Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Procesadores Superescalares

2
Los procesadores superescalares se caracterizan por emplear varias unidades de ejecución segmentadas que trabajan de forma paralela EU1 EU2 EU3 instrucciones

3
La ejecución en unidades independientes que trabajan de forma paralela plantea los siguientes problemas: Distribución de instrucciones y Decodificación paralela. Determinación de la unidad de ejecución a la que se envía cada instrucción. Despacho de instrucciones. Mantenimiento de un buffer de instrucciones para cada unidad de ejecución. Es una fase opcional que permite acelerar la distribución. Detección y resolución de dependencias de datos Detección y resolución de dependencias de control : Predicción de salto Preservación de la consistencia secuencial

4
Buffer de Instrucciones
Distribución / Decodificación Ventana de distribución UE UE UE UE

5
UE Buffer de Instrucciones Distribución / Decodificación Ventana de distribución D U Shelvings Se evita el bloqueo por dependencias de datos verdaderas en la fase de distribución ya que, a pesar de existir una dependencia de este tipo, las instrucciones pueden ser distribuidas

6
Las dependencias estructurales en la fase de distribución pueden venir por dos motivos:
Falta de entradas en el buffer de la unidad de despacho correspondiente. Conflicto en la utilización de la ruta de datos

7
El conflicto en la utilización de la ruta de datos
FX UE Buffer de Instrucciones Distribución / Decodificación Ventana de distribución D U FP UE FP Instrucción FX Instrucción Distrib Bloq

8
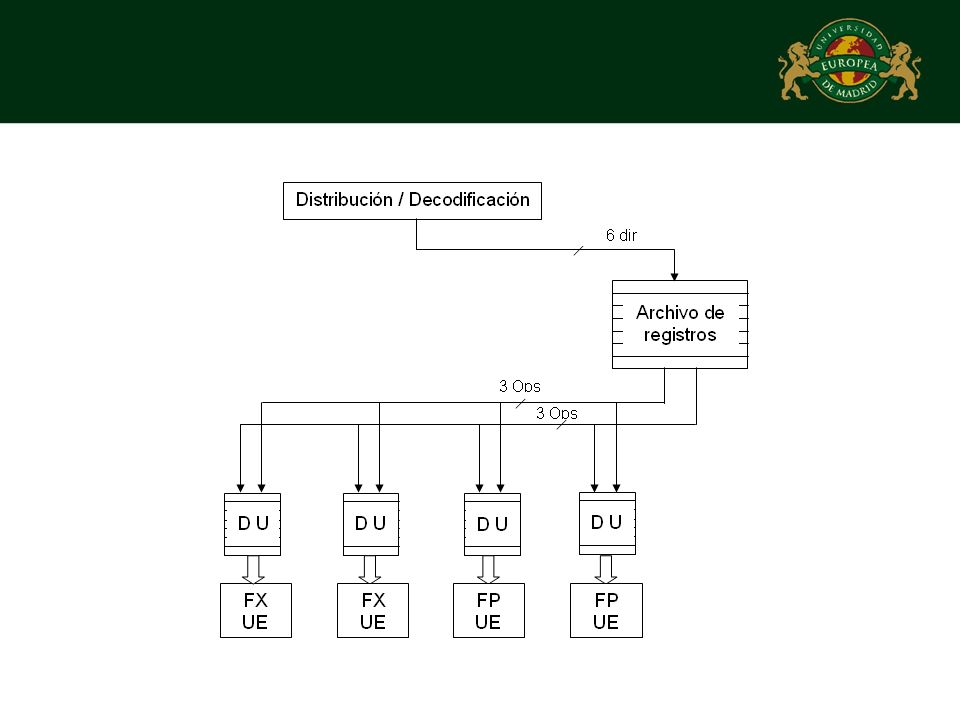
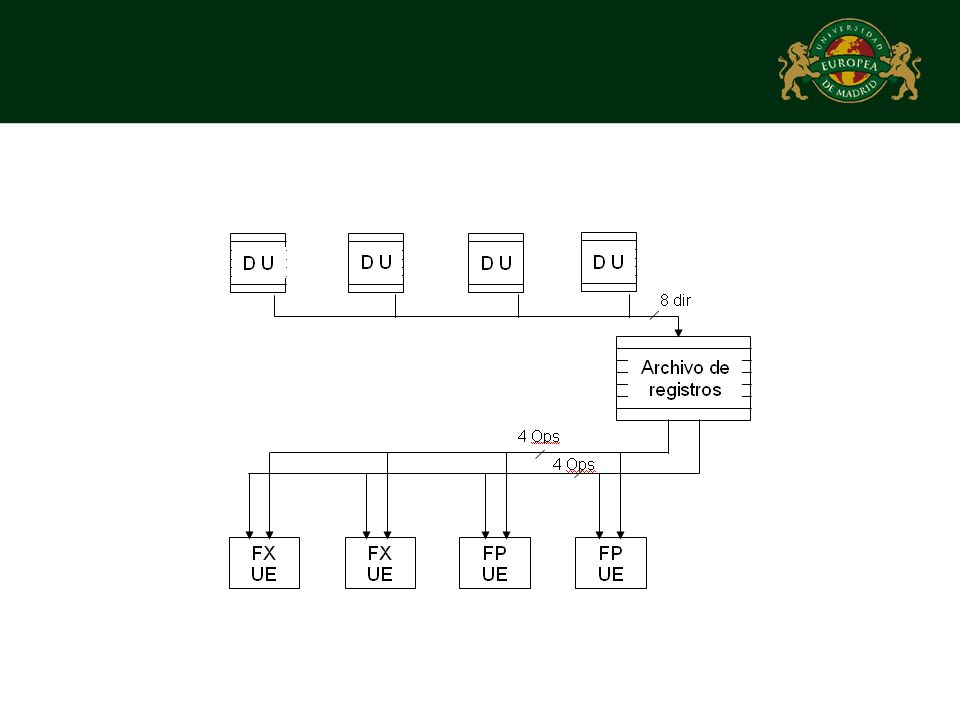
Tipos de Shelvings Una única unidad de despacho central para todas las unidades de ejecución Un número reducido de unidades de despacho compartidas por varias unidades de ejecución Una unidad de despacho individual para cada unidad de ejecución

9
Formato de distribución
Recodificación del campo código de las instrucciones Dirección de los operandos Operandos en sí No tiene en cuenta la posibilidad de que el operando no esté disponible debido a una dependencia de datos verdadera Se debe incluir un bit que indique si el operando está pendiente de la resolución de una dependencia Cuando el operando está pendiente de búsqueda, el espacio destinado a él contiene es ese caso su dirección

12
Operandos en sí La unidad de despacho se encarga de resolver las dependencias de datos existentes La información que se transmite corresponde al identificador del registro que ha sido calculado junto con el valor obtenido de la unidad de ejecución Una búsqueda dentro de la unidad de despacho permite conocer si es necesario actualizar con el valor calculado los campos operandos de las instrucciones contenidas en el buffer Además los resultados deben ser actualizados en los registros utilizados para el “renombramiento” con el fin de que estén disponibles de forma anticipada para las instrucciones pendientes de distribución

13
Búsqueda de operandos durante la distribución
Búsqueda durante la distribución Búsqueda durante el despacho

14
Política de despacho Las instrucciones sólo se pueden despachar si todos sus operandos están disponibles Distribución: chequeo de los bits de operando pendiente Despacho: Información se toma directamente de los registros

15
Detección y resolución de dependencias
Dependencias verdaderas: nada que hacer Dependencias falsas: renombramiento MUL R1, R5, R5 … SUB R1, R2, R6 DIV R1, R3, R4 ADD R1, R2, R3 MUL R6, R1, R4

16
ROB La explotación del paralelismo a nivel de instrucción lleva a "ejecutar" las instrucciones fuera del orden secuencial determinado por el programa lo que se realiza fuera de orden es el calculo de los resultados de las instrucciones mientras que la ejecución real de las instrucciones no es efectiva hasta que los resultados son actualizados, bien en los registros bien en la memoria El ROB (Reorder Buffer) es el elemento de la estructura de los superescalares que permite preservar la consistencia secuencial Para ello mantiene un buffer en el que se almacenan las instrucciones en el orden en el que han sido distribuidas, es decir, en el orden secuencial de ejecución
 es el elemento de la estructura de los superescalares que permite preservar la consistencia secuencial. Para ello mantiene un buffer en el que se almacenan las instrucciones en el orden en el que han sido distribuidas, es decir, en el orden secuencial de ejecución.")
17
ROB Además de una instrucción cada entrada tiene un campo para almacenar el resultado calculado por la misma Mientras la instrucción permanece en el ROB el resultado está pendiente de ser actualizado en los registros o en la memoria El orden en el que se sacan las instrucciones del ROB es el orden secuencial determinado por el programa cargado en memoria. De esa forma los resultados son actualizados en dicho orden

18
Técnicas de Predicción de salto
Las instrucciones de salto suponen un inconveniente para la obtención de un rendimiento alto Cuando se decodifica una instrucción de salto, el procesador bloquea el fetch de instrucciones hasta que el salto no es resuelto (burbuja). La ventana de instrucciones tiene pocas instrucciones Una solución = métodos precisos que predigan la dirección de los saltos condicionales, así como anticipar lo antes posible el cálculo de la dirección destino Se hace un prefetching y se ejecutan instrucciones del camino destino antes de que el salto sea resuelto (ejecución especulativa)
. La ventana de instrucciones tiene pocas instrucciones. Una solución = métodos precisos que predigan la dirección de los saltos condicionales, así como anticipar lo antes posible el cálculo de la dirección destino. Se hace un prefetching y se ejecutan instrucciones del camino destino antes de que el salto sea resuelto (ejecución especulativa)")
19
Técnicas de Predicción de salto
Introducir cuando es tomado Introducir cuando es ejecutado por 1ª vez Tipos: Predicción estática (tiempo de compilación) Predecir todos los saltos como tomados Predicciones basadas en el código de operación Predicciones en función de su dirección (ejemplo hacia atrás predecirlos como tomados y hacia delante como no) Predicción dinámica (tiempo de ejecución) BHT (Branch History Table) Información sobre las últimas ejecuciones de los saltos BTAC (Branch Target Address Cache) Dirección destino de los últimos saltos tomados
 Predecir todos los saltos como tomados. Predicciones basadas en el código de operación. Predicciones en función de su dirección (ejemplo hacia atrás predecirlos como tomados y hacia delante como no) Predicción dinámica (tiempo de ejecución) BHT (Branch History Table) Información sobre las últimas ejecuciones de los saltos. BTAC (Branch Target Address Cache) Dirección destino de los últimos saltos tomados.")
20
Técnicas de Predicción de salto
El Branch Target Buffer (BTB) es una pequeña memoria asociativa que guarda las direcciones de los últimos saltos ejecutados así como su destino. A su vez guarda información que permite predecir si el salto será tomado o no. En la etapa de fetch se mira si la dirección de la instrucción está en el BTB. Si es así se miran los bits de predicción y se decide si el salto ha de ser tomado o no. Si el salto no es tomado o la dirección no está en el BTB en el siguiente ciclo se hace el fetch de la siguiente instrucción en orden. Si el salto es tomado en el siguiente ciclo e hace el fetch del nuevo camino de ejecución.
 es una pequeña memoria asociativa que guarda las direcciones de los últimos saltos ejecutados así como su destino. A su vez guarda información que permite predecir si el salto será tomado o no. En la etapa de fetch se mira si la dirección de la instrucción está en el BTB. Si es así se miran los bits de predicción y se decide si el salto ha de ser tomado o no. Si el salto no es tomado o la dirección no está en el BTB en el siguiente ciclo se hace el fetch de la siguiente instrucción en orden. Si el salto es tomado en el siguiente ciclo e hace el fetch del nuevo camino de ejecución.")
21
Técnicas de Predicción de salto
Fallo en la predicción Se comprueba si la predicción es correcta al ejecutar la instrucción de salto. Si no, el procesador deberá realizar un vaciado del pipe, quitando todas las instrucciones del camino incorrecto pendientes de ser ejecutadas y restaurando el estado de los registros como estaban antes de predecir el salto. Una nueva burbuja Realizará el fetch de las instrucciones del camino correcto

22
Resumen

23
Resumen La fase de emisión juego un papel fundamental
Hay que decidir qué instrucciones se pueden emitir (en función de las unidades funcionales disponibles) Hay que leer muchos registros a la vez Si una se bloquea sería muy caro en cuanto a prestaciones Idem con las penalidades de fallo caché Por tanto, salvo en sistemas empotrados que suelen llevar superescalares menos agresivos, todos poseen emisión dinámica: el procesador decide en tiempo de ejecución qué instrucciones pueden emitirse a la vez y cuáles no
 Hay que leer muchos registros a la vez. Si una se bloquea sería muy caro en cuanto a prestaciones. Idem con las penalidades de fallo caché. Por tanto, salvo en sistemas empotrados que suelen llevar superescalares menos agresivos, todos poseen emisión dinámica: el procesador decide en tiempo de ejecución qué instrucciones pueden emitirse a la vez y cuáles no.")
24
Resumen IF Un superescalar de grado m, puede emitir m instrucciones por ciclo, de forma que la caché debe ser capaz de atender esta demanda Ventana de Instrucciones: Fija. Hasta que no se han emitido todas las instrucciones de la ventana, no se puede acceder a caché a por otras Deslizante. A medida que las instrucciones se van emitiendo, nuevas instrucciones son leídas de la caché.

25
Intel Pentium 4

26
Intel Pentium Pro

27
R10k

Presentaciones similares

















>")

>")