Descargar la presentación
La descarga está en progreso. Por favor, espere

1
La Química Computacional y el Diseño de Fármacos

2
Perspectiva Principios del descubrimiento de fármacos
Descubrimiento de fármacos guiado por computadora Descubrimiento de fármacos guiado por datos Técnicas modernas para la identificación y selección de la diana Técnicas modernas de identificación de pistas

3
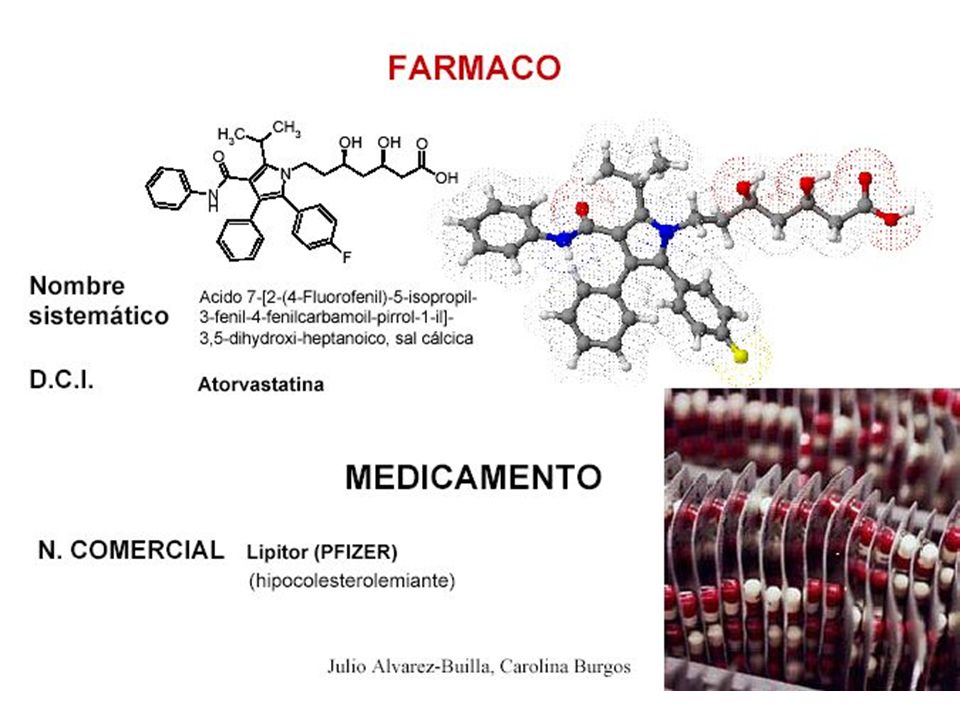
¿Que es un fármaco? Se entiende por fármaco, cualquier sustancia biológicamente activa, capaz de modificar el metabolismo de las células sobre las que hace efecto Composición definida con un efecto farmacológico ¿Cuál es el proceso del Desarrollo y Descubrimiento de Fármacos?

6
Una pequeña historia del diseño de fármacos ayudados por computadora
1960’s – Interacción del fármaco – revisión del objetivo 1980’s- Automatización – cribado de alto rendimiento 1980’s- Bases de datos (tecnología de la información) bibliotecas combinatorias 1980’s- Computadoras Rápidas - acoplamiento 1990’s- Computadoras Super Rápidas - ensamblado del genoma – selección de objetivos basados en el genoma 2000’s- Manejo de una enorme información – fármacogenomica
 bibliotecas combinatorias. 1980’s- Computadoras Rápidas - acoplamiento. 1990’s- Computadoras Super Rápidas - ensamblado del genoma – selección de objetivos basados en el. genoma. 2000’s- Manejo de una enorme información – fármacogenomica.")
7
Molécula Diana Estructura 3D Línea de células recombinantes
Expresión genética - Fermentación Purificación de la Proteína Cristalización Rayos-X - Sincrotón Estructura 3D

8
Estructura 3D NBE NCE NCE (New Chemical Entity)
Diseño Racional Mapeo de Epítopes Ingeniería de Proteínas NBE Biblioteca de Moléculas Pequeñas NCE NCE (New Chemical Entity) NBE (New Biological Entity)
 NBE (New Biological Entity)")
10
Fármacos: Proceso de Descubrimiento
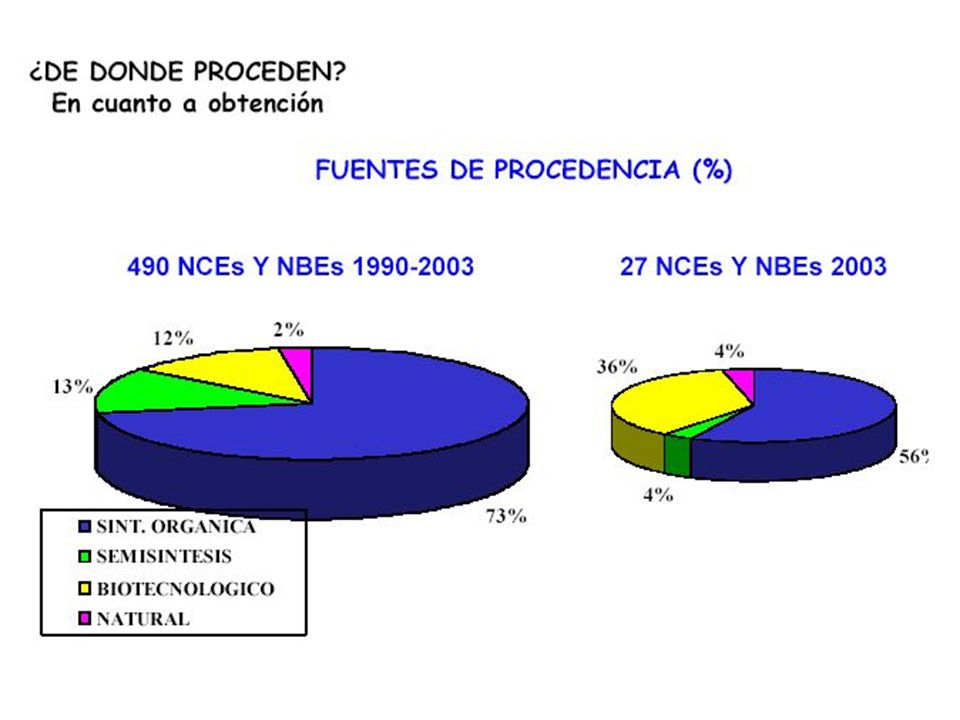
Moléculas Pequeñas Productos Naturales Caldos de fermentación Extractos de Plantas Fluidos Animales (e.g., veneno de víbora) Productos Químicos Medicinales Sintéticos Derivados para la Química Medicinal Derivados de la Química Combinatoria Biológicos Productos Naturales (aislamiento) Productos Recombinantes Productos Quiméricos
 Productos Químicos Medicinales Sintéticos. Derivados para la Química Medicinal. Derivados de la Química Combinatoria. Biológicos. Productos Naturales (aislamiento) Productos Recombinantes. Productos Quiméricos.")
11
Descubrimiento vs. Desarrollo
El Descubrimiento incluye: su concepto, su mecanismo, ensayo, cribado, identificación de la pista, demostración de la pista, optimización de la pista El Descubrimiento también incluye pruebas in vivo en animales y demostración concomitante del índice terapéutico El Desarrollo comienza cuando se toma la decisión de poner a una molécula en la fase I de las pruebas clínicas

12
Descubrimiento vs. Desarrollo
El tiempo desde su concepción hasta la aprobación de un nuevo fármaco es típicamente de años La vasta mayoría de las moléculas son desechadas en el camino El costo estimado de llevar al mercado un fármaco es aproximadamente $800 millones de dólares hoy en día!!

13
Descubrimiento vs. Desarrollo
Identificar la enfermedad Encontrar un fármaco efectivo contra la proteína (2-5 años) Aislar la proteína involucrada en la enfermedad (2-5 años) Escalamiento Pruebas clínicas en humanos (2-10 años) Pruebas preclínicas (1-3 años) File IND File NDA Formulación Aprobación de la FDA (2-3 años)
 Aislar la proteína involucrada en la enfermedad (2-5 años) Escalamiento. Pruebas clínicas en humanos. (2-10 años) Pruebas preclínicas. (1-3 años) File IND. File NDA. Formulación. Aprobación de la FDA. (2-3 años)")
14
La tecnología impacta este proceso
GENOMICA, PROTEOMICA & BIOFARM. Potencialmente produce muchas más dianas, personalizadas o no CRIBADO DE ALTO RENDIMIENTO Identificar la enfermedad Cribado de hasta 100,000 compuestos por día para probar su actividad contra la proteína CRIBADO VIRTUAL Usar una computadora para predecir la actividad Aislar la proteína QUIMICA COMBINATORIA Producir rápidamente un vasto número de compuestos Encontrar el fármaco MODELADO MOLECULAR Las graficas y modelos por computadora ayudan a mejorar la actividad Pruebas preclínicas MODELOS ADME IN VITRO & IN SILICO Modelos computarizados y de tejidos comienzan a reemplazad las pruebas en animales

15
Genómica, Proteómica & Biofarmacéuticos
Comprendiendo la liga entre enfermedades, el montaje genético y la expresión de las proteínas

16
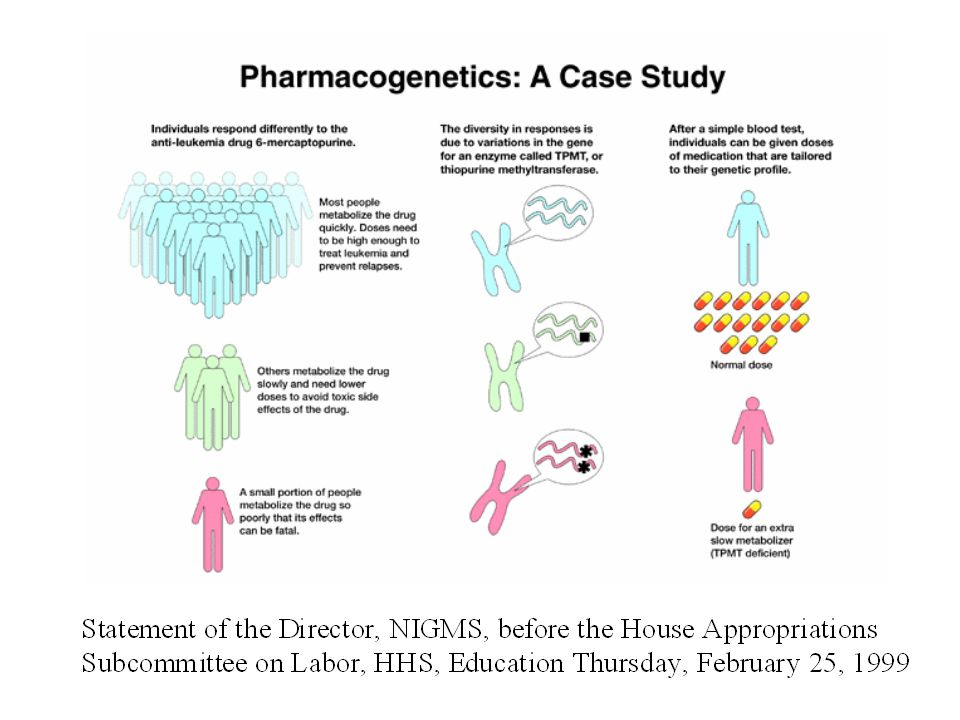
Genómica La genómica está acelerando nuestra compresión de cómo están relacionados el ADN, los genes, las proteínas y su función, tanto en condiciones normales y de enfermedad El proyecto del Genoma Humano ha mapeado los genes del ADN en humanos Se espera que este conocimiento provea de muchas más proteínas potenciales Permite la posible “personalización” de las terapias ATACGGAT TATGCCTA funciones

17
e.g. obeso, cáncer, caucásico Compuestos administrados
Chips Genéticos Los “chips genéticos” nos permiten buscar por cambios en la expresión de una proteína en diferentes individuos en una variedad de condiciones, y ver si la presencia de fármacos cambia esa expresión Hace posible el diseño de fármacos para diferentes fenotipos gente / condiciones e.g. obeso, cáncer, caucásico Compuestos administrados Perfil de expresión (cribado de 35,000 genes)
")
18
Microarreglos Genes “impresos” en vidrio
Una variedad de genomas humanos y animales Medirán cuanto de cada fragmento de ADN está presente en una muestra desconocida Un chip de genoma humano contiene 14,500 genes humanos bien caracterizados $300-$500 por chip

19
Producción del GeneChip

20
Uso del GeneChip

21
Biofarmaceúticos Fármacos basados en proteínas, péptidos o productos naturales en lugar de moléculas pequeñas (química) Promovidos por las compañías biotecnológicas Los biofarmaceúticos se pueden descubrir más rápidamente que las terapias normales de moléculas pequeñas Las biotecnológicas se están empatando con las compañías farmacéuticas más importantes

22
Cribado de alto rendimiento
El cribado de compuestos en ambiente corporativo quizá sea de millones para ver si alguno muestra actividad contra la proteína causante de la enfermedad

23
Cribado de alto rendimiento
Las compañías farmacéuticas tienen ahora millones de nuestras de compuestos químicos El cribado de alto rendimiento puede probar 100,000 compuestos por día Puede ser que solo algunos miles de estos compuestos lleguen a mostrar alguna actividad contra la proteína El químico medicinal necesita escoger inteligentemente las 2 o 3 clases de compuestos que muestren la promesa de ser fármacos que puedan seguir desarrollándose

24
Implicaciones Informáticas
Tener la capacidad de almacenar la estructura química y los datos biológicos para millones de puntos Representación computacional de la estructura 2D Tener la capacidad de organizar miles de compuestos activos en grupos de relevancia Agrupar estructuras similares y relacionarlas a la actividad Capacidad de aprender tanta información como sea posible a partir de los datos (minería de datos) Aplicar métodos estadísticos a las estructuras y correlacionar la información
 Aplicar métodos estadísticos a las estructuras y correlacionar la información.")
25
Herramientas para la minería de datos

26
Cribado Virtual Construir un modelo computacional de la actividad para una diana en particular Usar un modelo para valorar los compuestos de bibliotecas “virtuales” o reales Usar esta valoración para decidir cual hacer, o pasar a través de un cribado real

27
Modelos computacionales de la actividad
Métodos de Aprendizaje E.g. Redes Neuronales, Redes de Bayes, Redes de Kahonen Se entrenan con compuestos de actividad conocida Predicen la actividad de compuestos “desconocidos” Métodos de Valoración Compuestos con perfil basado en propiedades relativas a la diana Acoplamiento Rápido Rápidamente “acoplar” representaciones 3D de moléculas en representaciones 3D de proteínas, y valorar de acuerdo en que tan bien se acoplan

28
Química Combinatoria Al combinar “bloques de construcción” molecular, podemos crear un gran número de moléculas diferentes muy rápidamente Usualmente involucra a una molécula “plataforma”, y grupos de compuestos que han reaccionado con la plataforma para colocar diferentes estructuras en “puntos de unión”

29
Ejemplo de Biblioteca Combinatoria
Plataforma grupos-“R” Ejemplos R1 = OH OCH3 NH2 Cl COOH R2 = fenilo OH Br F CN R3 = CF3 NO2 fenoxy OH NH R1 NH CF3 O OH OH C OH NH NH R2 OH CF3 R3 O CH3 O OH Para esta pequeña biblioteca el número de posibles compuestos es de 5 x 6 x 5 = 150 C NH OH O

30
Puntos de Química Combinatoria
Cuales grupos-R escoger Cuales bibliotecas hacer ¿“Llenar” la colección existente de compuestos? ¿Orientadas a un proteína en particular? ¿Tantos compuestos como se posible? El perfil computacional de las bibliotecas puede ayudar “Bibliotecas virtuales ” pueden ser evaluadas en la computadora

31
Búsqueda de Estructuras
2D búsquedas de subestructuras 3D búsquedas de subestructuras 3D búsquedas conformacionalmente flexibles

32
2D Búsqueda de Subestructuras
Grupos funcionales conectividad Aromático substituido con halógenos y un grupo carboxilo

33
2D Búsqueda de Subestructuras
Buscar: Aromático substituido con halógenos y un grupo carboxilo

34
2D Búsqueda de Subestructuras

35
2D Búsqueda de Similitud

36
3D Búsqueda de Subestructuras
Relaciones espaciales Define intervalos para distancias y ángulos Conformación almacenada generalmente la de más baja energía

37
3D Búsqueda de Subestructuras

38
Búsquedas Conformaciónalmente Flexibles
Rotar alrededor de uniones que giran libremente Muchas conformaciones Multa por baja energía Obtener muchos más aciertos Los huéspedes se adaptan al anfitrión y el anfitrión se adapta a los huéspedes

39
Búsquedas Conformaciónalmente Flexibles
Pequeña multa energética

40
Modelos ADME in vitro & in silico
Tradicionalmente, animales son usados para las pruebas pre-humanas. Sin embargo, esta pruebas resultan caras, consumen tiempo y son éticamente indeseables Las técnicas ADME (Absorbtion, Distribution, Metabolism, Excretion) pueden ayudar a modelar como el fármaco interactuará con el cuerpo Estos métodos pueden ser experimentales (in vitro) usando cultivo de tejidos, o in silico, usando modelos computacionales
 pueden ayudar a modelar como el fármaco interactuará con el cuerpo. Estos métodos pueden ser experimentales (in vitro) usando cultivo de tejidos, o in silico, usando modelos computacionales.")
41
Modelos ADME in silico Los métodos computacionales pueden predecir propiedades importantes del compuesto para ADME, e.g. LogP, una medida de lipofilicidad Solubilidad Permeabilidad Metabolismo del Citocromo p450 Estimados promedio se pueden hacer para millones de compuestos, reduciendo el “desgaste” – el coeficiente de fallas de los compuestos en la última fase

42
Calculo de propiedades en la Red
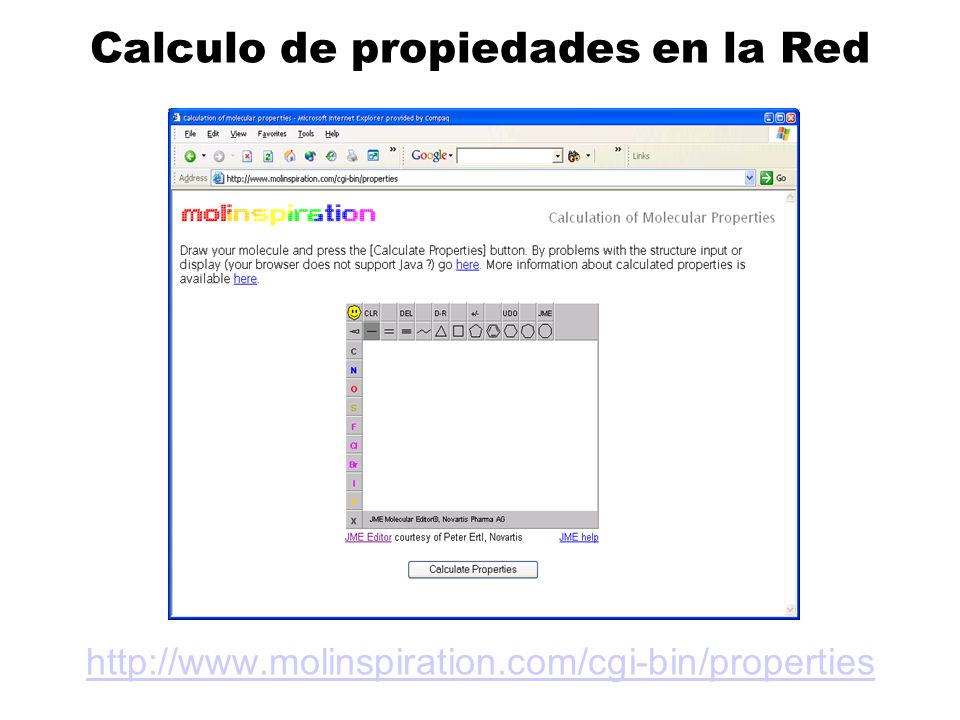
43
Dibujar una estructura …

44
Regreso de los resultados …
LogP Área de Superficie Total Polar # de átomos Peso Mol. Regla-de-5 violaciones # uniones Rot. Potencial farmacológico (N/D)
")
45
Disciplinas en el Descubrimiento de Fármacos
Medicina Fisiología/patología Farmacología Biología molecular/celular Automatización/robótica Química medicinal, analítica, y química combinatoria Química estructural y computacional Bioinformática

47
Bioinformática - una Revolución
Experimento Biológico Datos Información Conocimiento Descubrimiento Coleccionar Caracterizar Comparar Modelar Inferir Complejidad Tecnología Data Alto -orden 1 1000 100000 Poder de Cómputo Organos Mapeo del Cerebro Modelo Cardiaco Celular Modelo pasos metabólicos de E.coli Sub-celular 106 102 Modelo Neuronal 1 # Gente/Sitio Red Ensamblado Estructura viral Ribosoma Circuitos Genéticos Estructura 1 Genoma Pequeño/Mes Proyecto Genoma Humano Genoma Levadura Genoma E.Coli Genoma C.Elegans Genoma Humano Completo Tecnología de secuenciación ESTs Gene Chips Secuencia 90 95 00 05 Year (C) Copyright Phil Bourne 1998
 Copyright Phil Bourne")
48
Bibliotecas Combinatorias
Miles de variaciones a partir de una plataforma fija Buenas bibliotecas abarcan áreas muy grandes del espacio conformacional y químico - diversidad molecular Diversidad en – interacciones estéricas, electrostáticas, e hidrofóbicas... Deseo de ser tan amplias como los compuestos del índice “Merck” de cribado azaroso El diseño de bibliotecas de diseño ayudadas por computadora aún está en su infancia

49
Modelado Molecular Visualización 3D de las interacciones entre los compuestos y las proteínas “Acoplamiento” computacional de los compuestos con las proteínas

50
Visualización 3D La cristalografía de rayos-X y la espectroscopia de RMN pueden revelar la estructura 3D de las proteínas y compuestos que se les unen. La visualización de estos “complejos” de proteínas y potenciales fármacos pueden ayudar a los científicos a comprender el mecanismo de acción del fármaco y para mejorar el diseño de un fármaco. La visualización usa modelos de “bolas y palitos” para los átomos y sus uniones, así como para desplegar sus superficies. La visualización Estereoscópica está disponible.

51
Software de Acoplamiento Disponible
DOCK (Kuntz et al, 1982, Ewing & Kuntz 2001) AutoDock (Olson et al 1990, Morris et al 1998) ICM (Abagyan et al 1994) FlexX (Rarey et al 1996) Hammerhead (Welch et al 1996) GOLD (Jones et al 1997) MCDock (Liu & Wang 1999) SLIDE (Kuhn et al 2002) FRED (McGann et al 2002) Surflex (Jain 2003) GemDock (Yang & Chen 2004) Glide (Friesner et al 2004) Yucca (Choi 2005) …
 AutoDock (Olson et al 1990, Morris et al 1998) ICM (Abagyan et al 1994) FlexX (Rarey et al 1996) Hammerhead (Welch et al 1996) GOLD (Jones et al 1997) MCDock (Liu & Wang 1999) SLIDE (Kuhn et al 2002) FRED (McGann et al 2002) Surflex (Jain 2003) GemDock (Yang & Chen 2004) Glide (Friesner et al 2004) Yucca (Choi 2005) …")
52
Algoritmos de Acoplamiento
Búsqueda Estocástica: Algoritmo Genético, Monte Carlo recocido simulado AutoDock, MCDock, ICM, GOLD, Glide Construcción Incremental : Fragmentos rígidos con uniones rotables Incremental : ángulos de torsión preferidos DOCK, FlexX, SLIDE, Surflex Multiconformero: Genera un conjunto de conformeros de baja-energía Acoplamiento Rígido FLOG, FRED, Yucca

53
Acoplamiento con un Algoritmo Genético
Colocar a un compuesto en el área aproximada donde el acoplamiento ocurre El algoritmo genético codifica la orientación del compuesto y sus uniones de torsión Optimizar la unión con la proteína Minimizar la energía Puentes de hidrógeno Interacciones hidrofóbicas Puede se empleado para el “cribado virtual”

54
Visualización de Demos en Acoplamiento Molecular
Acoplamiento Proteína-Proteína Acoplamiento Proteína-Ligando

55
Moléculas en Movimiento
Instalar JMOL (jmol.org), Java 4 WinXP, ActiveControlX y J2SE v5.0 runtime
, Java 4 WinXP, ActiveControlX y J2SE v5.0 runtime.")
56
Referencias Cohen N. Guidebook on Molecular Modeling in Drug Design, Academic Press (1996) Cramer C.J. Essentials of Computational Chemistry: Theories and Models, John Wiley & Sons (2002) Schlick T. (Ed) Molecular Modeling and Simulation, Springer Verlag (2002) Leach A.R. (Ed) Molecular Modeling: Principles and Applications, Prentice Hall (2001) van de Waterbeemd H., Testa B. (Eds) Computer-Assisted Lead Finding and Optimization: Current Tools for Medicinal Chemistry, John Wiley & Sons (1997)
 Schlick T. (Ed) Molecular Modeling and Simulation, Springer Verlag (2002) Leach A.R. (Ed) Molecular Modeling: Principles and Applications, Prentice Hall (2001) van de Waterbeemd H., Testa B. (Eds) Computer-Assisted Lead Finding and Optimization: Current Tools for Medicinal Chemistry, John Wiley & Sons (1997)")
Presentaciones similares















>")




