Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Solución de problemas por búsqueda inteligente
Ana Lilia Laureano Cruces UAM-A

2
La solución de problemas requiere dos consideraciones…
Representación del problema en un espacio organizado. La capacidad de probar la existencia del estado objetivo en dicho espacio. Las anteriores premisas se traducen en: la determinación del estado objetivo y la determinación del camino óptimo guiado por este objetivo a través de una o más transiciones dado un estado inicial.

3
El sentido común… La búsqueda Qué La llave Dónde
El espacio de búsqueda

4
El espacio de búsqueda Se le conoce como una colección de estados.
En general los espacios de búsqueda en los problemas de IA no son completamente conocidos de forma apriori. De lo anterior ‘resolver un problema de IA’ cuenta con dos fases: 1) la generación del espacio de estados y la búsqueda del estado deseado en ese espacio.
 la generación del espacio de estados y la búsqueda del estado deseado en ese espacio.")
5
Debido a que ‘todo el espacio de búsqueda’ de un problema es muy grande, puede causar un bloqueo de memoria, dejando muy poco espacio para el proceso de búsqueda. Para solucionar esto, se expande el espacio paso a paso, hasta encontrar el estado objetivo.

6
Dependiendo de… la metodología de expansión del espacio de estados.
la forma de visita de ese espacio. Espacios en forma de árboles: A lo ancho (visita los nodos a lo ancho) En profundidad (visita los nodos en profundidad) Dichas búsquedas se conocen como búsquedas determinísticas.
 En profundidad (visita los nodos en profundidad) Dichas búsquedas se conocen como búsquedas determinísticas.")
7
Existen otras… Que nodo será visitado sin calcular los detalles en el algoritmo. Es más se pueden tener varias opciones de transición con las mismas condiciones, en un instante dado. A tales búsquedas se les conoce como no determinisiticas. La mayoría de las búsquedas en IA son no detrminísticas.

8
Método de genera-prueba
Es el más simple: BEGIN REPEAT Produce un nuevo estado y lo llama estado en curso; UNTIL estado en curso = estado objetivo; END

9
La parte más interesante en este algoritmo es la que se refiere a la generación de nuevos estados.
Esta parte no queda incluida en este algoritmo pero con el fin de formalizarla necesitamos definir la siguiente tupla: Nodos Arcos Objetivo curso

10
Nodos: representa el conjunto de estados en el espacio de búsqueda.
Arcos: representa un operador que aplicado a un estado permite la transición a otro. Objetivo: denota el estado deseado a ser identificado en los nodos y … En curso: representa el estado generado y comparado con el estado objetivo.

11
Grafo vs. árbol La diferencia básica entre estas dos estructuras de datos consiste en el número de padres de un determinado nodo: En el caso de un grafo, éste puede ser cualquier entero positivo. Para un árbol el máximo valor de éste es uno. A continuación se presentan dos algoritmos típicos para generar el espacio de búsqueda.

12
Búsqueda a lo ancho Profundidad 1 4 1 3 2 8 7 2 5 6 12 3 9 10 11

13
Procedure BusquALoAncho
BEGIN Elem = Obten (nodo) {del arbol} InserCola (elem, COLA) REPEAT elem = ExtraeElem (COLA) IF elem = objetivo Exito = Verdad (para) ELSE Elem = Obten (nodo) {hijos del nodo en curso del arbol} InsertaElem (elem, COLA) END UNTIL (ColaVacia OR Exito) END;
 {del arbol} InserCola (elem, COLA) REPEAT. elem = ExtraeElem (COLA) IF elem = objetivo. Exito = Verdad (para) ELSE. Elem = Obten (nodo) {hijos del nodo en curso del arbol} InsertaElem (elem, COLA) END. UNTIL (ColaVacia OR Exito) END;")
14
Principio del algoritmo…
Si el nodo en curso no es el estado objetivo, inserte en la COLA, las hojas del nodo en curso en cualquier orden y redefina el elemento del frente de la COLA. El algoritmo termina cuando se encuentra el estado objetivo.

15
Elementos en la COLA … n1 n2 n3 n4 n3 n4 n4 n5 n6 n5 n6 n7 n8

16
Complejidad del algoritmo
Supongamos que contamos con un árbol balanceado, esto es de cada nodo = b se recorre la misma profundidad d. Si estado objetivo no esta en d-1. Entonced las búsquedas falsas quedan representadas por: 1 + b + b2 + b3 + … + b d-1 = (bd - 1) / (b - 1), b>>1
 / (b - 1), b>>1.")
17
Así que con el fin … El estado objetivo puede encontrarse en el primer nodo, o En el último nodo, visitado del árbol Así el promedio de nodos visitados es: (1+bd ) / 2 En consecuencia el total de números visitados en un caso promedio se convierte en: (bd - 1) / (b-1) + (1 + bd) / 2 bd (b + 1) / 2 (b - 1). Debido a que la complejidad del algrotitmo (tiempo) es proporcional al número de nodos visitados, la expersión anterior nos da una medida de la complejidad.
 / 2. En consecuencia el total de números visitados en un caso promedio se convierte en: (bd - 1) / (b-1) + (1 + bd) / 2. bd (b + 1) / 2 (b - 1). Debido a que la complejidad del algrotitmo (tiempo) es proporcional al número de nodos visitados, la expersión anterior nos da una medida de la complejidad.")
18
La complejidad del espacio…
El número máximo de nodos es colocado en la COLA. Cuando el nodo más izquierdo de la rama con profundidad d en el árbol es colocado en la COLA. La longitud de la COLA se convierte en bd. Así la longitud en este caso se convierte en bd. Y la complejidad del algoritmo (tiempo) depende de la longitud de la COLA, en el peor de los casos, así este es de orden bd. En forma de reducir el performance del espacio de búsqueda se presenta el siguiente algoritmo.
 depende de la longitud de la COLA, en el peor de los casos, así este es de orden bd. En forma de reducir el performance del espacio de búsqueda se presenta el siguiente algoritmo.")
19
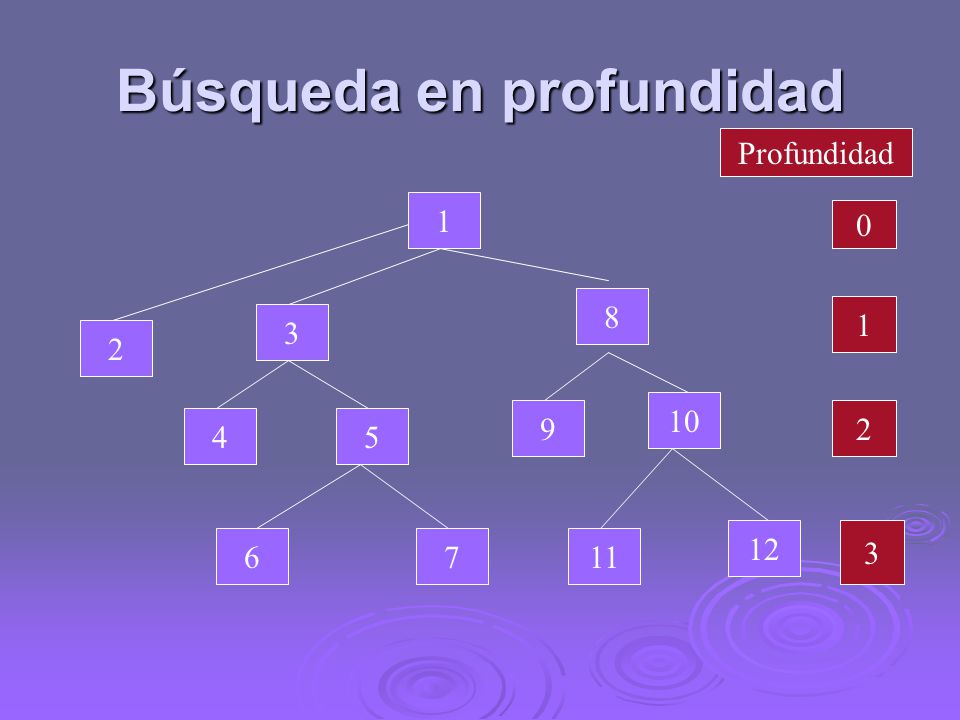
Búsqueda en profundidad
1 8 1 3 2 10 9 2 4 5 12 3 6 7 11
20
Procedure BusqEnProfundidad
BEGIN Elem = Obten (nodo) {del arbol} PushElem (elem, PILA) WHILE ~ (PilaVacia) OR (éxito) DO elem = PopPila (PILA) IF elem = objetivo Exito = Verdad (para) ELSE Elem = Obten (nodo) {hijos del nodo en curso del arbol} END END_WHILE END;
 {del arbol} PushElem (elem, PILA) WHILE ~ (PilaVacia) OR (éxito) DO. elem = PopPila (PILA) IF elem = objetivo. Exito = Verdad (para) ELSE. Elem = Obten (nodo) {hijos del nodo en curso del arbol} END. END_WHILE. END;")
21
Principio del algoritmo
El nodo raíz es colocado en en la PILA, para examinarlo se saca, si es el estado objetivo el algoritmo para, en caso contrario sus hijos son metidos en la PILA. El proceso continúa hasta que la PILA esta vacía o se tiene éxito.

22
Elementos en la PILA… n1 n8 n3 n2 n5 n4 n7 n6

23
La complejidad del espacio…
Se utiliza el máximo de memoria cuando se vista la máxima longitud la primera vez. Asumiendo que cada nodo cuenta con un factor de profundidad: cuando el nodo en la profundidad d es examinado, el número de nodos guardado en memoria son todos los nodos de esa profundidad que no han sido visitados (d), mas el nodo que esta examinándose. Debido a que en cada nivel existen b-1 nodos sin vistar, el número total de memoria requerida es d (b-1) + 1.
, mas el nodo que esta examinándose. Debido a que en cada nivel existen b-1 nodos sin vistar, el número total de memoria requerida es d (b-1) + 1.")
24
Así en este caso la complejidad del algoritmo (espacio) es una función lineal de b, mientras que en el caso del algoritmos de búsqueda a lo ancho es una función exponencial de b. De aquí que este sea un aspecto interesante en el caso del algoritmo de busqueda en profundidad.

25
Tiempo de complejidad Si se encuentra el estado objetivo en la posición d más izq. El número de nodos examinados es d + 1. Y si encontramos el estado objetivo en el nodo mas a la der. El número de nodos examinados incluye todos los nodos del árbol. En consecuencia el total de números visitados en un caso promedio se convierte en: (d + 1) / 2 + (bd / 2 (b - 1). b(bd + d) / 2 (b - 1).
 / 2 + (bd / 2 (b - 1). b(bd + d) / 2 (b - 1).")
26
Debido a que el tiempo requerido de corrida depende de la profundida del árbol.
Un camino alterno es reslover el problema controlando la prfundidad del árbol. El control de esta profundidad dada por el usario da origen a la búsqueda iterativa dependiente.

27
Si la profundidad de corte es 1, se genera solo el nodo raíz y lo examina.
En caso de que el nodo raíz no sea el objetivo, se incrmenta el limte del nivel de profundidad a 2 utilizando el algoritmo de busqueda en profundidad. De esta forma se desarrolla una búsqueda en la que se incrementa la profundidad dejando en cada iteración fuera a los hijos de nodo en curso.

28
La búsqueda iterativa dependiente...
Esta búsqueda no toma tanto tiempo como en el caso de el algoritmo general de búsqueda en profundidad.

29
Algoritmo de búsqueda iterativa dependiente
BEGIN ProfCor = 1; Permitido = N; { lo da usuario} exito = False REPEAT Elem = Obten (nodo); {del arbol} PushElem (elem, PILA) WHILE (~ (PilaVacia) AND (ProfCor < Permitido)) DO elem = PopPila (PILA) IF elem = objetivo exito = Verdad (para) ELSE Elem = Obten (nodo) {hijos del nodo en curso del arbol} END END_IF ProfCor = ProfCor + 1; UNTIL éxito OR ProfCor > Permitido
; {del arbol} PushElem (elem, PILA) WHILE (~ (PilaVacia) AND (ProfCor < Permitido)) DO. elem = PopPila (PILA) IF elem = objetivo. exito = Verdad (para) ELSE. Elem = Obten (nodo) {hijos del nodo en curso del arbol} END. END_IF. ProfCor = ProfCor + 1; UNTIL éxito OR ProfCor > Permitido.")
30
fin

Presentaciones similares


















>")
