Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Scheduling de multiprocesadores y sistema de tiempo real
Capítulo 10

2
Clasificación de sistemas multiprocesadores
Débilmente acoplados, sistemas distribuidos o clusters Cada procesador tiene su propia memoria y canales de I/O Los procesadores no comparten el reloj Procesadores especializados Generalmente esclavos de un procesador maestro Ejemplo: procesadores de I/O Áltamente acoplados Procesadores comparten memoria, un bus y el reloj Cada uno podría tener su propia memoria cache Controlados por El sistema operativo

3
Granularidad de la sincronización
Granularidad de la sincronización se refiere a la frecuencia con que los procesos se sincronizan También, incluye el tipo de tareas que se sincronizan, por ejemplo procesos versus hebras Cinco categorías de granularidad Independiente: Muy grueso (very coarse) Grueso (coarse) Medio Fino
 Grueso (coarse) Medio. Fino.")
4
Granularidad de la sincronización
Independiente No existe sincronización explícita entre los procesos Cada uno es un trabajo (job) independiente de los otros Ejemplo: sistemas multiusuarios de tiempo compatido. El scheduler no se ve afectado Gruesa o muy gruesa Existe algún tipo sincronización entre los procesos Ejemplo: procesos concurrentes Si los procesos se comunican muy poco, entonces un sistema distribuido sería lo apropiado Si la comunicación aumenta, la penalización de el delay en la red podría afectar el rendimiento. Entonces, mejor usar sistemas multiprocesadores Se requeriría algunas modificaciones al scheduler
 independiente de los otros. Ejemplo: sistemas multiusuarios de tiempo compatido. El scheduler no se ve afectado. Gruesa o muy gruesa. Existe algún tipo sincronización entre los procesos. Ejemplo: procesos concurrentes. Si los procesos se comunican muy poco, entonces un sistema distribuido sería lo apropiado. Si la comunicación aumenta, la penalización de el delay en la red podría afectar el rendimiento. Entonces, mejor usar sistemas multiprocesadores. Se requeriría algunas modificaciones al scheduler.")
5
Granularidad de la sincronización
Media Ej: múltiples hebras de un proceso Ya que las hebras interactúan muy frecuentemente, las decisiones de scheduling sobre una hebra afectará el rendimiento de la aplicación Modificaciones importantes al scheduler Fina Aplicaciones altamente paralelas

6
Consideraciones de diseño de scheduling
Asignación de procesos a los procesadores Uso de multiprogramación en cada procesador Dispatching de los procesos

7
Asignación de procesos a procesadores
Si la arquitectura es homogénea, los procesadores se pueden ver como recursos que se asignan en demanda Asignación estática Asignar permanentmente un procesador a un proceso Conocido como scheduling de grupo o gang scheduling Cada procesador tiene su propia cola de listo y su propio algoritmo de scheduling Simple, bajo overhead Puede producir que un procesador esté inutilizado mientras otro está sobrecargado Asignación dinámica Los procesadores comparten una cola común de procesos Los procesos pueden ejecutarse en cualquier procesador En un sistema altamente acoplado el contexto de los procesos están disponibles a todos los procesadores en la memoria compartida En granularidad media las hebras de un mismo proceso también se mueven de un procesador a otro

8
Asignación de procesos a procesadores
¿Quién realiza la asignación? Cola global Cualquier procesador puede realizar scheduling Arquitectura Maestro/Esclavo(s) Algunas funciones privilegiadas del kernel siempre corren en el maestro Sólo el procesador maestro realiza funciones privilegiadas de scheduling Los esclavos envían requerimientos al maestro, por ejemplo de I/O Si el maestro falla, todo el sistema falla El maestro puede convertirse en un cuello de botella Arquitectura de pares El SO puede ejecutarse en cualquiera de los procesadores Cada procesador realiza su propio scheduling El SO se torna complejo, por ejemplo hay que garantizar que dos o más CPUs no elijan al mismo proceso
 Algunas funciones privilegiadas del kernel siempre corren en el maestro. Sólo el procesador maestro realiza funciones privilegiadas de scheduling. Los esclavos envían requerimientos al maestro, por ejemplo de I/O. Si el maestro falla, todo el sistema falla. El maestro puede convertirse en un cuello de botella. Arquitectura de pares. El SO puede ejecutarse en cualquiera de los procesadores. Cada procesador realiza su propio scheduling. El SO se torna complejo, por ejemplo hay que garantizar que dos o más CPUs no elijan al mismo proceso.")
9
Scheduling de Procesos
En la mayoría de los sistemas existe una sola cola de procesos, y los procesos pueden ejecutarse en cualquier procesador Si hay prioridades, se mantienen varias colas de prioridades, también globales a los procesadores

10
Scheduling de hebras Compartición de carga Gang o Grupo
Los procesos no son asignados a un procesador en particular Los procesadores comparten un cola global de hebras Gang o Grupo Un conjunto de hebras relacionadas son planificadas para correr en un conjunto de procesadores al mismo tiempo (uno-a-uno) Asignación dedicada Cada proceso es asignado un número de procesadores igual al número de hebras. Las cuales corren siempre en ese conjunto de procesadores hasta el fin del programa Dinámico El número de hebras puede cambiar durante la ejecución del programa
 Asignación dedicada. Cada proceso es asignado un número de procesadores igual al número de hebras. Las cuales corren siempre en ese conjunto de procesadores hasta el fin del programa. Dinámico. El número de hebras puede cambiar durante la ejecución del programa.")
11
Compartición de carga La carga se distribuye parejamente (en demanda) en los procesadores No se necesita un scheduler centralizado. Cuando un procesador queda disponible, ejecuta el código de scheduler y selecciona una de las hebras de la cola global Se puede tener cualquier algoritmo de scheduling tradicional en la cola global FCFS: cuando un job llega, sus hebras son puestas al final de la cola de listos La hebra corre hasta que termina o se bloquea Prioridad: número menor de hebras primero La cola se ordena por el número de hebras que tenga un proceso Apropiativo Prioridad: número restante menor de hebras primero Si llega un proceso con un número menor de hebras que la del procso que está corriendo, se saca de la CPU

12
Desventajas de compartición de carga
Se necesita implementar exclusión mútua para la cola global Luego si varios procesador buscan planificar al mismo tiempo, puede producirse demoras Es muy probable que hebras desapropiadas no vuelvan a correr en el mismo procesador, luego memoria cache es menos eficiente Si un proceso requiere alta coordinación entre sus hebras, es probable que ellas no entren al mismo tiempo, afectando el rendimiento

13
Scheduling Gang o de grupo
La hebras de un mismo proceso (o varios procesos) son planificadas simultáneamente Útil para aplicaciones donde el rendimiento se degrada cuando cualquier parte de la aplicación no está corriendo Por ejemplo, cuando la hebras deben sincronizarse continuamente Suponga que tenemos N procesadores y M procesos cada uno con N o menos hebras. Entonces, una posibilidad es asignar a cada aplicación los N procesos durante 1/M del tiempo total. La otra posibilidad es asignar un tiempo proporcional al número de hebras
 son planificadas simultáneamente. Útil para aplicaciones donde el rendimiento se degrada cuando cualquier parte de la aplicación no está corriendo. Por ejemplo, cuando la hebras deben sincronizarse continuamente. Suponga que tenemos N procesadores y M procesos cada uno con N o menos hebras. Entonces, una posibilidad es asignar a cada aplicación los N procesos durante 1/M del tiempo total. La otra posibilidad es asignar un tiempo proporcional al número de hebras.")
14
Scheduling dedicado Se dedica un grupo de procesadores a una aplicación por todo el tiempo que dure Cada hebra queda asignada a un procesador particular Algunos de los procesadores pueden quedar ociosos cuando por ejemplo la hebra que corre ahí se bloquea por algún motivo no existe multiprogramación de procesadores Útil en multiprocesadores masivos o aplicaciones de uso intensivo de CPU

15
16 procesadores

16
Scheduling dinámico Número de hebras en un proceso cambia durante la vida del proceso Un posible método es dejar que tanto el SO como la aplicación tomen desiciones de scheduling El SO se preocupa de la asignación de los procesadores y la aplicación se preocupa del scheduling de sus hebras en los procesadores asignados El SO ajusta la carga para mejorar la utilización Asigna procesos a procesadores ociosos Si no hay procesadores ociosos, asigna un procesador que está siendo usado por un proceso que actualmente corre en más de un procesador Si no, el requerimiento se bloquea hasta que un procesador esté disponible

17
Real-Time Systems Correctness of the system depends not only on the logical result of the computation but also on the time at which the results are produced Tasks or processes attempt to control or react to events that take place in the outside world These events occur in “real time” and tasks must be able to keep up with them

18
Real-Time Systems Control of laboratory experiments
Process control in industrial plants Robotics Air traffic control Telecommunications Military command and control systems

19
Characteristics of Real-Time Operating Systems
Deterministic Operations are performed at fixed, predetermined times or within predetermined time intervals Concerned with how long the operating system delays before acknowledging an interrupt and there is sufficient capacity to handle all the requests within the required time

20
Characteristics of Real-Time Operating Systems
Responsiveness How long, after acknowledgment, it takes the operating system to service the interrupt Includes amount of time to begin execution of the interrupt Includes the amount of time to perform the interrupt Effect of interrupt nesting

21
Characteristics of Real-Time Operating Systems
User control User specifies priority Specify paging What processes must always reside in main memory Disks algorithms to use Rights of processes

22
Characteristics of Real-Time Operating Systems
Reliability Degradation of performance may have catastrophic consequences Fail-soft operation Ability of a system to fail in such a way as to preserve as much capability and data as possible Stability

23
Features of Real-Time Operating Systems
Fast process or thread switch Small size Ability to respond to external interrupts quickly Multitasking with interprocess communication tools such as semaphores, signals, and events

24
Features of Real-Time Operating Systems
Use of special sequential files that can accumulate data at a fast rate Preemptive scheduling base on priority Minimization of intervals during which interrupts are disabled Delay tasks for fixed amount of time Special alarms and timeouts

25
Scheduling of a Real-Time Process

26
Scheduling of a Real-Time Process

27
Real-Time Scheduling Static table-driven
Determines at run time when a task begins execution Static priority-driven preemptive Traditional priority-driven scheduler is used Dynamic planning-based Feasibility determined at run time Dynamic best effort No feasibility analysis is performed

28
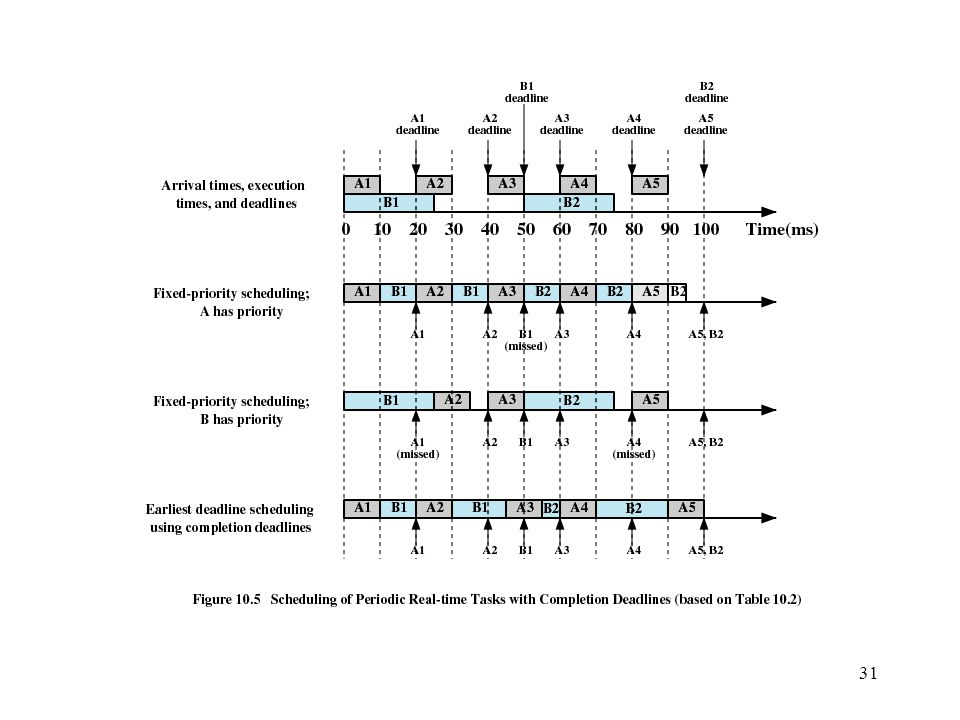
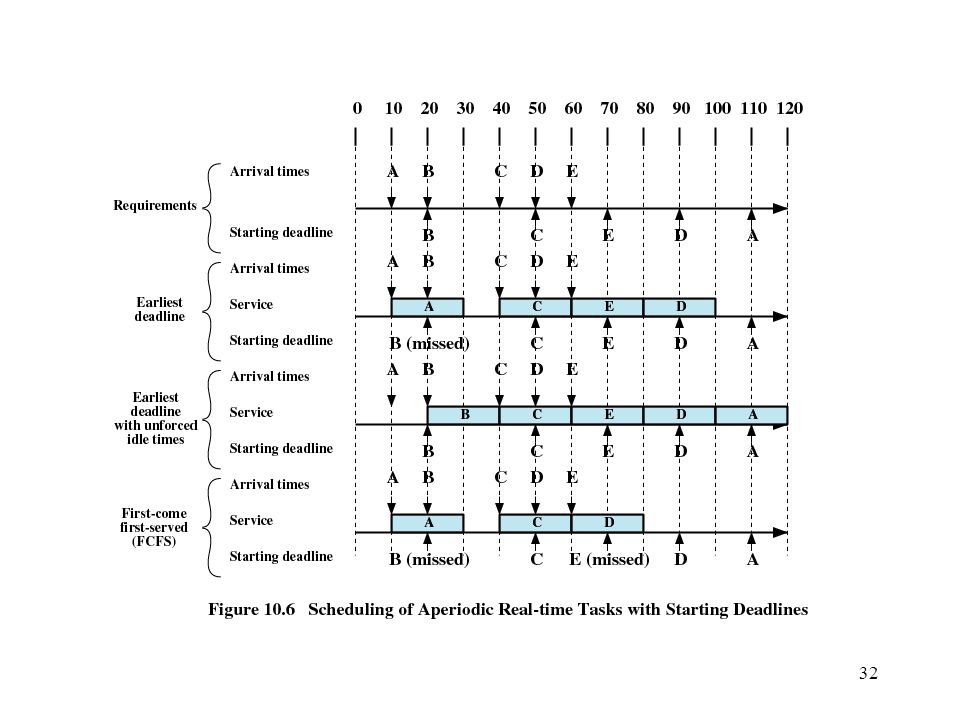
Deadline Scheduling Real-time applications are not concerned with speed but with completing tasks

29
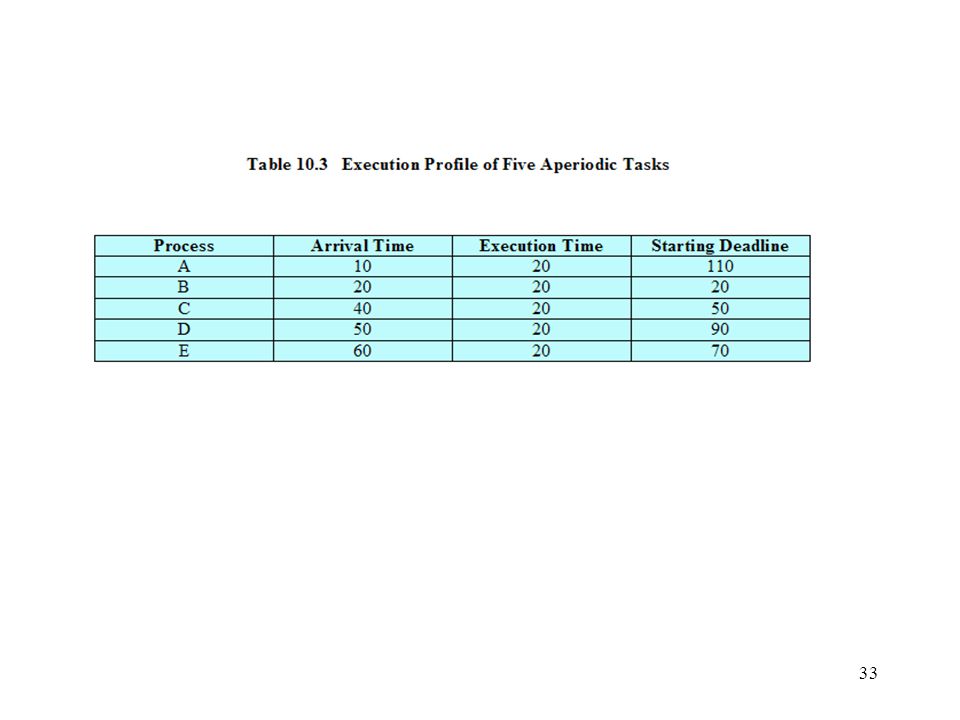
Deadline Scheduling Information used Ready time Starting deadline
Completion deadline Processing time Resource requirements Priority Subtask scheduler

30
Two Tasks

34
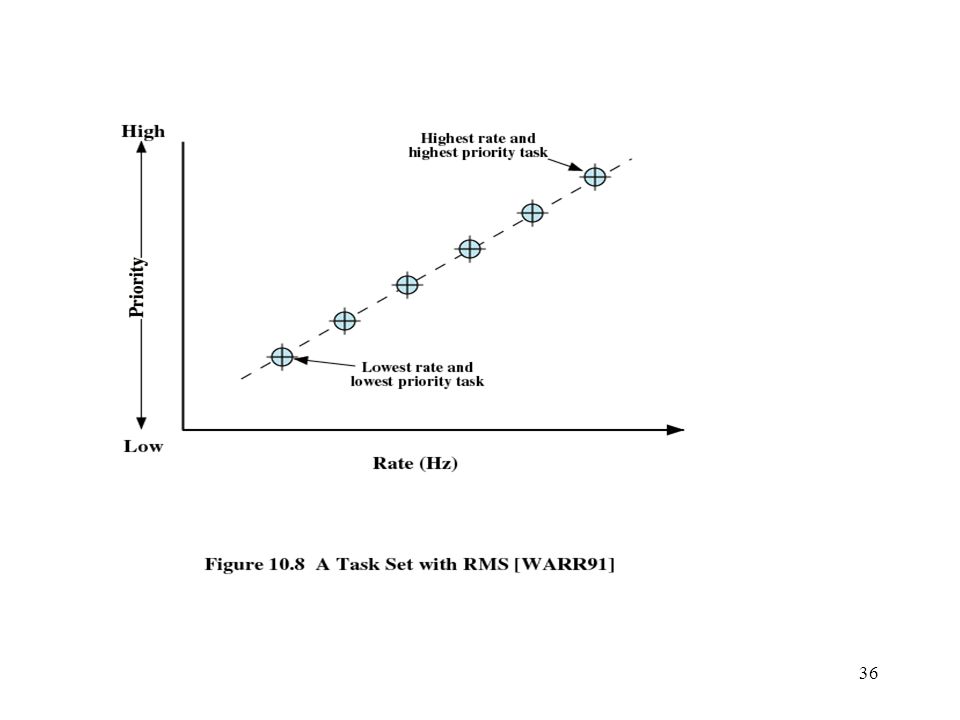
Rate Monotonic Scheduling
Assigns priorities to tasks on the basis of their periods Highest-priority task is the one with the shortest period

35
Periodic Task Timing Diagram

37
Priority Inversion Can occur in any priority-based preemptive scheduling scheme Occurs when circumstances within the system force a higher priority task to wait for a lower priority task

38
Unbounded Priority Inversion
Duration of a priority inversion depends on unpredictable actions of other unrelated tasks

39
Priority Inheritance Lower-priority task inherits the priority of any higher priority task pending on a resource they share

40
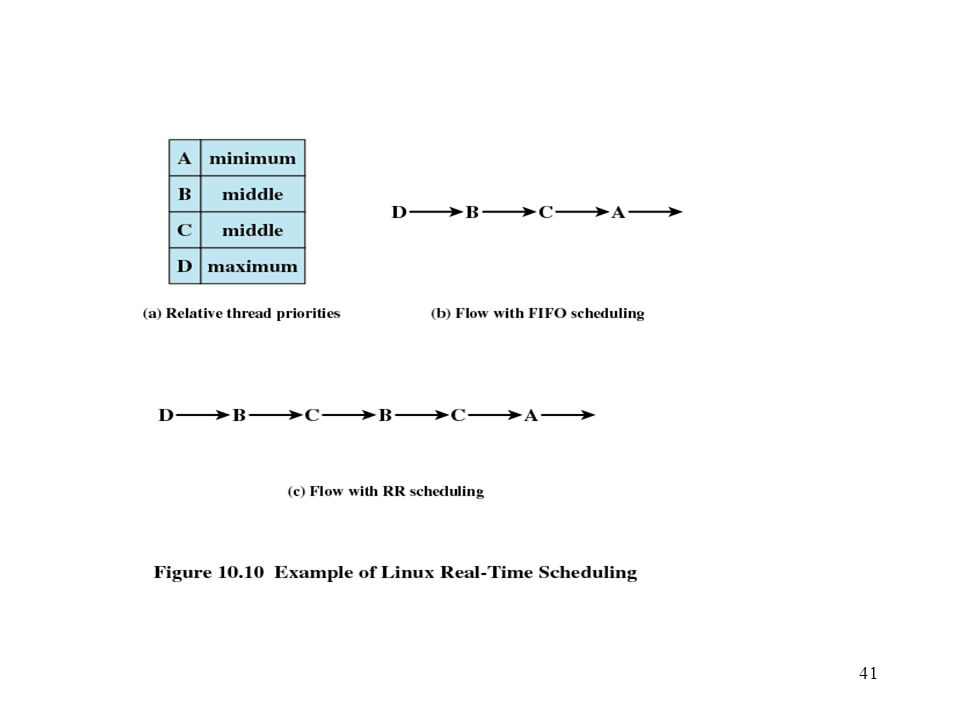
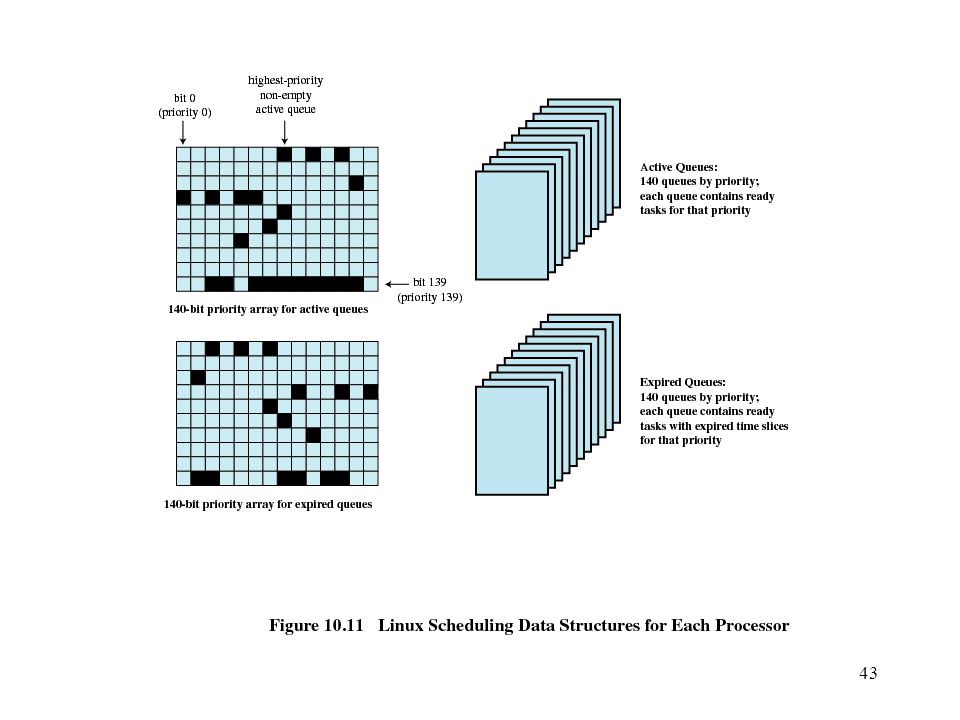
Linux Scheduling Scheduling classes
SCHED_FIFO: First-in-first-out real-time threads SCHED_RR: Round-robin real-time threads SCHED_OTHER: Other, non-real-time threads Within each class multiple priorities may be used

42
Non-Real-Time Scheduling
Linux 2.6 uses a new scheduler the O(1) scheduler Time to select the appropriate process and assign it to a processor is constant Regardless of the load on the system or number of processors
 scheduler. Time to select the appropriate process and assign it to a processor is constant. Regardless of the load on the system or number of processors.")
44
UNIX SVR4 Scheduling Highest preference to real-time processes
Next-highest to kernel-mode processes Lowest preference to other user-mode processes

45
UNIX SVR4 Scheduling Preemptable static priority scheduler
Introduction of a set of 160 priority levels divided into three priority classes Insertion of preemption points

46
SVR4 Priority Classes

47
SVR4 Priority Classes Real time (159 – 100) Kernel (99 – 60)
Guaranteed to be selected to run before any kernel or time-sharing process Can preempt kernel and user processes Kernel (99 – 60) Guaranteed to be selected to run before any time-sharing process Time-shared (59-0) Lowest-priority
 Guaranteed to be selected to run before any time-sharing process. Time-shared (59-0) Lowest-priority.")
48
SVR4 Dispatch Queues

49
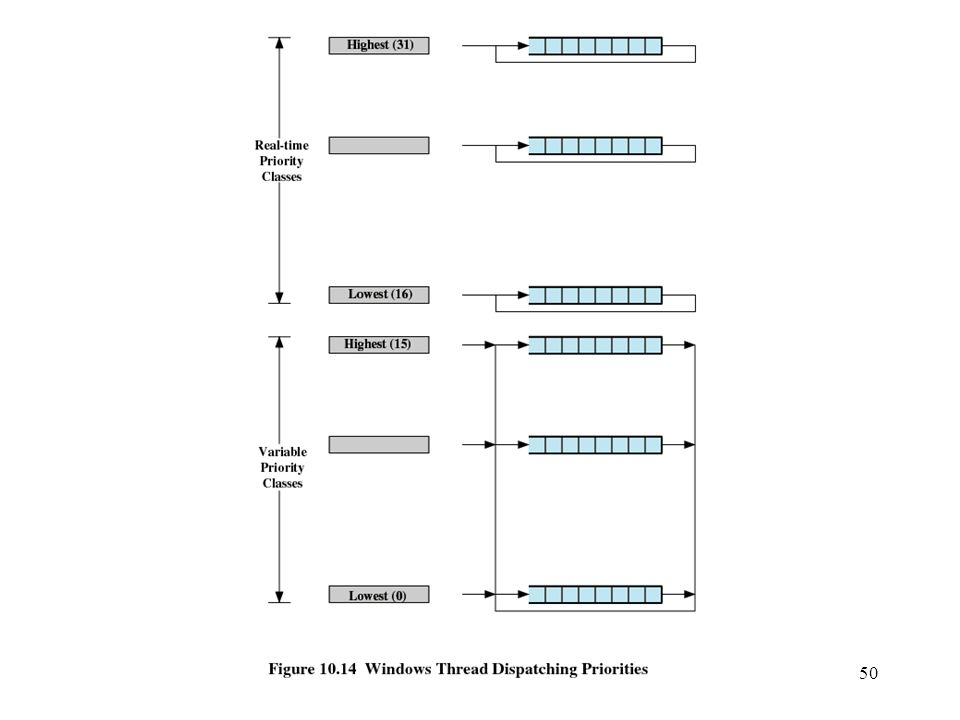
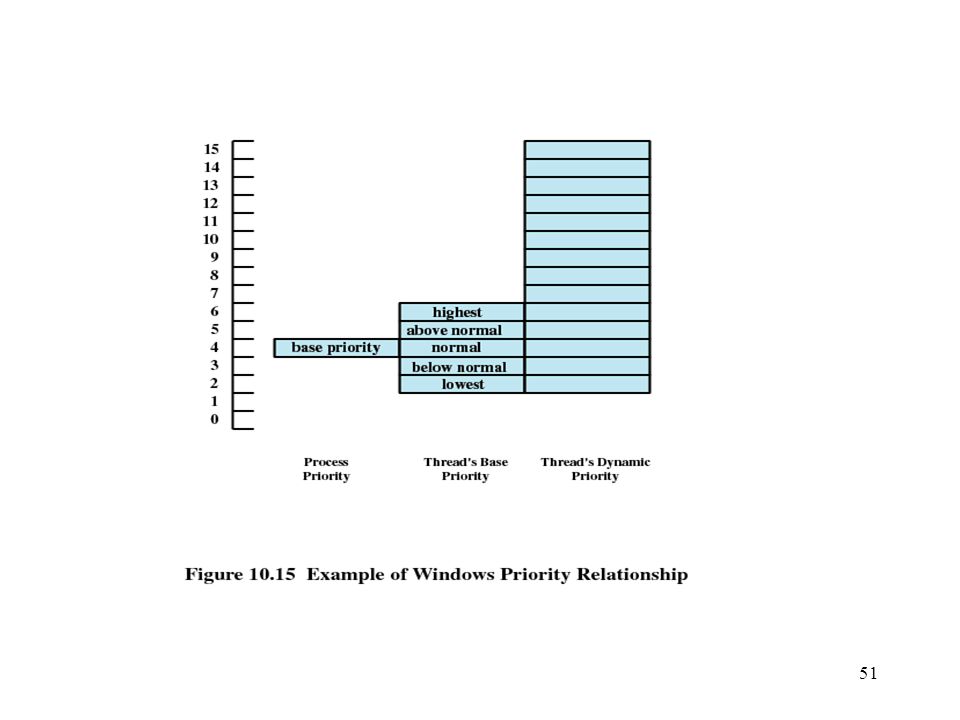
Windows Scheduling Priorities organized into two bands or classes
Real time Variable Priority-driven preemptive scheduler

Presentaciones similares









 Noviembre de 2004.>")









