias = 2.5000

65
Iteración 2 net.iw{1,1}= pesos; net.b{1} = bias;
[net,a,e]=adapt(net,p{2},t{2});
;")
66
Resultados iteración 2 a = 1 e = pesos = bias = 2.5000

67
Iteración 3 net.iw{1,1}= pesos; net.b{1} = bias;
[net,a,e]=adapt(net,p{3},t{3});
;")
68
Resultados iteración 3 a = -1 e = pesos = bias = 2.5000

69
Iteración 4 net.iw{1,1}= pesos; net.b{1} = bias;
[net,a,e]=adapt(net,p{4},t{4});
;")
70
Resultados iteración 4 a = 1 e = -2 pesos = 3.3000 -1.8000 bias =
bias = 0.5000

71
Aprendizaje completo Perceptrón con Matlab (1 época)
net=newp([-2 2;-2 2],1,'hardlims','learnp'); net.adaptParam.passes = 1; net.iw{1,1}= [ ]; net.b{1} = [0.5]; [net,a,e]=adapt(net,p,t);
; net.adaptParam.passes = 1; net.iw{1,1}= [ ]; net.b{1} = [0.5]; [net,a,e]=adapt(net,p,t);")
72
1era época a = [-1] [1] [-1] [1] e = [2] [0] [0] [-2] pesos =
[-1] [1] [-1] [1] e = [2] [0] [0] [-2] pesos = bias = 0.5000
![1era época a = [-1] [1] [-1] [1] e = [2] [0] [0] [-2] pesos =](http://slideplayer.es/slide/10571950/34/images/72/1era+%C3%A9poca+a+%3D+%5B-1%5D+%5B1%5D+%5B-1%5D+%5B1%5D+e+%3D+%5B2%5D+%5B0%5D+%5B0%5D+%5B-2%5D+pesos+%3D.jpg "[-1] [1] [-1] [1] e = [2] [0] [0] [-2] pesos = bias =")
73
Resultado en 2 épocas net.adaptParam.passes = 2; t = [1] [1] [-1] [-1]
[1] [1] [-1] [-1] a = e = [0] [0] [0] [0] pesos = bias = 0.5000
![Resultado en 2 épocas net.adaptParam.passes = 2; t = [1] [1] [-1] [-1]](http://slideplayer.es/slide/10571950/34/images/73/Resultado+en+2+%C3%A9pocas+net.adaptParam.passes+%3D+2%3B+t+%3D+%5B1%5D+%5B1%5D+%5B-1%5D+%5B-1%5D.jpg "[1] [1] [-1] [-1] a = e = [0] [0] [0] [0] pesos = bias =")
74
Patrones ya clasificados
plotpc(pesos, bias)
")
75
Etapa de reconocimiento
a1=sim(net,p1) a1 = -1
 a1 = -1.")
76
Perceptrón Multicapa Un Perceptrón multicapa es una red con alimentación hacia delante, compuesta de varias capas de neuronas entre la entrada y la salida de la misma, esta red permite establecer regiones de decisión mucho más complejas.

77
Esquema

78
Un esquema simplificado del modelo del Perceptrón Multicapa
Donde W: Matriz o vector de pesos asignada a cada una de las entradas de la red de dimensiones SxR, con S igual al número de neuronas, y R la dimensión del vector de entrada p: Vector de entradas a la red de dimensiones Rx1 b: Vector de ganancias de la red de dimensiones Sx1

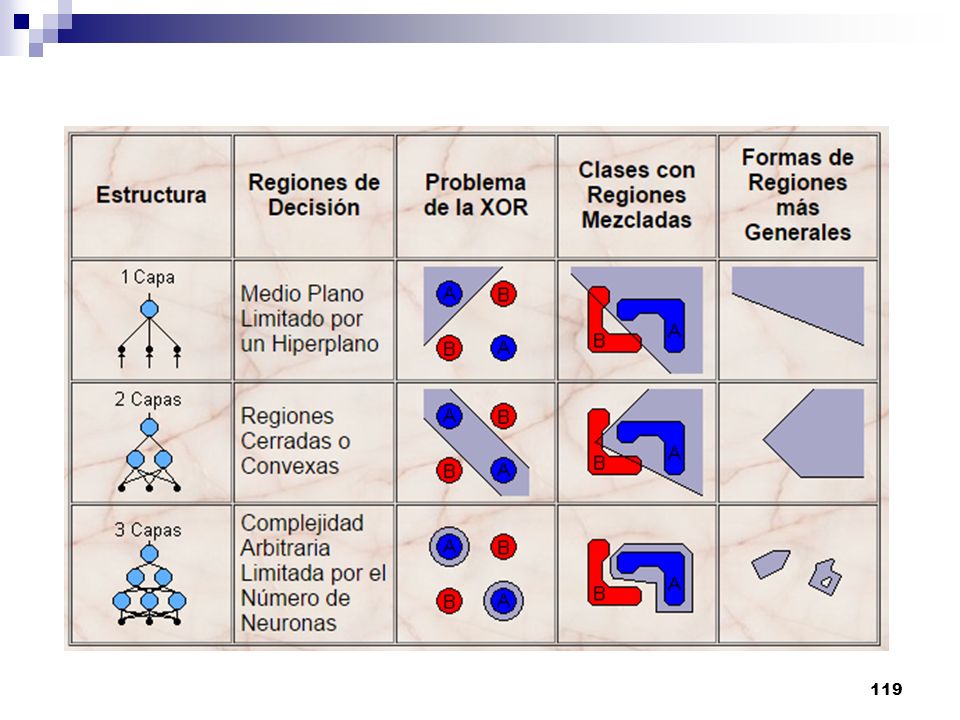
79
Las capacidades del Perceptrón multicapa con dos y tres capas y con una única neurona en la capa de salida

80
Redes multicapa Ver que el perceptrón no puede resolver el problema del XOR porque no es linealmente separable. > 0 > 1 1 -1 -> 1 1 1 -> 0

81
XOR usando mas de un perceptrón
w11=1 w12=1; w21=1 w22=1; w31=1 w32=-1.5 b1=-0.5 b2=-1.5 b3=-0.5

82
Función de activación en la capa oculta
a = tansig(n) = 2/(1+exp(-2*n))-1 purelin en la capa de salida 0.0107 Capa oculta f(((-1 1) + (-1 1))+(-0.5)) = f(-2 + (-0.5)) = f(-2.5)= f(((-1 1) + (-1 1))+(-1.5)) = f(-2 + (-1.5)) = f(-3.5)= Capa de salida f((( 1) + ( -1.5))+(-0.5)) = f( (-0.5)) = f(0.0107)=
 = 2/(1+exp(-2*n))-1. purelin en la capa de salida Capa oculta. f(((-1 1) + (-1 1))+(-0.5)) = f(-2 + (-0.5)) = f(-2.5)= f(((-1 1) + (-1 1))+(-1.5)) = f(-2 + (-1.5)) = f(-3.5)= Capa de salida. f((( 1) + ( -1.5))+(-0.5)) = f( (-0.5)) = f(0.0107)=")
83
Adaline Al mismo tiempo que Frank Rosenblatt trabajaba en el modelo del Perceptrón Bernard Widrow y su estudiante Marcian Hoff introdujeron el modelo de la red Adaline.

84
Adaline La red Adaline es similar al Perceptrón, excepto en su función de transferencia, la cual es una función de tipo lineal en lugar de un limitador fuerte como en el caso del Perceptrón.

85
Adaline La red Adaline presenta la misma limitación del Perceptrón en cuanto al tipo de problemas que pueden resolver, ambas redes pueden solo resolver problemas linealmente separables.

86
Adaline Sin embargo el algoritmo LMS (Least Mean Square) es más potente que la regla de aprendizaje del Perceptrón ya que minimiza el error medio cuadrático.
 es más potente que la regla de aprendizaje del Perceptrón ya que minimiza el error medio cuadrático.")
87
Perceptron vs Adaline

88
Regla «delta» de aprendizaje de Adaline

89
Regla «delta» de aprendizaje de Adaline

90
Algoritmo LMS (Least Mean squares)
w(k+1)=w(k) + alpha*error(k)*entrada b(k+1)=b(k) + alpha*error(k)
=w(k) + alpha*error(k)*entrada. b(k+1)=b(k) + alpha*error(k)")
91
Diferencias perceptron - adaline
ADALINE calcula el error a partir de la entrada neta, y el PERCEPTRON usa la salida. El error total del ADALINE nunca será nulo, por lo que la condición de terminación del algoritlno LMS suele ser: Error(t)- Error(t-1) < ξ Aparece el parámetro alpha=tasa de aprendizaje alpha debe poseer en teoría valores infinitamente pequeños. Se obtienen buenos resultados con valores en torno a 0.1. ADALINE garantiza no sólo una solución válida para problemas linealmente separables sino la que produce un error mínimo.
- Error(t-1) < ξ. Aparece el parámetro alpha=tasa de aprendizaje alpha debe poseer en teoría valores infinitamente pequeños. Se obtienen buenos resultados con valores en torno a 0.1. ADALINE garantiza no sólo una solución válida para problemas linealmente separables sino la que produce un error mínimo.")
92
Backpropagation (antecedentes)
El primer algoritmo de entrenamiento para redes multicapa fue desarrollado por Paul Werbos en 1974, Fue solo hasta mediados de los años 80 cuando el algoritmo Backpropagation o algoritmo de propagación inversa fue re-descubierto.

93
Backpropagation La importancia de esta red consiste en que, las neuronas de las capas intermedias se organizan a sí mismas de tal modo que las distintas neuronas aprenden a reconocer distintas características del espacio total de entrada.

94
Backpropagation Después del entrenamiento, cuando se les presente un patrón arbitrario de entrada que contenga ruido o que esté incompleto, las neuronas de la capa oculta de la red responderán con una salida activa si la nueva entrada contiene un patrón que se asemeje a aquella característica que las neuronas individuales hayan aprendido a reconocer durante su entrenamiento.

95
Backpropagation Y a la inversa, las unidades de las capas ocultas tienen una tendencia a inhibir su salida si el patrón de entrada no contiene la característica para reconocer, para la cual han sido entrenadas.

96
Backpropagation Varias investigaciones han demostrado que, durante el proceso de entrenamiento, la red Backpropagation tiende a desarrollar relaciones internas entre neuronas con el fin de organizar los datos de entrenamiento en clases.

97
Arquitectura

98
Regla de Aprendizaje mediante reducción del error
q: Equivale al número de componentes el vector de entrada. m: Número de neuronas de la capa oculta l: Número de neuronas de la capa de salida

99
Para iniciar el entrenamiento se le presenta a la red un patrón de entrenamiento, el cual tiene q componentes:

100
Cuando se le presenta a la red una patrón de entrenamiento, este se propaga a través de las conexiones existentes produciendo una entrada neta n en cada una las neuronas de la siguiente capa. W: Peso que une la componente i de la entrada con la neurona j de la capa oculta p: Componente i del vector p que contiene el patrón de entrenamiento de q componentes b: Ganancia de la neurona j de la capa oculta

101
Compute the Sensitivities (Backpropagation)
Sensitivity

102
Backpropagation (Sensitivities)
The sensitivities are computed by starting at the last layer, and then propagating backwards through the network to the first layer.

103
Initialization (Last Layer)
")
104
Summary Forward Propagation Backpropagation Weight Update

105
Example: Function Approximation with logsig
- e + 1-2-1 Network a

106
Network 1-2-1 Network a p

107
Initial Conditions ∞=0.1

108
Forward Propagation

109
Transfer Function Derivatives
1 n ( ) d e – + - è ø æ ö 2 a = f 2 n ( ) d 1 =
 d. e. – + - è. ø. æ. ö. 2. a. = f. 2. n. ( ) d. 1. =")
110
Backpropagation s F n t a s F n W ( ) – f 1.261 1 2.522 = ( ) a – 0.09
0.09 0.17 2.522 =

111
Weight Update

112
Choice of Architecture
p ( ) 1 i 4 - è ø æ ö sin + = 1-3-1 Network i = 1 i = 2 i = 4 i = 8
 1. i è. ø. æ. ö. sin. + = Network. i = 1. i = 2. i = 4. i = 8.")
113
Choice of Network Architecture
p ( ) 1 6 4 - è ø æ ö sin + = 1-2-1 1-3-1 1-4-1 1-5-1
 è. ø. æ. ö. sin. + =")
114
Convergence t p ( ) 1 sin + = 5 1 5 3 3 4 2 4 2 1
 1 sin + =")
115
Generalization t p ( ) 1 4 - è ø æ ö sin + = 1-2-1 1-9-1
 è ø æ ö sin + =")
116
Ejemplo con tangente sigmoidal
Tansig ó

117
Derivadas de tansig y purelin
TanSig Purelin

118
Los valores de las derivadas del error medio cuadrático son:
tansig purelin

120
Aproximar la siguiente función

121
Conjunto de entrenamiento

123
Valores iniciales función 1

124
Aproximar la siguiente función 2

125
p = -1:0.1:1; t = [-.9602, , , , , , , , .3072, , , , , , ];

126
ρ=0.01; w1 = [3.5000; ; ; ; ]; b1 = [ ; ; ; ; ]; w2 = [0.2622, , , , ]; b2 = [0.1326];
![ρ=0.01; w1 = [3.5000; ; ; ; ]; b1 = [ ; ; ; ; ];](http://slideplayer.es/slide/10571950/34/images/126/%CF%81%3D0.01%3B+w1+%3D+%5B3.5000%3B+%3B+%3B+%3B+%5D%3B+b1+%3D+%5B+%3B+%3B+%3B+%3B+%5D%3B.jpg "w2 = [0.2622, , , , ]; b2 = [0.1326];")
127
Función 3

128
Clasificador de vocales
Representación de letras A=[ ; ; ; ];

129
A=[ ; ; ; ]; E=[ ; ; ]; I=[ ; ; ]; O=[ ; ; ]; U=[ ; ; ];
![A=[ ; ; ; ]; E=[ ; ; ]; I=[ ; ; ];](http://slideplayer.es/slide/10571950/34/images/129/A%3D%5B+%3B+%3B+%3B+%5D%3B+E%3D%5B+%3B+%3B+%5D%3B+I%3D%5B+%3B+%3B+%5D%3B.jpg "O=[ ; ; ]; U=[ ; ; ];")
130
Matriz de patrones A E I O U 1 1 1 1 1

131
Matriz de etiquetas

132
Patrón letra “A” t 1 0.1 0.0

133
Aproximación de función con Newff (matlab)
t=sin(pi*p/4); %p=[ ]; %t=[ ]; net =newff(p, t ,[5 1],{'tansig','purelin'},'traingdx','learngdm','mse');
; %p=[ ]; %t=[ ]; net =newff(p, t ,[5 1],{ tansig , purelin }, traingdx , learngdm , mse );")
134
net.divideFcn = ''; net.trainParam.show = 10; net.trainParam.epochs = 100; net.trainParam.lr = 0.01; net.trainparam.goal=0.001;

135
net = train(net,p,t); y2 = sim(net,p); plot(p,t,'-b',p,y2,'-r');
; y2 = sim(net,p); plot(p,t, -b ,p,y2, -r );")
136
Clasificador de vocales
; ; ]; figure(1),imagesc(A) AA=A(:); %Convierte la matriz a vector
,imagesc(A) AA=A(:); %Convierte la matriz a vector.")
137
Crea matriz de patrones
matriz=cat(2,AA,EE,II,OO,UU);
;")
138
meta=[ ; ; ; ; ];
![meta=[ ; ; ; ; ];](http://slideplayer.es/slide/10571950/34/images/138/meta%3D%5B+%3B+%3B+%3B+%3B+%5D%3B.jpg "meta=[ ; ; ; ; ];")
139
net = newff(matriz, meta,[50 5],{'tansig', 'purelin'},'trainscg');
net.divideFcn = ''; net.trainParam.show = 10; net.trainParam.epochs = 200; net.trainParam.lr = 0.001; net.trainparam.min_grad=1e-20; net.trainparam.goal= ;
![net = newff(matriz, meta,[50 5],{ tansig , purelin }, trainscg );](http://slideplayer.es/slide/10571950/34/images/139/net+%3D+newff%28matriz%2C+meta%2C%5B50+5%5D%2C%7B+tansig+%2C+purelin+%7D%2C+trainscg+%29%3B.jpg "net.divideFcn = ; net.trainParam.show = 10; net.trainParam.epochs = 200; net.trainParam.lr = 0.001; net.trainparam.min_grad=1e-20; net.trainparam.goal= ;")
140
ENTRENA LA RED CON LAS CARACTERISTICAS ANTES ESTABLECIDAS
[net,tr] = train(net,matriz,meta);
;")
141
Patrón de prueba X=[1 1 1 1 1; 1 0 0 0 1; 1 1 1 1 1; 1 0 1 0 1;
]; figure(6),imagesc(X) XX=X(:); y=sim(net,XX) [a, clase_obtenida]=max(y)
,imagesc(X) XX=X(:); y=sim(net,XX) [a, clase_obtenida]=max(y)")
142
Clasificador alfabético

144
Hopfield Uno de los principales responsables del desarrollo que ha experimentado la computación neuronal ha sido J. Hopfield. Este modelo consiste en una red monocapa con N neuronas cuyos valores de salida son binarios : 0/1 ó -1/+1

145
Las funciones de activación son del tipo escalón
Las funciones de activación son del tipo escalón. Se trata, por tanto, de una red discreta con entradas y salidas binarias. f(x) = +1 si x > 0i f(x) = -1 si x < 0ii f(x) = x si x = 0ii
 = +1 si x > 0i. f(x) = -1 si x < 0ii. f(x) = x si x = 0ii.")
146
0i es el umbral de disparo de la neurona i, que representa el desplazamiento de la función de transferencia. En este modelo suele adoptar un valor proporcional a la suma de los pesos de las conexiones de cada neurona con el resto: donde : ∑ es la sumatoria desde j = 1 hasta N k es la constante de proporcionalidad

147
Existen conexiones laterales (cada neurona se encuentra conectada a todas las demás) pero no autorrecurrentes (no consigo misma). Los pesos asociados a las conexiones entre pares de neuronas son simétricos (wij = wji)
.")
148
Funcionamiento Se trata de una red autoasociativa. Por tanto, diferentes patrones pueden ser almacenados en la red, como si de una memoria se tratase, durante la etapa de aprendizaje.

149
Aprendizaje El mecanismo de aprendizaje utilizado es de tipo OFF LINE, por lo que existe una etapa de aprendizaje y otra de funcionamiento de la red. Utiliza aprendizaje no supervisado.

150
Utilizando una notación matricial, para representar los pesos de la red se puede utilizar una matriz de dimensión NxN (N es el número de neuronas de la red y por tanto de componentes del vector de entrada). Esta matriz es simétrica (wij = wji) y con la diagonal con valores nulos (wii = 0) al no haber conexiones autorecurrentes.
 y con la diagonal con valores nulos (wii = 0) al no haber conexiones autorecurrentes..")
151
Utilizando esta notación, el aprendizaje consistiría en la creación de la matriz de pesos W a partir de los k vectores de entrada que se enseñan a la red. W = (T(Ek). Ek - I) Donde es la sumatoria para k igual a 1 hasta el número de neuronas, N T(Ek) es la transpuesta de la matriz Ek I es la matriz identidad que anula los pesos de las conexiones autorecurrentes wii
. Ek - I) Donde. es la sumatoria para k igual a 1 hasta el número de. neuronas, N. T(Ek) es la transpuesta de la matriz Ek. I es la matriz identidad que anula los pesos de las conexiones autorecurrentes wii.")
152
Ejemplo: Hopfield Patrón 1 Patrón 2
El entrenamiento va a consistir en el aprendizaje de dos patrones de cuatro pixeles cada una. Los pixeles se representan mediante el valor -1 si es blanco y 1 si es negro. Patrón 1 Patrón 2

153
Los valores de los vectores de entrada que representan cada patrón son:
E1= [1,1,-1,-1] y E2 = [-1,-1,1,1] Por tanto, los patrones de entrada a la red van a ser dos vectores (M=2) de 4 elementos (N=4) conteniendo los valores de los píxeles.
 de 4 elementos (N=4) conteniendo los valores de los píxeles.")
154
Etapa de aprendizaje El aprendizaje de estos dos patrones consiste en la obtención de los pesos de la red (matriz W). Para la entrada E1, la salida W1 es: W1 1 -1 TE1.E1-I = . - =

155
Para la entrada E2, la salida W2 es:
-1 1 TE2.E2-I = . - =

156
Sumando W1 y W2 se obtiene la matriz de pesos definitiva, W:
2 -2 W=W1+W2 =

157
Etapa de funcionamiento
Si aplicamos a la red la entrada:

158
E = [1 -1 -1 -1] , el vector de salida seria:
![E = [ ] , el vector de salida seria:](http://slideplayer.es/slide/10571950/34/images/158/E+%3D+%5B+%5D+%2C+el+vector+de+salida+seria%3A.jpg "E = [ ] , el vector de salida seria:")
159
Como suponemos una función de activación de cada neurona de tipo escalón con desplazamiento sobre el origen, ß=0, la salida de la red después de la primera iteración es: S(t) = [ ]
 = [ ]")
160
Repitiendo el proceso, tomando como entrada la salida anterior, S
S(t)
")
161
Aplicando igualmente la función de activación la salida obtenida es:
S(t+1) = [ ] Al repetirse la salida, la red se ha estabilizado, generándose el patrón más parecido al que se ha presentado como entrada.
 = [ ] Al repetirse la salida, la red se ha estabilizado, generándose el patrón más parecido al que se ha presentado como entrada.")
162
Cálculo de energía para cada patrón

163
Distancia de Hamming En Teoría de la Información se denomina distancia de Hamming a la efectividad de los códigos de bloque y depende de la diferencia entre una palabra de código válida y otra. Por ejemplo: La distancia Hamming entre y es 2. La distancia Hamming entre y es 3. La distancia Hamming entre "toned" y "roses" es 3.

164
Calculo de distancias Hamming Euclidea Distancia Minkowski, p=2
Distancia Manhatan o City-Block

165
Ejercicio 1 Patrones de entrada (7 X 6):
y comprobar su funcionamiento para la figura distorsionada

166
Ejercicio 2 Distorsionar en 20% la letra A

167
Ejercicio 3

168
Gracias!

169
Cada una de las neuronas de la capa oculta tiene como salida a
f: Función de transferencia de las neuronas de la capa oculta

170
La salida de la red de cada neurona a se compara con la salida deseada t para calcular el error en cada unidad de salida

171
El error medio cuadrático para patrón es:

172
Calculo del error en la capa de salida:
Calculo del error en la capa oculta:

173
Actualización de los pesos que conectan la capa oculta con la capa de salida:
Para los pesos conectados de la capa oculta con la entrada:

174
Backpropagation (sentividad)
")
175
Las sensitividades, empezando desde la última hasta la primera capa.
tansig purelin

176
Luego de encontrar el valor del gradiente del error se procede a actualizar los pesos.
Para la actualización de los pesos que conectan la capa oculta con la capa de salida: Para la actualización de los pesos que conectan la capa de entrada con la capa oculta:

Presentaciones similares






















>")



 Se propone lograr que las computadoras se comporten de manera que podamos reconocerlas como inteligentes. Tiene por.>")

 - Francisco García Fernández. Dr. Ingeniero de Montes - Luis García Esteban. Dr. Ingeniero.>")