Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Arquitectura de sistemas de bases de datos
ING. MARCO ZARATE Arquitectura de sistemas de bases de datos

2
Sistemas de bases de datos cliente-servidor.
Sistemas de bases de datos paralelos Sistemas distribuidos de bases de datos La arquitectura de un sistema de bases de datos está influenciada en gran medida por el sistema informático subyacente en el que se ejecuta, en particular por aspectos de la arquitectura de la computadora como la conexión en red, el paralelismo y la distribución:

3
ARQUITECTURAS CENTRALIZADAS Y CLIENTE-SERVIDOR
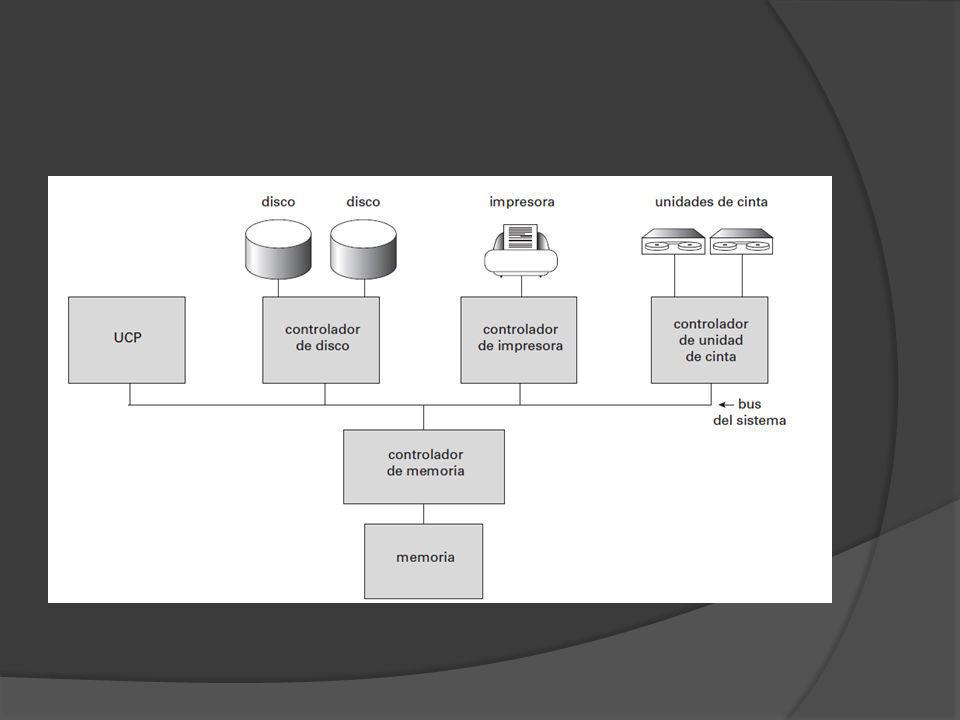
Sistemas Centralizados Bus comun para todos los controladores Discos duros Impresoras Controladores de video Sistema Monousuario Sistema Multiusuario Los sistemas de bases de datos centralizados son aquellos que se ejecutan en un único sistema informático sin interaccionar con ninguna otra computadora. Tales sistemas comprenden el rango desde los sistemas de bases de datos monousuario ejecutándose en computadoras personales hasta los sistemas de bases de datos de alto rendimiento ejecutándose en grandes sistemas. Por otro lado, los sistemas cliente-servidor tienen su funcionalidad dividida entre el sistema servidor y múltiples sistemas clientes.

5
ARQUITECTURAS CENTRALIZADAS Y CLIENTE-SERVIDOR
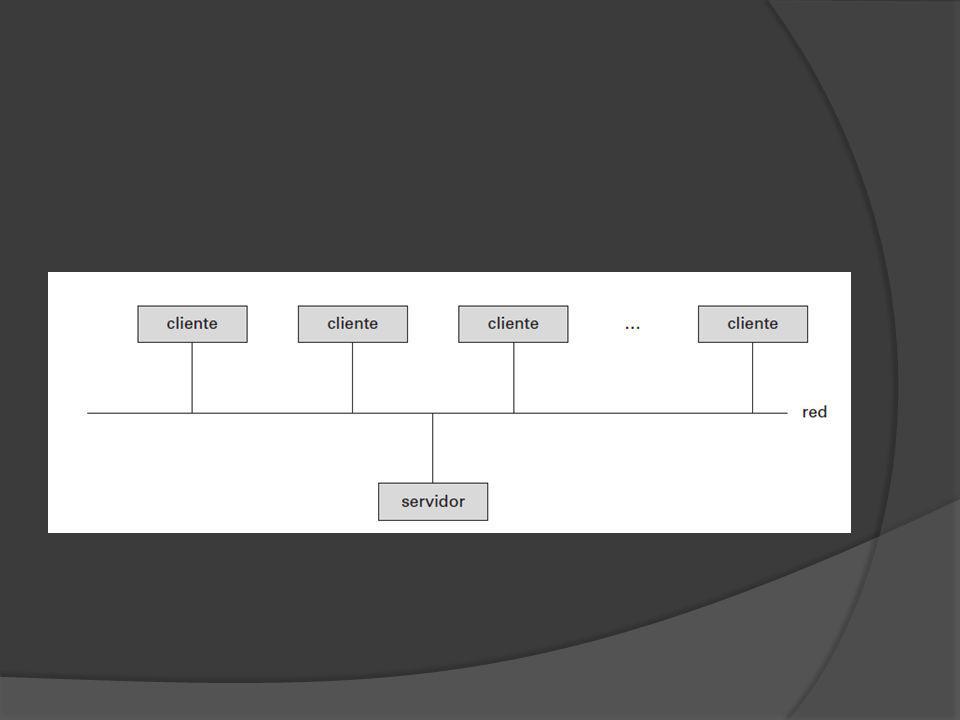
Sistemas Cliente-Servidor la parte visible al usuario y el sistema subyacente El sistema subyacente gestiona el acceso a las estructuras, la evaluación y optimización de consultas, el control de concurrencia y la recuperación. La parte visible al usuario de un sistema de base de datos está formado por herramientas como formularios, diseñadores de informes y facilidades gráficas de interfaz de usuario. La interfaz entre la parte visible al usuario y el sistema subyacente puede ser SQL o una aplicación. Las normas como ODBC y JDBC, se desarrollaron para hacer de interfaz entre clientes y servidores. Cualquier cliente que utilice interfaces ODBC o JDBC puede conectarse a cualquier servidor que proporcione esta interfaz.

7
ARQUITECTURAS DE SISTEMAS SERVIDORES
Servidores de transacciones Sistemas servidores de datos Los sistemas servidores de transacciones, también llamados sistemas servidores de consultas, proporcionan una interfaz a través de la cual los clientes pueden enviar peticiones para realizar una acción que el servidor ejecutará y cuyos resultados se devolverán al cliente. Normalmente, las máquinas cliente envían las transacciones a los sistemas servidores, lugar en el que estas transacciones se ejecutan, y los resultados se devuelven a los clientes que son los encargados de visualizar los datos. Las peticiones se pueden especificar utilizando SQL o mediante la interfaz de una aplicación especializada. Los sistemas servidores de datos permiten a los clientes interaccionar con los servidores realizando peticiones de lectura o modificación de datos en unidades tales como archivos o páginas. Por ejemplo, los servidores de archivos proporcionan una interfaz de sistema de archivos a través de la cual los clientes pueden crear, modificar, leer y borrar archivos. Los servidores de datos de los sistemas de bases de datos ofrecen muchas más funcionalidades; soportan unidades de datos de menor tamaño que los archivos, como páginas, tuplas u objetos. Proporcionan facilidades de indexación de los datos, así como facilidades de transacción de modo que los datos nunca se quedan en un estado inconsistente si falla una máquina cliente o un proceso

8
Estructura de procesos del servidor de transacciones
Procesos servidor Proceso gestor de bloqueos Proceso escritor de bases de datos Proceso escritor del registro Proceso punto de revisión Proceso monitor de proceso • Procesos servidor: son procesos que reciben consultas del usuario (transacciones), las ejecutan, y devuelven los resultados. Las consultas deben enviarse a los procesos servidor desde la interfaz de usuario, o desde un proceso de usuario que ejecuta SQL incorporado, o a través de JDBC, ODBC o protocolos similares. Algunos sistemas de bases de datos utilizan un proceso distinto para cada sesión de usuario, y algunas utilizan un único proceso de la base de datos para todas las sesiones del usuario, pero con múltiples hebras de forma que se pueden ejecutar concurrentemente múltiples consultas. (Una hebra es como un proceso, pero varias hebras se ejecutan como parte del mismo proceso, y todas las hebras dentro de un proceso se ejecutan en el mismo espacio de memoria virtual. Dentro de un proceso se pueden ejecutar concurrentemente múltiples hebras.) Algunos sistemas de bases de datos utilizan una arquitectura híbrida, con procesos múltiples, cada uno de ellos con varias hebras. • Proceso gestor de bloqueos: este proceso implementa una función de gestión de bloqueos que incluye concesión de bloqueos, liberación de bloqueos y detección de interbloqueos. • Proceso escritor de bases de datos: hay uno o más procesos que vuelcan al disco los bloques de memoria intermedia modificados de forma continua. • Proceso escritor del registro: este proceso genera entradas del registro en el almacenamiento estable a partir de la memoria intermedia del registro. Los procesos servidor simplifican la adición de entradas a la memoria intermedia del registro en memoria compartida y, si es necesario forzar la escritura del registro, le piden al proceso escritor del registro que vuelque las entradas del registro. • Proceso punto de revisión: este proceso realiza periódicamente puntos de revisión. • Proceso monitor de proceso: este proceso observa otros procesos y, si cualquiera de ellos falla, realiza acciones de recuperación para el proceso, tales como cancelar cualquier transacción que estuviera ejecutando el proceso fallido, y reinicia el proceso.
, las ejecutan, y devuelven los resultados. Las consultas deben enviarse a los procesos servidor desde la interfaz de usuario, o desde un proceso de usuario que ejecuta SQL incorporado, o a través de JDBC, ODBC o protocolos similares. Algunos sistemas de bases de datos utilizan un proceso distinto para cada sesión de usuario, y algunas utilizan un único proceso de la base de datos para todas las sesiones del usuario, pero con múltiples hebras de forma que se pueden ejecutar concurrentemente múltiples consultas. (Una hebra es como un proceso, pero varias hebras se ejecutan como parte del mismo proceso, y todas las hebras dentro de un proceso se ejecutan en el mismo espacio de memoria virtual. Dentro de un proceso se pueden ejecutar concurrentemente múltiples hebras.) Algunos sistemas de bases de datos utilizan una arquitectura híbrida, con procesos. múltiples, cada uno de ellos con varias hebras. • Proceso gestor de bloqueos: este proceso implementa una función de gestión de bloqueos que incluye concesión de bloqueos, liberación de bloqueos y detección de interbloqueos. • Proceso escritor de bases de datos: hay uno o más procesos que vuelcan al disco los bloques de memoria intermedia modificados de forma continua. • Proceso escritor del registro: este proceso genera entradas del registro en el almacenamiento estable a partir de la memoria intermedia del registro. Los procesos servidor simplifican la adición de entradas a la memoria intermedia del registro en memoria compartida y, si es necesario forzar la escritura del registro, le piden al proceso escritor del registro que vuelque las entradas del registro. • Proceso punto de revisión: este proceso realiza periódicamente puntos de revisión. • Proceso monitor de proceso: este proceso observa otros procesos y, si cualquiera de ellos falla, realiza acciones de recuperación para el proceso, tales como cancelar cualquier transacción que estuviera ejecutando el proceso fallido, y reinicia el proceso.")
9
Servidores de datos Caché de datos Caché de bloqueos
Envío de páginas o envío de elementos Bloqueo Caché de datos Caché de bloqueos • Envío de páginas o envío de elementos. La unidad de comunicación de datos puede ser de grano grueso, como una página, o de grano fino, como una tupla (o, en el contexto de los sistemas de bases de datos orientados a objetos, un objeto). Se usará el término elemento para referirse tanto a tuplas como a objetos. Si la unidad de comunicación de datos es un único elemento, la sobrecarga por la transferencia de mensajes es alta comparada con el número de datos transmitidos. En vez de hacer esto, cuando se necesita un elemento, cobra sentido la idea de enviar junto a aquél otros elementos que probablemente vayan a ser utilizados en un futuro próximo. Se denomina preextracción a la acción de buscar y enviar elementos antes de que sea estrictamente necesario. Si varios elementos residen en un página, el envío de páginas puede considerarse como una forma de preextracción, ya que, cuando un proceso desee acceder a un único elemento de la página, se enviarán todos los elementos de esa página. • Bloqueo. La concesión del bloqueo de los elementos de datos que el servidor envía a los clientes la realiza habitualmente el propio servidor. Un inconveniente del envío de páginas es que los clientes pueden recibir bloqueos de grano grueso: el bloqueo de una página bloquea implícitamente a todos los elementos que residan en ella. El cliente adquiere implícitamente bloqueos sobre todos los elementos preextraídos incluso aunque no esté accediendo a algunos de ellos. De esta forma, puede detenerse innecesariamente el procesamiento de otros clientes que necesiten bloquear esos elementos. Se han propuesto algunas técnicas para la liberación de bloqueos en las que el servidor puede pedir a los clientes que le devuelvan el control sobre los bloqueos de los elementos preextraídos. Si el cliente no necesita el elemento preextraído puede devolver los bloqueos sobre ese elemento al servidor para que éstos puedan ser asignados a otros clientes. • Caché de datos. Los datos que se envían al cliente en favor de una transacción se pueden alojar en una caché del cliente incluso una vez completada la transacción, si dispone de suficiente espacio de almacenamiento libre. Las transacciones sucesivas en el mismo cliente pueden hacer uso de los datos en caché. Sin embargo, se presenta el problema de la coherencia de caché: si una transacción encuentra los datos en la caché, debe asegurarse de que esos datos están al día, ya que, después de haber sido almacenados en la caché, pueden haber sido modificados por otro cliente. Así, debe establecerse una comunicación con el servidor para comprobar la validez de los datos y poder adquirir un bloqueo sobre ellos. • Caché de bloqueos. Los bloqueos también pueden ser almacenados en la memoria caché del cliente si la utilización de los datos está prácticamente dividida entre los clientes, de manera que un cliente rara vez necesita datos que están siendo utilizados por otros clientes. Supóngase que se encuentran en la memoria caché tanto el elemento de datos que se busca como el bloqueo requerido para acceder al mismo. Entonces, el cliente puede acceder al elemento de datos sin necesidad de comunicar nada al servidor. No obstante, el servidor debe seguir el rastro de los bloqueos en caché; si un cliente solicita un bloqueo al servidor, éste debe comunicar a todos los bloqueos sobre el elemento de datos que se encuentren en las memorias caché de otros clientes. La tarea se vuelve más complicada cuando se tienen en cuenta los posibles fallos de la máquina. Esta técnica se diferencia de la liberación de bloqueos en que la caché de bloqueo se realiza a través de transacciones; de otra forma, las dos técnicas serían similares.
. Se usará el término elemento para referirse tanto a tuplas como a objetos. Si la unidad de comunicación de datos es un único elemento, la sobrecarga por la transferencia de mensajes es alta comparada con el número de datos transmitidos. En vez de hacer esto, cuando se necesita un elemento, cobra sentido la idea de enviar junto a aquél otros elementos que probablemente vayan a ser utilizados en un futuro próximo. Se denomina preextracción a la acción de buscar y enviar elementos antes de que sea estrictamente necesario. Si varios elementos residen en un página, el envío de páginas puede considerarse como una forma de preextracción, ya que, cuando un proceso desee acceder a un único elemento de la página, se enviarán todos los elementos de esa página. • Bloqueo. La concesión del bloqueo de los elementos de datos que el servidor envía a los clientes la realiza habitualmente el propio servidor. Un inconveniente del envío de páginas es que los clientes pueden recibir bloqueos de grano grueso: el bloqueo de una página bloquea implícitamente a todos los elementos que residan en ella. El cliente adquiere implícitamente bloqueos sobre todos los elementos preextraídos incluso aunque no esté accediendo a algunos de ellos. De esta forma, puede detenerse innecesariamente el procesamiento. de otros clientes que necesiten bloquear esos elementos. Se han propuesto algunas técnicas para la liberación de bloqueos en las que el servidor puede pedir a los clientes que le devuelvan el control sobre los bloqueos de los elementos preextraídos. Si el cliente no necesita el elemento preextraído puede devolver los bloqueos sobre ese elemento al servidor para que éstos puedan ser asignados a otros clientes. • Caché de datos. Los datos que se envían al cliente en favor de una transacción se pueden alojar en una caché del cliente incluso una vez completada la transacción, si dispone de suficiente espacio de almacenamiento libre. Las transacciones sucesivas en el mismo cliente pueden hacer uso de los datos en caché. Sin embargo, se presenta el problema. de la coherencia de caché: si una transacción encuentra los datos en la caché, debe asegurarse de que esos datos están al día, ya que, después de haber sido almacenados en la caché, pueden haber sido modificados por otro cliente. Así, debe establecerse una comunicación con el servidor para comprobar la validez de los datos y poder adquirir un bloqueo sobre ellos. • Caché de bloqueos. Los bloqueos también pueden ser almacenados en la memoria caché del cliente si la utilización de los datos está prácticamente dividida entre los clientes, de manera que un cliente rara vez necesita datos que están siendo utilizados por otros clientes. Supóngase que se encuentran en la memoria caché tanto el elemento de datos que se busca como el bloqueo requerido para acceder al mismo. Entonces, el cliente puede acceder al elemento de datos sin necesidad de comunicar nada al servidor. No obstante, el servidor. debe seguir el rastro de los bloqueos en caché; si un cliente solicita un bloqueo al servidor, éste debe comunicar a todos los bloqueos sobre el elemento de datos que se encuentren en las memorias caché de otros clientes. La tarea se vuelve más complicada cuando se tienen en cuenta los posibles fallos de la máquina. Esta técnica se diferencia. de la liberación de bloqueos en que la caché de bloqueo se realiza a través de transacciones; de otra forma, las dos técnicas serían similares.")
10
SISTEMAS PARALELOS Productividad Tiempo de Respuesta
Una máquina paralela de grano grueso consiste en un pequeño número de potentes procesadores; una máquina masivamente paralela o de grano fino utiliza miles de procesadores más pequeños. (1) la productividad, número de tareas que pueden completarse en un intervalo de tiempo determinado, y (2) el tiempo de respuesta, cantidad de tiempo que necesita para completar una única tarea a partir del momento en que se envíe.
 la productividad, número de tareas que pueden completarse en un intervalo de tiempo determinado, y (2) el tiempo de respuesta, cantidad de tiempo que necesita para completar una única tarea a partir del momento en que se envíe.")
11
Sistema paralelos Ganacia de velocidad y ampliabilidad
ampliabilidad por lotes ampliabilidad de transacciones Costes de inicio Interferencia. Sesgo. La ganancia de velocidad se refiere a la ejecución en menos tiempo de una tarea dada mediante el incremento del grado de paralelismo. La ampliabilidad se refiere al manejo de transacciones más largas mediante el incremento del grado de paralelismo. • En la ampliabilidad por lotes aumenta el tamaño de la base de datos, y las tareas son trabajos más largos cuyos tiempos de ejecución dependen del tamaño de la base de datos. • En la ampliabilidad de transacciones aumenta la velocidad con la que se envían las transacciones a la base de datos y el tamaño de la base de datos crece proporcionalmente a la tasa de transacciones. La ampliabilidad es normalmente el factor más importante para medir la eficiencia de un sistema paralelo de bases de datos.

12
Sistemas Paralelos Redes de Conexion
• Bus. Todos los componentes del sistema pueden enviar o recibir datos de un único bus de comunicaciones. El bus puede ser una red Ethernet o una interconexión paralela. Malla. Los componentes se organizan como los nodos de una retícula de modo que cada componente está conectado con todos los nodos adyacentes. En una malla bidimensional cada nodo está conectado con cuatro nodos adyacentes, mientras que en una malla tridimensional cada nodo está conectado con seis nodos adyacentes. • Hipercubo. Se asigna a cada componente un número binario de modo que dos componentes tienen una conexión directa si sus correspondientes representaciones binarias difieren en un solo bit.

13
Arquitecturas paralelas de bases de datos
• Memoria compartida. Todos los procesadores comparten una memoria común. • Disco compartido. Todos los procesadores comparten un conjunto de discos común. • Sin compartimiento. Los procesadores no comparten ni memoria ni disco. • Jerárquico. Este modelo es un híbrido de las arquitecturas anteriores.

14
SISTEMAS DISTRIBUIDOS
Varias PCs conectadas entre si Datos compartidos Autonomía Disponibilidad. Una transacción local es aquella que accede a los datos del único sitio en el cual se inició la transacción. Por otra parte, una transacción global es aquella que, o bien accede a los datos situados en un sitio diferente de aquel en el que se inició la transacción, o bien accede a datos de varios sitios distintos.

Presentaciones similares






 de la red. Maneja información.>")


.>")






.>")
 Migule Ángel Azorín>")

