Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Problemas estadísticos habituales: confusión, missings, multiplicidad

2
OUTLINE

3
Outline Interacción, factores de confusión y subgrupos Multiplicidad
Missing data Otros: Análisis intermedios Ajustes por covariables Superioridad vs No-Inferioridad Meta-análisis Med Clin (Barc.) 2005;125(Supl. 1):72-76
 2005;125(Supl. 1):")
4
INTERACCIÓN, FACTORES DE CONFUSIÓN Y SUBGRUPOS

5
Interacción Presencia de un efecto modificador de la intensidad o sentido de la relación entre diferentes estratos de una variable. Ejemplos: Sexo con tratamiento. Centro con tratamiento. Edad con tratamiento.

6
Interacción Edad >= 45 años IM Hábito de fumar No Sí Sí 9 34

7
Interacción % IM 15 Edad >= 45 años 10 5 Edad < 45 años
No Fumador Fumador

8
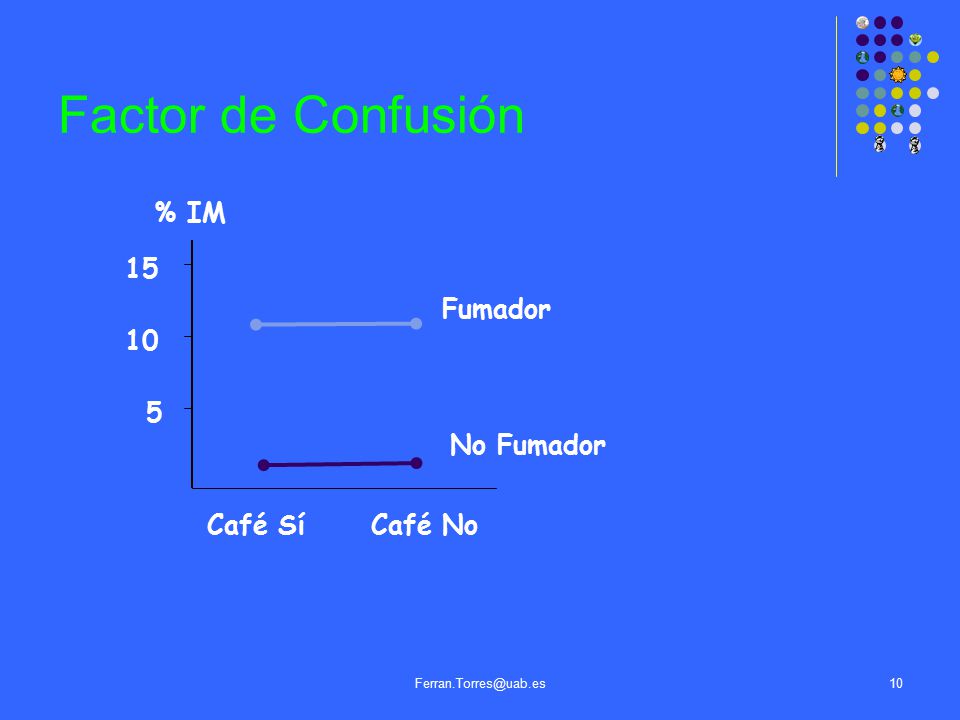
Factores de confusión Categoría especial de sesgos que cumplen:
1) Son factores de riesgo para la enfermedad (o la variable en estudio). 2) Se asocian a la exposición (o la intervención) en estudio. 3) No son pasos o factores intermedios.
 Son factores de riesgo para la enfermedad (o la variable en estudio). 2) Se asocian a la exposición (o la intervención) en estudio. 3) No son pasos o factores intermedios.")
9
Factores de confusión Fumadores IM Café No Sí Sí 10 40 NO 490 460
No fumadores IM Café No Sí Sí 8 7 No 1.67% 1.67% d=0% 10% 10% d=0%

10
Factor de Confusión % IM 15 Fumador 10 5 No Fumador Café Sí Café No
11
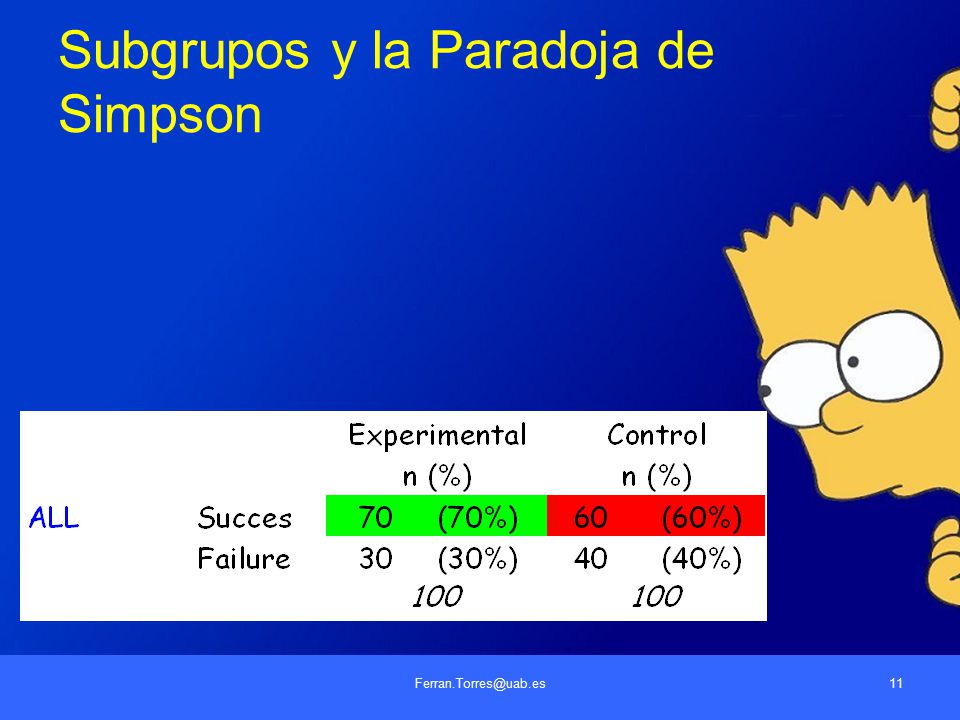
Subgrupos y la Paradoja de Simpson
12
Paradoja de Simpson continuación

13
Estudios de Subgrupos Estudio ISIS-2: Muerte vascular por subgrupos de zodiaco Geminis/Libra Otros Signos Aspirina Placebo Aspirina Placebo Muerte vascular Total 11.1% 10.2% p= d=-0.9 Muerte vascular Total 9.0% 12.1% p< d=3.1 ISIS-2 Collaborative Group. Randomised trial of intravenous streptokinase, oral aspirin, both, or neither among 17,187 cases of suspected acute myocardial infarction: ISIS-2. Lancet 1988; 2: 349–60. Interacción p = 0.019 Lancet 1988; 2: 349–60.

14
Cambios a raíz del ISIS-2
Lancet 2005; 365: 1657–61

15
“The answer to a randomized controlled trial that does not confirm one’s beliefs is not the conduct of several subanalyses until one can see what one believes. Rather, the answer is to re-examine one’s beliefs carefully.” BMJ 1999; 318: 1008–09.

16
Lancet 2005; 365: 1657–61

17
Subgrupos Recomendaciones: (Pocock, Simon, Peto)
1) Examinar el en subgrupos sólo si el efecto global es significativo 2) Examinar subgrupos sólo si la interacción es significativa 3) Plantearse ajustes de en función de los objetivos 4) Aspectos que aumentan la credibilidad: Pre-especificación en protocolo Evaluar la plausibilidad biológica
 Examinar el en subgrupos sólo si el efecto global es significativo. 2) Examinar subgrupos sólo si la interacción es significativa. 3) Plantearse ajustes de en función de los objetivos. 4) Aspectos que aumentan la credibilidad: Pre-especificación en protocolo. Evaluar la plausibilidad biológica.")
18
Lancet 2005; 365: 176–86

19
MULTIPLICIDAD

20
Ley de Murphy de la Investigación
Una cantidad de investigación suficiente nos permitirá probar cualquier teoría

21
Multiplicidad K hipótesis independientes: H01 , H02 , ... , H0K
S resultados significativos ( p<a ) Pr (S 1 | H01 H02 ... H0K = H0.) = Pr (S=0|H0.) = 1- (1 - a)K
 Pr (S 1 | H01 H02 ... H0K = H0.) = 1 - Pr (S=0|H0.) = 1- (1 - a)K.")
22
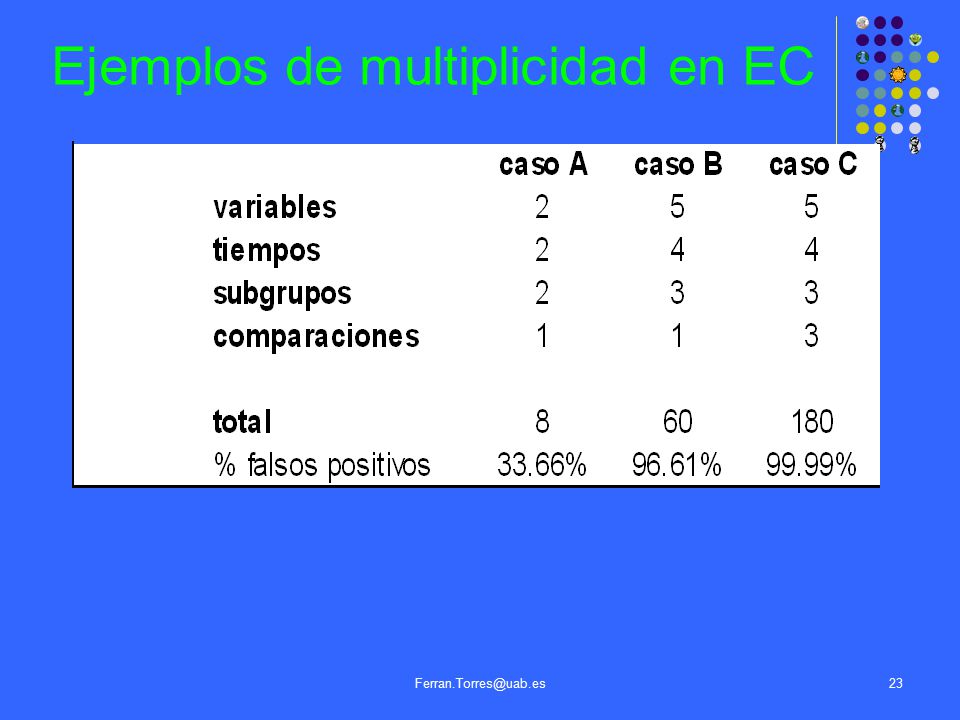
Fuentes de Multiplicidad en EC
Múltiples criterios de evaluación Múltiples tiempos de observación (medidas repetidas) Múltiples análisis (intermedios, secuenciales) Múltiples comparaciones: diseños con más de dos tratamientos subgrupos
 Múltiples análisis (intermedios, secuenciales) Múltiples comparaciones: diseños con más de dos tratamientos. subgrupos.")
23
Ejemplos de multiplicidad en EC
24
Multiplicidad Corrección de Bonferroni Ejemplo:
K pruebas con un nivel de significación de Tomar como nivel de significación de cada prueba /k Ejemplo: 5 pruebas independientes Se pretende un nivel global del 5% Se toma como significativa una prueba si su nivel de significación es de 5% / 5= 1%

25
Lancet 2005; 365: 1591–95

26
Estrategias para ‘cargar’ con los múltiples contrastes de un Ensayo clínico

27
Manejo de la multiplicidad
Escenario 1: Una única variable Identificar una variable principal y el resto son secundarias El EC es concluyente si la variable principal es significativa (valor de p <= 0.05, p.e.) El cálculo del tamaño de la muestra depende sólo de la variable principal.
 El cálculo del tamaño de la muestra depende sólo de la variable principal.")
29
Manejo de la multiplicidad
Escenario 2 Dividir el Error de Tipo I Identificar dos o más variables principales Dividir el error de Tipo I global, 0.05, entre estas variables principales, por ejemplo: 0.04 para la primera y 0.01 para la segunda. El EC es concluyente si una de las variables principales es significativa. Se calcula el tamaño de la muestra para cada una de las variables por separado, utilizando el valor de Error de Tipo I especificado para cada una de ellas, y se utiliza el mayor de todos ellos.

30
Manejo de la multiplicidad
Escenario 3 Procedimiento de Rechazo Secuencial Identificar n variables principales, p.e. n=3 Ordenar los valores de p del mayor al menor. Se evalúa la primera variable con el valor de p mayor, si es significativa al 0.05, se evalúa la segunda variable con el mayor valor de p con un nivel de significación de 0.05/2, en caso de ser significativa se evalúa la tercera con un valor de p de 0.05/3. El procedimiento se detiene en el momento que no se obtiene significación estadística en alguno de los pasos (Hochberg)
")
31
Manejo de la multiplicidad
Escenario 3 (continuación) El EC resulta concluyente si la primera variable es significativa. Para el cálculo del tamaño de la muestra se utilizará un Error de Tipo I de 0.05/n y se deberá realizar para cada una de las variables que se analicen como principales. Se resuelve seleccionando el mayor de ellos.
 El EC resulta concluyente si la primera variable es significativa. Para el cálculo del tamaño de la muestra se utilizará un Error de Tipo I de 0.05/n y se deberá realizar para cada una de las variables que se analicen como principales. Se resuelve seleccionando el mayor de ellos.")
32
Manejo de la multiplicidad
Escenario 4 Jerárquico Se pre-especifica la jerarquía de las n variables principales. Se evalúa si la 1ª variables es significativa al 0.05, si lo es se comprueba la 2ª al 0.05, si lo es se comprueba la 3ª al 0.05 de significación. Se detiene en el momento que una de las variables no resulta significativa. El EC es concluyente si la primera variable principal observada resulta significativa. Calcular la N separadamente para cada variable al 5%

33
Variables secundarias
Sentido de las variables secundarias como “confirmatorias”: La variable primaria presenta resultados significativos y Las comparaciones realizadas en las variables secundarias también están ‘protegidas’ bajo el mismo Error de Tipo I que la variable principal. Se indican también procedimientos similares a los comentados para la protección del Error de tipo I entre las variables secundarias.

34
Análisis intermedios En EC de larga duración, se pueden planificar inspecciones intermedias formales (interim analysis) con el fin de Investigar evidencias abrumadoras de eficacia a favor de E, con lo que sería posible parar prematuramente el EC y concluir superioridad de E respecto a C Investigar la inutilidad del EC, p.e. que la eficacia de E respecto a C fuese tan insignificante que no suponga una evidencia clara de obtener resultados positivos. Por temas de seguridad, análogamente a lo comentado para eficacia.

35
Interim Analyses in the CDP
Z Value +2 +1 -1 -2 Month of Follow-up Z values comparing clofibrate to pbo in the CDP. Somewhat idealized to show almost constant monitoring. (Month 0 = March 1966, Month 100 = July 1974) Coronary Drug Project Mortality Surveillance Circulation. 1973;47:I-1
 Coronary Drug Project Mortality Surveillance. Circulation. 1973;47:I-1. order=23.")
36
Lancet 2005; 365: 1657–61

37
Diseño SÍ aplicable a método secuencial
Reclutamiento Análisis Desarrollo total

38
Métodos secuenciales por grupos
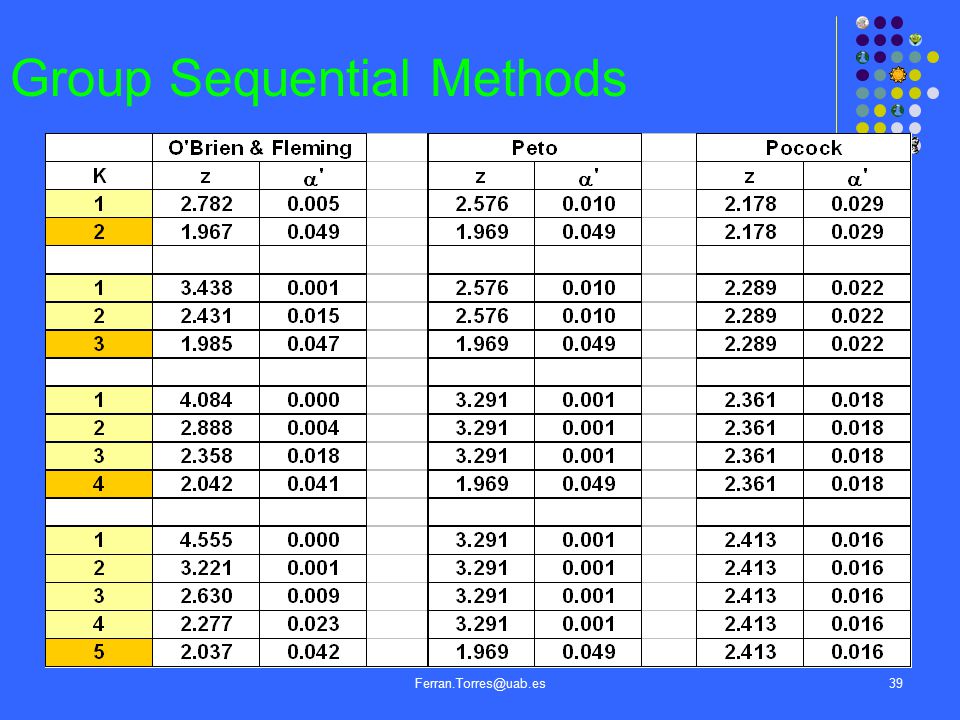
Pocock (1977) Pruebas de significación repetidas K = Nº máximo de inspecciones a realizar K fijo a priori Análisis con pruebas estadísticas clásicas (2, t-test, ...)
 Pruebas de significación repetidas. K = Nº máximo de inspecciones a realizar. K fijo a priori. Análisis con pruebas estadísticas clásicas (2, t-test, ...)")
39
Group Sequential Methods
40
“MISSING DATA”

41
Evolución de los sujetos

42
Ex: LOCF & lineal extrapolation lineal
> Worse 36 32 28 24- 20 16 12 8 4 Lineal Regresion Bias Adas-Cog LOCF < Better Time (months)
")
43
Ex: Early drop-out due to AE
> Worse 36 32 28 24- 20 16 12 8 4 Bias: Favours Active Placebo Adas-Cog Active < Better Time (months)
")
44
Ex: Early drop-out due to lack of Efficacy
> Worse 36 32 28 24- 20 16 12 8 4 Bias: Favours Placebo Placebo Adas-Cog Active < Better Time (months)
")
45
Drop-outs and missing data
≠ Frecuencies Baseline Visit 1 Visit 2 Last Visit A A A B A A A A B B A A RND

46
Drop-outs and missing data
≠ Timing Baseline Visit 1 Visit 2 Last Visit A A A A A B B B B B RND

47
Handling of MD Methods for imputation:
Many techniques No gold standard for every situation In principle, all methods may be valid: Simple methods to more complex: From LOCF to multiple imputation methods Worst Case, “Mean methods” But their appropriateness has to be justified Statistical approaches less sensitive to MD: Mixed models Survival models They assume no relationship between treatment and the missing outcome, and generally this cannot be assumed

Presentaciones similares








 Noviembre de 2004.>")











