Descargar la presentación
La descarga está en progreso. Por favor, espere

1
INSTITUTO POLITÉCNICO NACIONAL CENTRO DE INVESTIGACIÓN EN COMPUTACIÓN LABORATORIO DE SISTEMAS DIGITALES Grupo de Arquitectura de Computadoras y Sistemas Embebidos Tecnología de Memoria

2
DRAM Memorias de Acceso Aleatorio Dinámicas
Requiere de señales refresco de datos Alta integración Tiempos de acceso 50ns – 70ns (lentas) Precio $20 – $75 Dls por GB
 Precio $20 – $75 Dls por GB ")
3
SRAM Memorias de Acceso Aleatorio Estáticas
No requiere de señales refresco de datos Mediana integración Tiempos de acceso 0.5ns – 2.5ns (rápidas) Precio $2000 – $5000 per GB
 Precio $2000 – $5000 per GB ")
4
Otras Tecnologías de Memoria

5
MEMORIA CACHE (1995)
")
6
MEMORIA CACHE (2008) IBM Power7
 IBM Power7")
7
SRAM Diseño y Fabricación

8
INVERSOR CMOS PMOS NMOS VSS VDD INPUT OUTPUT Software de diseño: Spice, Calibre, Tanner, Mentor Graphics, microwind, etc.

9
CELDA SRAM Diseñada con un par de inversores retroalimentados, para crear arreglos de celdas

10
FABRICACIÓN CMOS

11
Fabricación sobre sustratos de silicio
CELDA SRAM Fabricación sobre sustratos de silicio

12
Diseño de la Jerarquía de Memoria
Objetivos: Diseño y evaluación de la jerarquía de memoria basada en tres conceptos: * Hacer el caso común rápido. * Principio de localidad (Temporal y Espacial). * Los circuitos pequeños son mas rápidos. Las evaluaciones se realizaran usando CACTI-3.2 (consumo y tiempo de ciclo) y SimpleScalar 3.0d para evaluar desempeño. Solo para la gente interesada en diseño , se usaran herramientas como HDL y FPGA’s, Tanner, Mentor Graphics, con que cuenta MICROSE
. * Los circuitos pequeños son mas rápidos. Las evaluaciones se realizaran usando CACTI-3.2 (consumo y tiempo de ciclo) y SimpleScalar 3.0d para evaluar desempeño. Solo para la gente interesada en diseño , se usaran herramientas como HDL y FPGA’s, Tanner, Mentor Graphics, con que cuenta MICROSE.")
13
Diseño de la Jerarquía de Memoria
Problema: Los tiempos de acceso (IF, MEM) están limitados por la velocidad del procesador (CLK). Solución: Dividir la cache en memoria para búsqueda de instrucciones (IL1) y en memoria de acceso de datos (DL1): - Se asume latencia de HIT para determinar el periodo de reloj del pipeline. Se para (STALL) el procesador en fallos (misses). Variantes: Separadas las Memorias Cache de I & D - Cache L1 en el chip del CPU y L2 - L3 fuera del chip. Cache L1 y L2 en el chip del CPU, L3 fuera del chip. Cache L1, L2 y L3 en el Chip.
 están limitados por la velocidad del procesador (CLK). Solución: Dividir la cache en memoria para búsqueda de instrucciones (IL1) y en memoria de acceso de datos (DL1): - Se asume latencia de HIT para determinar el periodo de reloj del pipeline. Se para (STALL) el procesador en fallos (misses). Variantes: Separadas las Memorias Cache de I & D. - Cache L1 en el chip del CPU y L2 - L3 fuera del chip. Cache L1 y L2 en el chip del CPU, L3 fuera del chip. Cache L1, L2 y L3 en el Chip.")
14
Diseño de la Jerarquía de Memoria
“Ideally one would desire an indefinitely large memory capacity such that any particular… word would be immediately available…” “We are… forced to recognize the possibility of constructing a hierarchy of memory , each of which has greater capacity than the preceding but which is less quickly accessible…” A. W. Burks, H. H. Golstine and J. Von Newmann Preliminary Discussion of the Logical Design of an Electric Computing Instrument,1946 David A. Patterson and John L. Hennessy, Computer Organization & Design, 2nd Edition

15
Diseño de la Jerarquía de Memoria
Localidad Temporal (localidad en el tiempo): si un dato es referenciado, este tiende a ser referenciado de nuevo pronto. Localidad Espacial (localidad en el espacio): si un dato es referenciado, los datos cuyas direcciones están cercanas a este, tienden a ser referenciados pronto.
: si un dato es referenciado, este tiende a ser referenciado de nuevo pronto. Localidad Espacial (localidad en el espacio): si un dato es referenciado, los datos cuyas direcciones están cercanas a este, tienden a ser referenciados pronto.")
16
Existen varios niveles en una jerarquía de memoria típica:
Diseño de la Jerarquía de Memoria Existen varios niveles en una jerarquía de memoria típica:

17
Diseño de la Jerarquía de Memoria
En cada nivel, la unidad de información que esta presente o no es llamada un bloque (BLOCK). Usualmente se transfiere un bloque entero cuando se transfiere información entre niveles.
. Usualmente se transfiere un bloque entero cuando se transfiere información entre niveles.")
18
Diseño de la Jerarquía de Memoria
Cache de Mapeo Directo L1: con 8-Localidades Memoria L2: 0-31 direcciones se mapean a las 8-localidades de Cache L1. Porque cada localidad de la cache L1 puede contener datos de diferentes localidades de memoria L2. Preguntas: ¿Como puedo saber si la palabra que se busca esta en cache L1 o no? ¿Como puedo saber si el dato en la cache L1, corresponde a la misma palabra requerida en L2?

19
Diseño de Memoria Cache L1
Accediendo a Cache L1 Index V Tag Data 000 N 001 010 011 100 101 110 111

20
Accediendo Cache L1, Dirección: 10110 (22d)
Diseño de Memoria Cache L1 Accediendo Cache L1, Dirección: (22d) Index V Tag Data 000 N 001 010 011 100 101 110 Y 10 Memory(10110) 111 Miss
 Index. V. Tag. Data N Y. 10. Memory(10110) 111. Miss.")
21
Accediendo Cache L1, Dirección: 11010 (26d)
Index V Tag Data 000 N 001 010 Y 11 Memory(11010) 011 100 101 110 10 Memory(10110) 111 Miss
 Memory(10110) 111. Miss.")
22
Accediendo Cache L1, Dirección: 10110 (22d)
Index V Tag Data 000 N 001 010 011 Y 10 Memory(11110) 100 101 110 Memory(10110) 111 Hit
 Memory(10110) 111. Hit.")
23
Accediendo Cache L1, Dirección: 11010 (26d)
Index V Tag Data 000 N 001 010 Y 11 Memory(11010) 011 100 101 110 10 Memory(10110) 111 Hit
 Memory(10110) 111. Hit.")
24
Accediendo Cache L1, Dirección: 10000 (26d)
Index V Tag Data 000 Y 10 Memory(10000) 001 N 010 11 Memory(11010) 011 100 101 110 Memory(10110) 111 Miss
 001. N Memory(11010) Memory(10110) 111. Miss.")
25
Accediendo Cache L1, Dirección: 00011 (03d)
Index V Tag Data 000 Y 10 Memory(10000) 001 N 010 11 Memory(11010) 011 00 Memory(00011) 100 101 110 Memory(10110) 111 Miss
 001. N Memory(11010) Memory(00011) Memory(10110) 111. Miss.")
26
Accediendo Cache L1, Dirección: 10000 (16d)
Index V Tag Data 000 Y 10 Memory(10000) 001 N 010 11 Memory(11010) 011 00 Memory(00011) 100 101 110 Memory(10110) 111 Hit
 001. N Memory(11010) Memory(00011) Memory(10110) 111. Hit.")
27
Accediendo Cache L1, Dirección: 10010 (18d) -¡¡¡MISS!!!-
Index V Tag Data 000 Y 10 Memory(10000) 001 N 010 11 Memory(11010) 011 00 Memory(00011) 100 101 110 Memory(10110) 111 Miss
 001. N Memory(11010) Memory(00011) Memory(10110) 111. Miss.")
28
Accediendo Cache L1, Dirección: 10010 (16d) -¡¡¡Remplazo !!!-
Index V Tag Data 000 Y 10 Memory(10000) 001 N 010 Memory(10010) 011 00 Memory(00011) 100 101 110 Memory(10110) 111 Miss
 001. N Memory(10010) Memory(00011) Memory(10110) 111. Miss.")
29
Accediendo Cache L1 (Resumen)
Decimal Binary Address of reference Hit/Miss Assign Cache Block 22 10110 Miss 22 % 8 =6 26 11010 26 % 8 = 2 Hit 22 % 8 = 6 26 % 8 =2 16 10000 16 % 8 = 0 03 00011 3 % 8 = 3 18 10010 18 % 8 =2

30
Subdivisión de la Dirección de Memoria
Campos de dirección Index: Usado para Seleccionar el block. Tag: Usado para comparar con el valor del campo de Tag de la Cache. Offset: Usado para seleccionar el byte del campo de datos. 30

31
(MIPS R3000) Cache Contiene 16K Blocks de una palabra por bloque
DEC STATION CACHE (MIPS R3000) Cache Contiene 16K Blocks de una palabra por bloque 64KB = 16K words = 214 words Tag = = 16bits Data = 32 bits Valid bit = 1 bit Total Cache size= 214x( )=784Kbits=96KB 31
 Cache. Contiene 16K Blocks de una palabra por bloque. 64KB = 16K words = 214 words. Tag = = 16bits. Data = 32 bits. Valid bit = 1 bit. Total Cache size= 214x( )=784Kbits=96KB. 31.")
32
Aciertos y Fallos en Cache
Aciertos en Cache (HIT): EL CPU procede de forma normal. Fallos en Cache: -Se para el proceso de “Fetch” y se paran los demás estados del procesador. -Se remplaza el bloque del siguiente nivel de Cache. -Se restablece la etapa de “Fetch” -Se completa el acceso a memoria.
: EL CPU procede de forma normal. Fallos en Cache: -Se para el proceso de Fetch y se paran los demás estados del procesador. -Se remplaza el bloque del siguiente nivel de Cache. -Se restablece la etapa de Fetch -Se completa el acceso a memoria.")
33
MIPS R3000 Procesador de 32 bits, L1=64KB, Tec=1.2um

34
Midiendo el Desempeño de la Cache
Componentes de Tiempo de CPU Ciclos de ejecución de un programa Incluye tiempo de HIT en la Cache Ciclos de paro de Memoria Principalmente debido a fallos (MISS) en Cache
 en Cache.")
35
Ejemplo: Desempeño de la Cache
Dado I-Cache (MISS RATE) = 2% D-Cache(MISS RATE)= 4% Ciclos de Penalización (Miss Penalty) = 100 Ciclos Base CPI ( con Cache ideal)= 2 LD y ST son el 36% de las instrucciones Evaluando Ciclos por Instrucción (por penalización) I-Cache = 0.02 X 100 = 2 D-Cache=0.04 X 0.36 X 100 = 1.44 Ciclos de CPU por Paro de Memoria =2+1.44=3.44 CPI Actual CPI con Paro de Memoria =2+3.44=5.44 Tiempo de CPU Con Paro de Memoria/Tiempo de CPU ideal= IxCPIstallxCLK Cycle/IxCPIidealxCLK Cycle=5.44/2=2.72 mas rápido
 = 2% D-Cache(MISS RATE)= 4% Ciclos de Penalización (Miss Penalty) = 100 Ciclos. Base CPI ( con Cache ideal)= 2. LD y ST son el 36% de las instrucciones. Evaluando Ciclos por Instrucción (por penalización) I-Cache = 0.02 X 100 = 2. D-Cache=0.04 X 0.36 X 100 = Ciclos de CPU por Paro de Memoria =2+1.44=3.44. CPI Actual. CPI con Paro de Memoria =2+3.44=5.44. Tiempo de CPU Con Paro de Memoria/Tiempo de CPU ideal= IxCPIstallxCLK Cycle/IxCPIidealxCLK Cycle=5.44/2=2.72 mas rápido.")
36
Tiempo de Acceso Promedio
EL tiempo de HIT también es importante para el desempeño de la memoria. Average Memory Acces Time (AMAT) AMAT= HITtime+ MISSrate X MISSPenalty EJEMPLO: CPU Clktime = 1ns HITtime = 1Ciclo MISSPenalty = 20 Ciclos I-Cache MISSrate=5% AMAT=1+0.05X20=2ns (2 ciclos por instrucción)
 AMAT= HITtime+ MISSrate X MISSPenalty EJEMPLO: CPU Clktime = 1ns HITtime = 1Ciclo MISSPenalty = 20 Ciclos I-Cache MISSrate=5% AMAT=1+0.05X20=2ns (2 ciclos por instrucción)")
37
Desempeño de Memoria (Resumen)
Cuando el Desempeño del CPU es incrementado La penalización por fallos es mas significante Decrecer el CPI base Produce mayor proporción de tiempo gastado en paro de memoria por fallos Incrementar velocidades de CLK Paros de Memoria requieren mas ciclos de reloj No se puede ignorar el comportamiento de la cache cuando evaluamos el desempeño del sistema

38
Reduciendo Fallos en Cache
Por una organización de bloques mas flexible Completamente Asociativa Permite a un bloque dado ir a cualquier entrada de la cache. Requiere que todas las entradas sean buscadas a la vez Requiere un comprador por entrada (mayor consumo de energía) De conjunto asociativo de N-vias Cada conjunto contiene N-entradas Numero de Bloque determina el conjunto (BlockNumber) modulo (# de concjuntos en cache) Busca en todas las entradas de un conjunto dado Requiere N comparadores (menor consumo de energía)
 De conjunto asociativo de N-vias. Cada conjunto contiene N-entradas. Numero de Bloque determina el conjunto. (BlockNumber) modulo (# de concjuntos en cache) Busca en todas las entradas de un conjunto dado. Requiere N comparadores (menor consumo de energía)")
39
Ejemplo de Cache Asociativa
BlocLocation: (BlockNumber) modulo (# de concjuntos en cache) Localización del Bloque de datos: 12 % 8= % 4= % 1= En cualquier lugar
 modulo (# de concjuntos en cache) Localización del Bloque de datos: 12 % 8=4 12 % 4= 0 12 % 1=12 En cualquier lugar.")
40
Espectro de Asociatividad
Para Caches de 8 entradas

41
Comparación de Asociatividad en Cache
Cache de 4-bloques Secuencia de accesos 0, 8, 0, 6, 8 Mapeo Directo Block address Cache index Hit/miss Cache content after access 1 2 3 miss Mem[0] 8 Mem[8] 6 Mem[6]

42
Comparación de Asociatividad en Cache
Cache de 4-bloques Secuencia de accesos 0, 8, 0, 6, 8 Asociativa de 2-Conjuntos Block address Cache index Hit/miss Cache content after access Set 0 Set 1 miss Mem[0] 8 Mem[8] hit 6 Mem[6]

43
Comparación de Asociatividad en Cache
Cache de 4-bloques Secuencia de accesos 0, 8, 0, 6, 8 Totalmente Asociativa Block address Hit/miss Cache content after access miss Mem[0] 8 Mem[8] hit 6 Mem[6]

44
Cuanta Asociatividad es recomendable?
Incrmentar la Asociatividad disminuye los Fallos en Memoria (MISS rate) Simulacion de un sistema con 64KB D-cache, 16-Word por bloque, SPEC2000. 1-Conjunto: % 2-Conjuntos: 8.6% 4-Conjuntos: 8.3% 8-Conjuntos: 8.1%
 Simulacion de un sistema con 64KB D-cache, 16-Word por bloque, SPEC Conjunto: 10.3% 2-Conjuntos: 8.6% 4-Conjuntos: 8.3% 8-Conjuntos: 8.1%")
45
Organización de Cache de Conjuntos

46
Política de Remplazo Mapeo Directo: Conjunto Asociativo:
No hay elección Conjunto Asociativo: Elige una entrada no valida si hay una De otra forma elige entre las entradas del conjunto. Ultimo Recientemente Usado(LRU) Elige una no usada por largo tiempo Simple para 2-vias, Manejable para 4-vias, Compleja de 8 en adelante Aleatorio Da aproximadamente el mismo rendimiento que LRU para asociatividades altas
 Elige una no usada por largo tiempo. Simple para 2-vias, Manejable para 4-vias, Compleja de 8 en adelante. Aleatorio. Da aproximadamente el mismo rendimiento que LRU para asociatividades altas.")
47
Multinivel Cache Cache L1: Cercano al CPU Cache L2: sirve fallos de L1
Pequeña, pero de rápido acceso Cache L2: sirve fallos de L1 Grande, Lenta, pero aun mas rápida que Memoria Principal Memoria Principal, sirve fallos de L2 Algunos sistemas incluyen cache L3

48
Ejemplo de Memoria Multinivel
Dados CPU base CPI=1 Clock Rate= 4GHz (Cache L1)MISSrate/Instruction=2% (Memoria)AccessTime=100ns (Memoria)MISSpenalty=100ns/0.25ns=400 ciclos Evaluar el CPI efectivo: CPI efectivo=1+0.02X400=9
MISSrate/Instruction=2% (Memoria)AccessTime=100ns. (Memoria)MISSpenalty=100ns/0.25ns=400 ciclos. Evaluar el CPI efectivo: CPI efectivo=1+0.02X400=9.")
49
Ejemplo de Memoria Multinivel
Adicionamos ahora L2 Tiempo de Acceso: 5ns (Memoria) Global MISSrate: 0.5% Fallo en L1 con Acierto en L2: Penalización=5ns/0.25ns=20 Ciclos Fallo en L1 con Fallo en L2: Penalización extra=500 Ciclos Evaluar el CPI: CPI =1+0.02X X400=3.4 Relación de Desempeño= 9/3.4 = 2.6
 Global MISSrate: 0.5% Fallo en L1 con Acierto en L2: Penalización=5ns/0.25ns=20 Ciclos. Fallo en L1 con Fallo en L2: Penalización extra=500 Ciclos. Evaluar el CPI: CPI =1+0.02X X400=3.4. Relación de Desempeño= 9/3.4 = 2.6.")
50
Memoria Virtual El tamaño del direccionamiento del procesador, determina el tamaño de la memoria virtual, pero el tamaño de la cache es independiente del tamaño del direccionaiemto del procesador. 50

51
Memoria Virtual Los sistemas de memoria virtual pueden ser categorizados en dos clases: aquellos con tamaño fijo de bloques llamados páginas, y aquellos con bloques de tamaño variable llamados segmentos. 51

52
Mapeo de una Dirección Virtual a una Dirección Física
Vía una tabla de páginas 52

53
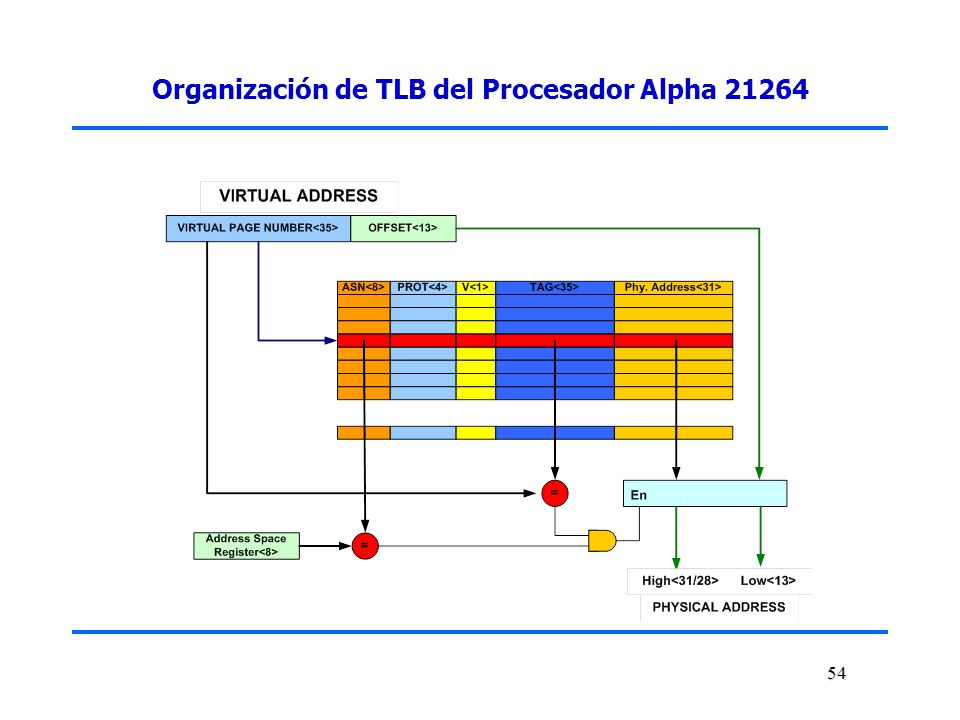
Organización del TLB del Procesador Alpha 21264
Una entrada de TLB es idéntica a una entrada de Cache, en dónde el campo TAG conserva una porción de la dirección virtual y el campo de DATOS conserva un número de trama de la página física, un número de protección, un bit de validez, un bit de uso (use bit) y un bit de página sucia/limpia (dirty bit). El Registro Address Space Number (ASN) es utilizado como un identificador de proceso ID para caches virtuales, por lo que el TLB no es limpiado (flushed) en un cambio de contexto, solo cuando los ASNs son reciclados. User, Supervisor, or Kernel mode address space 53 53
 y un bit de página sucia/limpia (dirty bit). El Registro Address Space Number (ASN) es utilizado como un identificador de proceso ID para caches virtuales, por lo que el TLB no es limpiado (flushed) en un cambio de contexto, solo cuando los ASNs son reciclados. User, Supervisor, or Kernel mode address space")
54
Organización de TLB del Procesador Alpha 21264
54 54
55
Organización de TLB y CACHE del Procesador Alpha 21264
64-bit Address which 44-/41-bit are translated 55 55

56
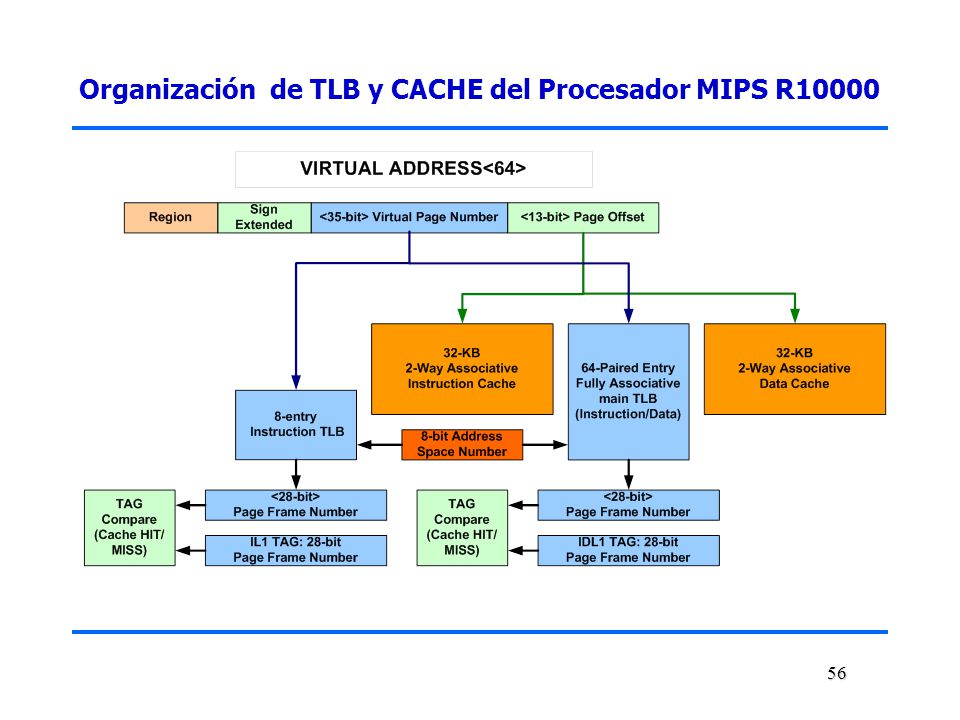
Organización de TLB y CACHE del Procesador MIPS R10000
56 56
57
Resumen de Memoria Virtual y Caches
57

Presentaciones similares
















>")



