Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Repaso de matrices DAGOBERTO SALGADO HORTA

2
Matrices Elemento: aij Tamaño: m n Matriz cuadrada: n n (orden n)
Elementos de la diagonal: ann Vector columna (matriz n x 1) Vector fila (matriz 1 x n)
 Vector fila. (matriz 1 x n)")
3
Suma: Multiplicación por un escalar:

4
Si A, B, C son matrices mn, k1 y k2 son escalares:
(i) A + B = B + A (ii) A + (B + C) = (A + B) + C (iii) (k1k2) A = k1(k2A) (iv) 1 A = A (v) k1(A + B) = k1A + k1B (vi) (k1 + k2) A = k1A + k2A
 A + B = B + A (ii) A + (B + C) = (A + B) + C (iii) (k1k2) A = k1(k2A) (iv) 1 A = A (v) k1(A + B) = k1A + k1B (vi) (k1 + k2) A = k1A + k2A.")
5
Multiplicación: (a) (b) Nota: En general, AB BA
 (b) Nota: En general, AB BA")
6
Transpuesta de una matriz A:
(i) (AT)T = A (ii) (A + B)T = AT + BT (iii) (AB)T = BTAT (iv) (kA)T = kAT Nota: (A + B + C)T = AT + BT + CT (ABC)T = CTBTAT
 (AT)T = A (ii) (A + B)T = AT + BT (iii) (AB)T = BTAT (iv) (kA)T = kAT. Nota: (A + B + C)T = AT + BT + CT (ABC)T = CTBTAT.")
7
Matrices triangulares
Matriz cero A + 0 = A A + (–A) = 0 Matrices triangulares
 = 0. Matrices triangulares.")
8
Matriz diagonal: Matriz identidad: A: m n, entonces Im A = A In = A
Matriz cuadrada n n, i ≠ j, aij = 0 Matriz identidad: A: m n, entonces Im A = A In = A

9
Una matiz A n × n es simétrica si AT = A.

10
Resolución de sistemas de ecuaciones lineales:
Matriz aumentada asociada, para resolver el sistema de ecuaciones lineales.

11
2x1 + 6x2 + x3 = 7 x1 + 2x2 – x3 = –1 5x1 + 7x2 – 4x3 = 9 x3 = 5, x2 = –3, x1 = 10

12
Resolver mediante el método de Gauss-Jordan
x1 + 3x2 – 2x3 = – 7 4x1 + x2 + 3x3 = 5 2x1 – 5x2 + 7x3 = 19 Entonces: x2 – x3 = –3 x1 + x3 = 2 Haciendo x3 = t, tenemos x2 = –3 + t, x1 = 2 – t.

13
Resolver: x1 + x2 = 1 4x1 − x2 = −6 2x1 – 3x2 = 8
0 + 0 = 16 !! No tiene soluciones.

14
Vectores fila: u1 = (a11 a12 … a1n), u2 = (a21 a22, … a2n),…, um = (am1 am2 … amn) Vectores columna: El rango de una matriz A m n, es el máximo número de vectores fila linealmente independientes. rang A = 2.

15
Siempre hay soluciones
AX = 0 Siempre hay soluciones (consistente) Solución única X = 0 (solución trivial) rang(A) = n Infinitas soluciones Rang(A) < n n – r parámetros
 Solución única X = 0. (solución trivial) rang(A) = n. Infinitas soluciones. Rang(A) < n. n – r parámetros.")
16
rang(A) < rang(A│B)
AX = B, B≠0 Consistente rang(A) = rang(A│B) Inconsistente rang(A) < rang(A│B) Solución única rang(A) = n Infinitas soluciones rang(A) < n n – r parámetros
 = rang(A│B) Inconsistente. rang(A) < rang(A│B) Solución única. rang(A) = n. Infinitas soluciones. rang(A) < n. n – r parámetros.")
17
Determinantes Expansión por cofactores a lo largo de la primera fila.

18
El cofactor de aij es Cij = (–1)i+ j Mij donde Mij se llama menor. det A = a11C11 + a12C12 + a13C13 ... O por la tercera fila: det A = a31C31 + a32C32 + a33C33 Podemos expandir por filas o columnas.

20
Más corto desarrollando por la segunda fila...

22
det AT = det A Si dos filas (columnas) de una matriz A de n × n son idénticas, entonces det A = 0.
 de una matriz A de n × n son idénticas, entonces det A = 0.")
23
Si todos los elementos de una fila (columna) de una
matriz A de n × n son cero, entonces det A = 0. Si B es la matriz obtenida por intercambio de dos filas (columnas) de una matriz A n × n, entonces: det B = −det A
 de una matriz A n × n, entonces: det B = −det A.")
24
Si B se obtiene de una matriz A n × n multiplicando una fila (columna) por un número real k, entonces: det B = k det A

25
Si A y B son matrices n × n, entonces
det AB = det A det B. det AB = −24, det A = −8, det B = 3, det AB = det A det B.

26
Si B se obtiene como combinaciones lineales de filas o columnas de una matriz A n × n, entonces:
det B = det A det A = 45 = det B = 45.

27
matriz triangular inferior
matriz diagonal

28
ai1 Ck1 + ai2 Ck2 + …+ ain Ckn = 0, para i k
Supongamos que A es una matriz n n. Si ai1, ai2, …, ain son los elementos de la i-ésima fila y Ck1, Ck2, …, Ckn son los cofactores de la k-ésima fila, entonces: ai1 Ck1 + ai2 Ck2 + …+ ain Ckn = 0, para i k Igualmente, si a1j, a2j, …, anj son los elementos de la j-ésima columna y C1k, C2k, …, Cnk son los cofactores de la k-ésima columna, entonces: a1j C1k + a2j C2k + …+ anj Cnk = 0, para j k

29
Demostración Sea B la matriz que obtenemos de A al cambiarle los elementos de la i-ésima fila por los de su k-ésima fila: bi1 = ak1, bi2 = ak2, …, bin = akn B tendrá entonces dos filas idénticas de modo que det B = 0, y:

31
Inversa de un matriz Sea A una matriz n n. Si existe una matriz
n n B tal que AB = BA = I donde I es la matriz identidad n n, entonces se dice que A es una matriz no singular o invertible. Y B es la matriz inversa de A. Si A carece de inversa, se dice que es una matriz singular. Sean A, B matrices no singulares. (i) (A-1)-1 = A (ii) (AB)-1 = B-1A-1 (iii) (AT)-1 = (A-1)T
 (A-1)-1 = A (ii) (AB)-1 = B-1A-1 (iii) (AT)-1 = (A-1)T.")
32
Matriz adjunta Sea A una matriz n × n. La matriz formada por la transpuesta de la matriz de cofactores correspondientes a los elementos de A: se llama adjunta de A y se denota por adj A.

33
Encontrar la matriz inversa:
Sea A una matriz n × n. Si det A 0, entonces: Para n =3:

38
Singular

39
AX = B Si m = n, y A es no singular, entonces: X = A-1B

42
Regla de Cramer

43
Un sistema homogéneo de n ecuaciones lineales, AX = 0 tiene solo la solución trivial (ceros) si y solo si A es no singular. Un sistema homogéneo de n ecuaciones lineales, AX = 0 tiene una solución no trivial si y solo si A es singular.

44
Problemas de autovalores
DEFINICIÓN Sea A una matriz n n. Un número se dice que es un autovalor de A si existe una solución vector K, distinto de cero para: AK = K El vector solución K es el autovector correspondiente al autovalor . Autovalores y autovectores Los autovalores de una matriz triangular, inferior o superior, o de una matriz diagonal son los elementos de la diagonal.

45
Verifica que es el autovector de la matriz:
Solución Autovalor

46
Podemos escribir AK = K como:
(A – I)K = 0 Que es lo mismo que un sistema de ecuaciones lineales homogéneo. Si queremos que K sea una solución distinta de cero, debería ocurrir que: det (A – I) = 0 Observa que det (A – I) nos proporcionará un polinomio de grado n, que llamaremos ecuación característica.
K = 0. Que es lo mismo que un sistema de ecuaciones lineales homogéneo. Si queremos que K sea una solución distinta de cero, debería ocurrir que: det (A – I) = 0. Observa que det (A – I) nos proporcionará un polinomio de grado n, que llamaremos ecuación característica.")
47
(A – I)K = 0 Encuentra los autovalores y autovectores de:
–3 – 2 + 12 = 0 ( + 4) ( – 3) = 0 = 0, −4, 3. Ahora encontraremos los autovectores para cada autovalor.
 ( – 3) = 0 = 0, −4, 3. Ahora encontraremos los. autovectores para cada. autovalor.")
48
(i) 1 = 0 (A – 1I)K = 0 Tomando k3 = −13
 1 = 0 (A – 1I)K = 0 Tomando k3 = −13")
49
(ii) 2 = −4 (A – 2I)K = 0 k1 = −k3 , k2 = 2k3. Tomando k3 = 1:
 2 = −4 (A – 2I)K = 0 k1 = −k3 , k2 = 2k3. Tomando k3 = 1:")
50
(iii) 3 = 3 (A – 3I)K = 0 k1 = – k3, k2 = –(3/2) k3. Y tomando k3 = –2,
 3 = 3 (A – 3I)K = 0 k1 = – k3, k2 = –(3/2) k3. Y tomando k3 = –2,")
51
Encuentra los autovalores y autovectores de:
1 = 2 = 5 es un autovalor de multiplicidad 2. A partir de (A – 5I|0), tenemos: Tomando k2 = 1, tenemos k1 = 2, y entonces
, tenemos: Tomando k2 = 1, tenemos. k1 = 2, y entonces.")
52
Encuentra los autovalores
y autovectores de: 1 = 11, 2 = 3 = 8 (multiplicidad 2).
.")
53
(i) 1 = 11, por el método de Gauss-Jordan:
k1 = k3, k2 = k3. Si k3 = 1, entonces:

54
(ii) 2 = 8, k1 + k2 + k3 = 0. Podemos elegir dos de ellos de manera arbitraria. Tomemos k2 = 1, k3 = 0: Y k2 = 0, k3 = 1:

55
AK = K, Autovalores y autovectores complejos
Sea A una matriz cuadrada de elementos reales. Si = + i, 0, es un autovalor complejo de A, entonces su conjugado es también un autovalor de A. Si K es un autovector correspondiente a , entonces el autovector conjugado es un autovector correspondiente a . Demostración: AK = K,

56
1 = 5 + 2i Encuentra los autovalores y autovectores de:
(A – 1I)K = 0 1 = 5 + 2i k2 = (1 – 2i) k1, tomando k1 = 1:
K = 0. 1 = 5 + 2i. k2 = (1 – 2i) k1, tomando k1 = 1:")
57
Potencias de una matriz
Sea A, una matriz n × n. Definimos la potencia m-ésima de A como:

58
Teorema de Cayley-Hamilton
Ecuación característica: det (A – I) = 0 Una matriz A satisface su propia ecuación característica:
 = 0. Una matriz A satisface su propia. ecuación característica:")
59
Comprobarlo con: 2 − – 2 = 0. Y por el teorema de Cayley-Hamilton: A2 − A – 2I = 0 Observa que entonces: A2 = A + 2I y 2 = + 2 Y podemos escribir las sucesivas potencias de A como: A3 = AA2 = A(A+ 2I ) = A2 + 2A = 3A + 2I A4 = AA3 = A (3A+2I) = 3A2+2A = 5A+ 6I A5 = 11A + 10I A6 = 21A + 22I ... Am = c1A + c0I ... m = c1 + c0
 = A2 + 2A = 3A + 2I. A4 = AA3 = A (3A+2I) = 3A2+2A = 5A+ 6I A5 = 11A + 10I. A6 = 21A + 22I. ... Am = c1A + c0I ... m = c1 + c0.")
60
O sea que podemos escribir:
Am = c1A + c0I y m = c1 + c0 2 − – 2 = 0; 1 = −1 , 2 = 2:

61
Y en general, para una matriz de orden n:
Am = c0I + c1A + c2A2 +…+ cn–1An–1 m = c0 + c1 + c2 2 +…+ cn–1 n–1 donde los ck (k = 0, 1,…, n–1), dependen de m.
, dependen de m.")
62
Calcula Am para: Solución 3 + 2 2 + – 2 = 0, = –1, 1, 2. Am = c0I + c1A +c2A2 m = c0 + c1 + c2 2 Con 1 = –1, 2 = 1, 3 = 2, obtenemos: (–1)m = c0 – c1 + c2 1 = c0 + c1 + c2 2m = c0 +2c1 + 4c2
m = c0 – c1 + c2 1 = c0 + c1 + c2 2m = c0 +2c1 + 4c2.")
63
Puesto que Am = c0I + c1A +c2A2, tenemos:
Por ejemplo, para m = 10

64
Por el teorema de Cayley-Hamilton:. A2 – A – 2I = 0,
Por el teorema de Cayley-Hamilton: A2 – A – 2I = 0, I = (1/2)A2 – (1/2)A, Multiplicando a ambos lados por A–1 podemos encontrar la inversa: A–1 = (1/2)A – (1/2)I
A2 – (1/2)A, Multiplicando a ambos lados por A–1 podemos encontrar la inversa: A–1 = (1/2)A – (1/2)I.")
65
Una matriz A n n es simétrica si A=AT
Si A es simétrica con elementos reales, entonces los autovalores de A son reales. AK = K, Transponiendo y multiplicando por K por la derecha:

66
Autovectores ortogonales
Al igual que definimos el producto escalar entre vectores: x y = x1 y1 + x2 y2 + … + xn yn podemos definirlo con matrices (vectores fila o columna): X Y XT Y = x1 y1 + x2 y2 + … + xn yn Veamos que si A es una matriz n × n simétrica, los autovectores correspondientes a distintos (diferentes) autovalores son ortogonales.
: X Y XT Y = x1 y1 + x2 y2 + … + xn yn. Veamos que si A es una matriz n × n simétrica, los autovectores correspondientes a distintos (diferentes) autovalores son ortogonales.")
67
Demostración Sean 1,, 2 dos autovalores distintos correspondientes a los autovectores K1 y K2.
AK1 = 1K1 , AK2 = 2K2 (AK1)T = K1TAT = K1TA = 1K1T K1TAK2 = 1K1TK2 AK2 = 2K2, K1TAK2 = 2K1TK = 1K1TK2 − 2K1TK2 0 = (1 − 2) K1TK2 Como 1 2, entonces K1TK2 = 0.
T = K1TAT = K1TA = 1K1T. K1TAK2 = 1K1TK2 AK2 = 2K2, K1TAK2 = 2K1TK2 0 = 1K1TK2 − 2K1TK2 0 = (1 − 2) K1TK2 Como 1 2, entonces K1TK2 = 0.")
68
= 0, 1, −2 y

69
Matriz ortogonal: Una matriz A n × n no singular es ortogonal si: A-1 = AT A es ortogonal si ATA = I. ITI = II = I

70
Una matriz A n × n es ortogonal si y solo si sus vectores columnas X1, X2, …, Xn forman un conjunto ortonormal. Es decir si: XiTXj = 0, i j , i, j =1, 2, …, n XiTXi = 1, i =1, 2, …, n Los Xi forman un conjunto ortonormal.

72
Y los vectores son unitarios, ortonormales:

73
Vimos Verifica que PT = P-1.

74
Autovalor dominante Sean los autovalores
de una matriz A n × n. El autovalor se llama autovalor dominante de A si: Un autovector asociado se denomina autovector dominante de A.

75
Método de las potencias
Vector n 1 Supongamos que A tiene un autovalor dominante. Supongamos que |1| > |2| … |n| con K1, K2, …, Kn autovectores asociados linealmente independientes. Entonces: Como AKi = iKi , entonces: AX0 = c1AK1 + c2AK2 + … + cnAKn

76
Multiplicando por A sucesivamente:
(...) Como |1| > |i|, i = 2, 3, …, n; cuando m , podemos aproximar:
 Como |1| > |i|, i = 2, 3, …, n; cuando m , podemos aproximar:")
77
Observemos que un autovector multiplicado por una constante sigue siendo un autovector. De modo que podemos escribir: Am X0 = Xm De modo que Xm será una aproximación al autovector dominante. Puesto que AK = K, AKK= KK que nos da una aproximación al autovalor dominante. Cociente de Rayleigh.

78
6 Xi 7 5 4 3 i

80
Matriz diagonalizable
Si existe una matriz P, tal que P-1AP = D sea diagonal, entonces decimos que A es diagonalizable. Si A es una matriz n × n que tiene n autovectores K1, K2, …, Kn linealmente independientes, entonces A es diagonalizable. TEOREMA Condición suficiente de diagonalizabilidad

81
Demostración Puesto que P = (K1, K2, K3) es no singular, entonces existe P-1 y Así que P-1AP = D.
 es no singular, entonces existe P-1 y Así que P-1AP = D.")
82
Si A es una matriz n n con n autovalores
distintos, entonces es diagonalizable. Condición suficiente de diagonalización Tenemos que = 5, 5. Y solo podemos encontrar un autovector. La matriz no puede diagonalizarse.

83
Diagonaliza: = 1, 4.

85
= −1, 1, 1. = −1 = 1 junto con K1, forman tres vectores linealmente independientes. Luego la matriz es diagonalizable. P-1AP = D

86
Si existe una matriz P ortogonal que puede diagonalizar a A, decimos que A es ortogonalmente diagonalizable. Una matriz A n x n es ortogonalmente diagonalizable si y solo si es simétrica. P diagonaliza a A: P-1AP = D, A = PDP-1. P es ortogonal: P-1 = PT, entonces: A = PDPT. AT = (PDPT)T = PDTPT = PDPT = A Luego A es simétrica.
T = PDTPT = PDPT = A Luego A es simétrica.")
Presentaciones similares
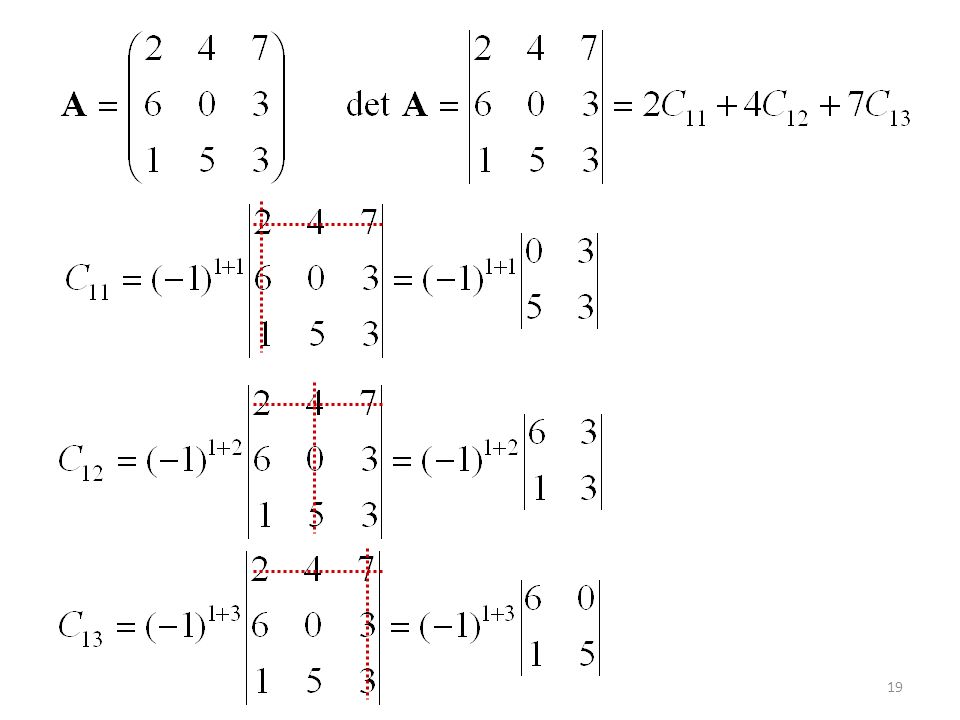
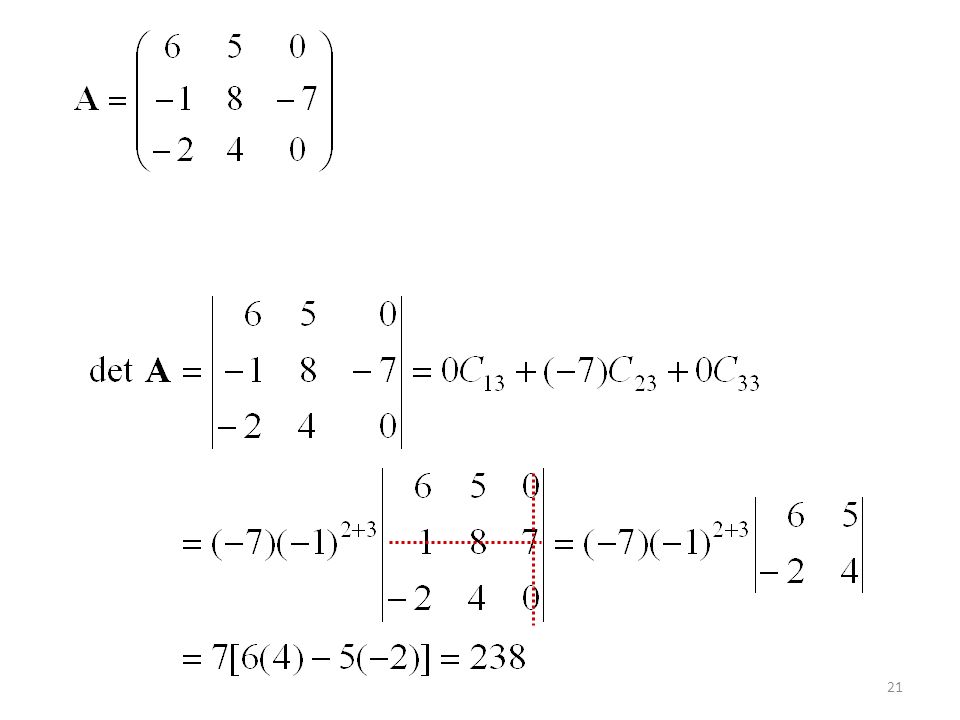
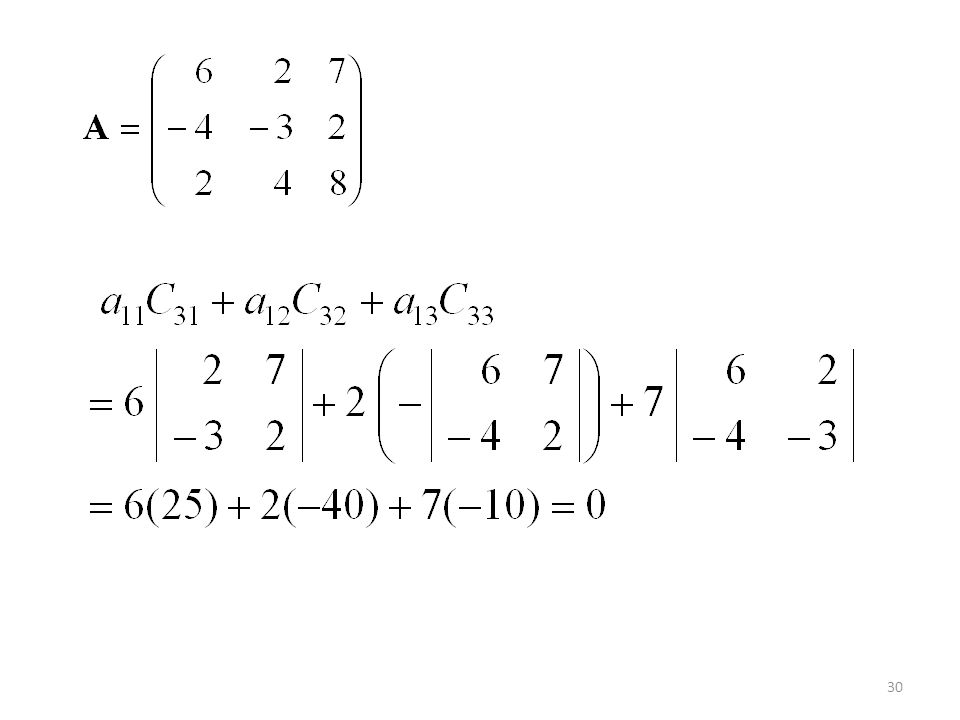
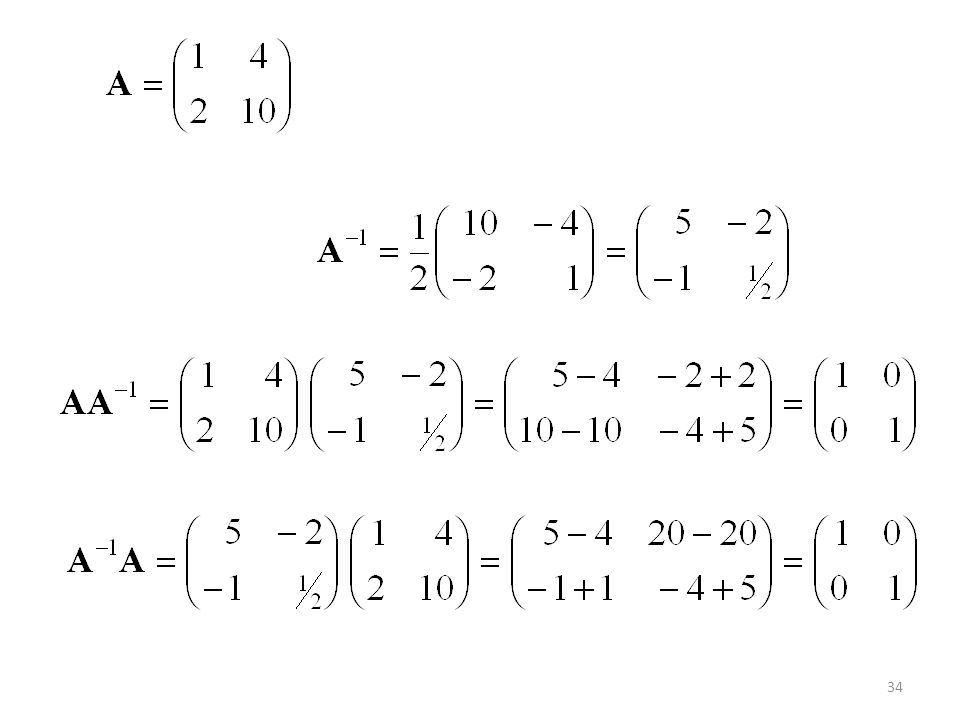


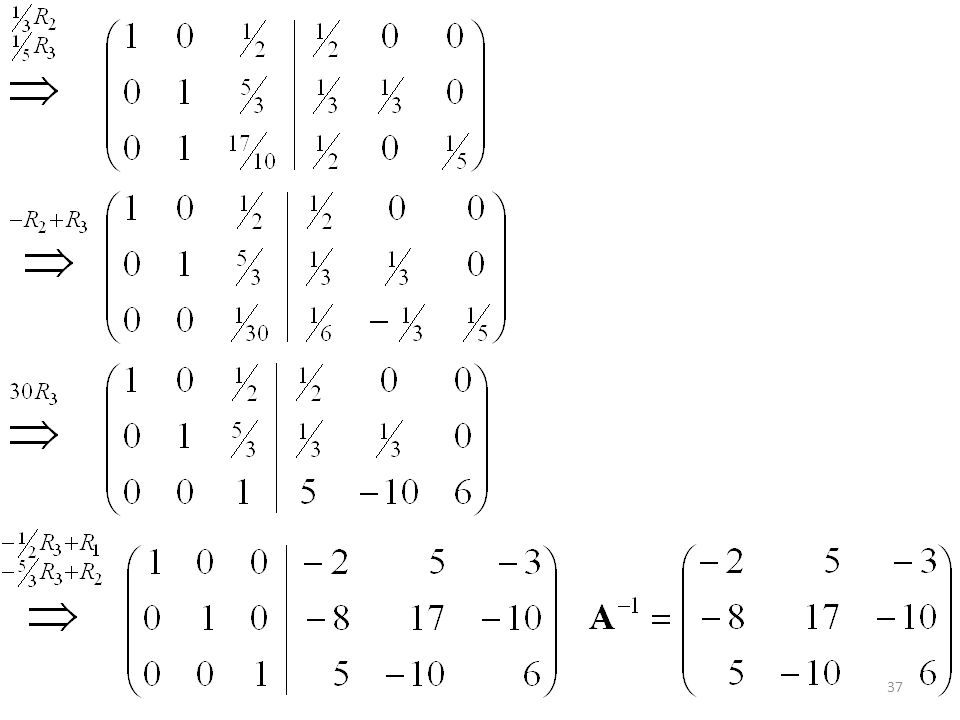
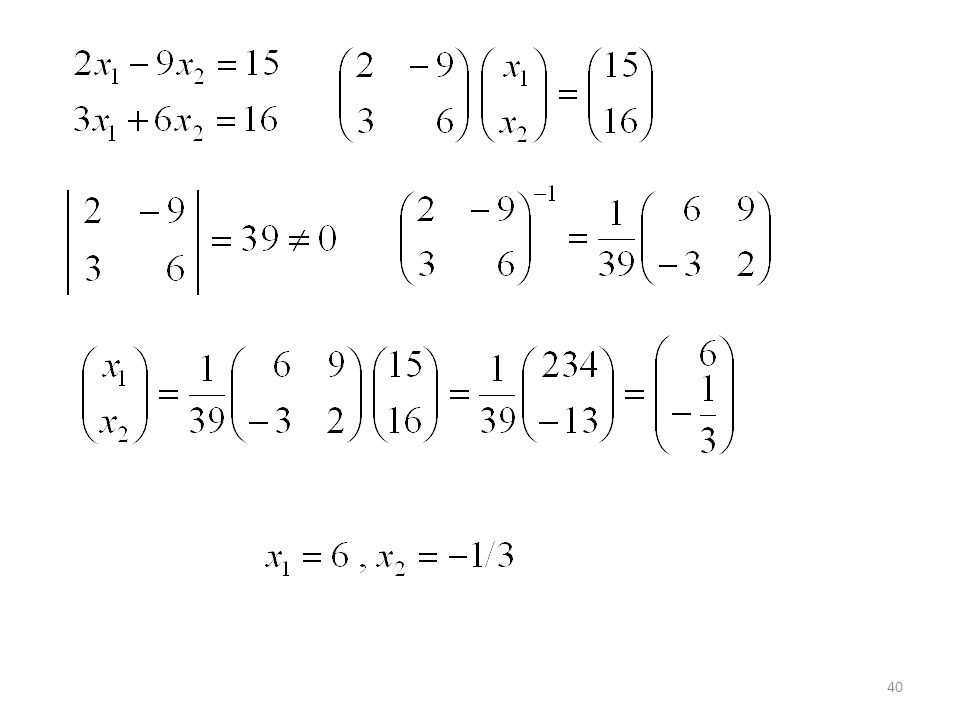
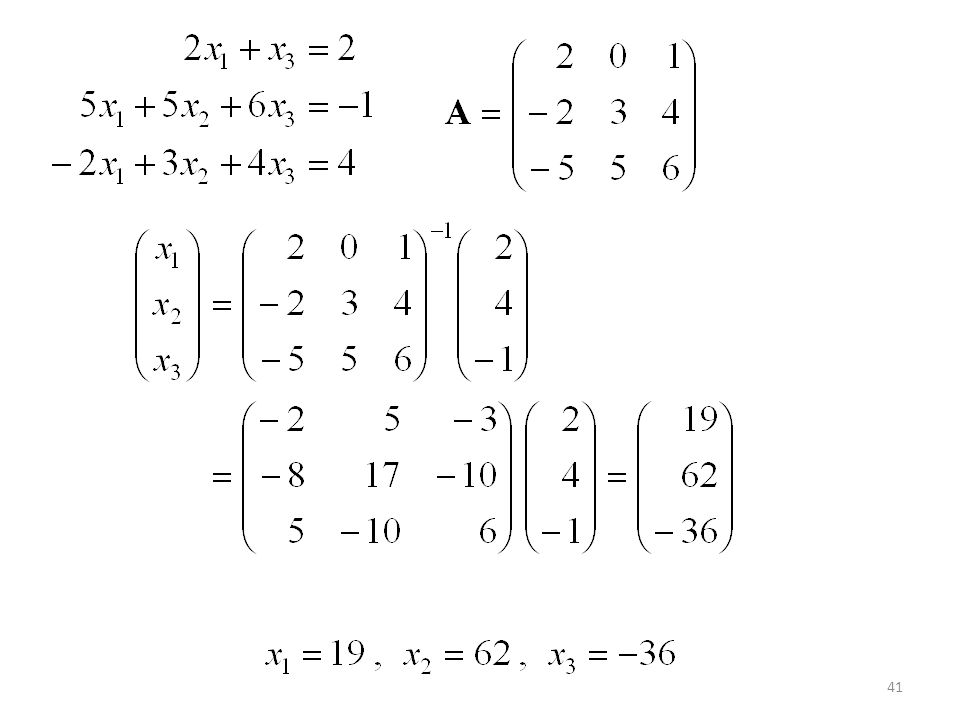
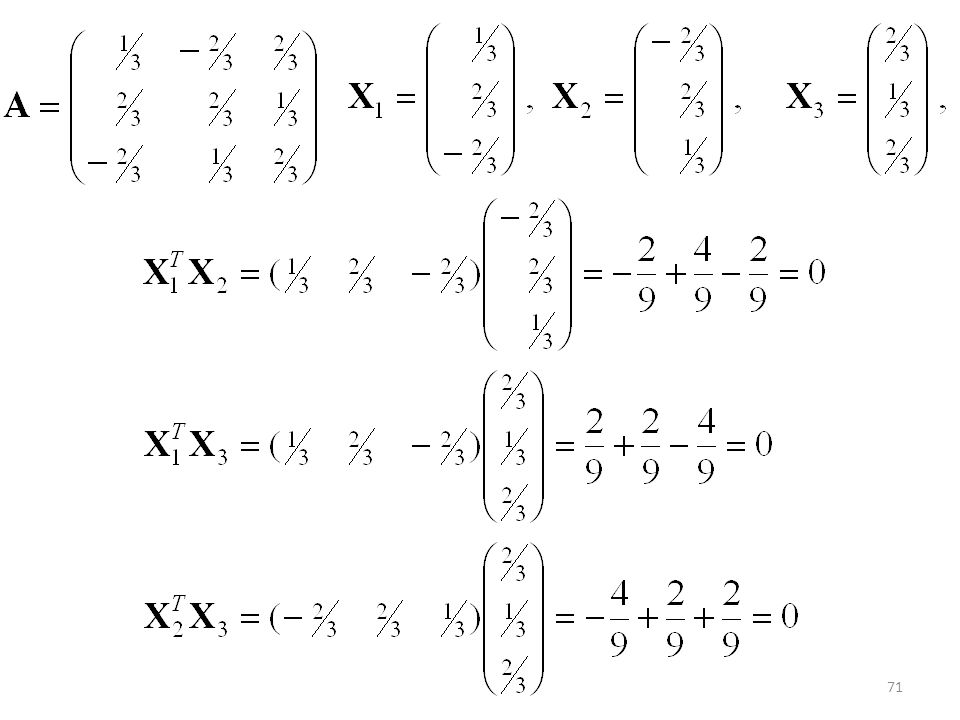
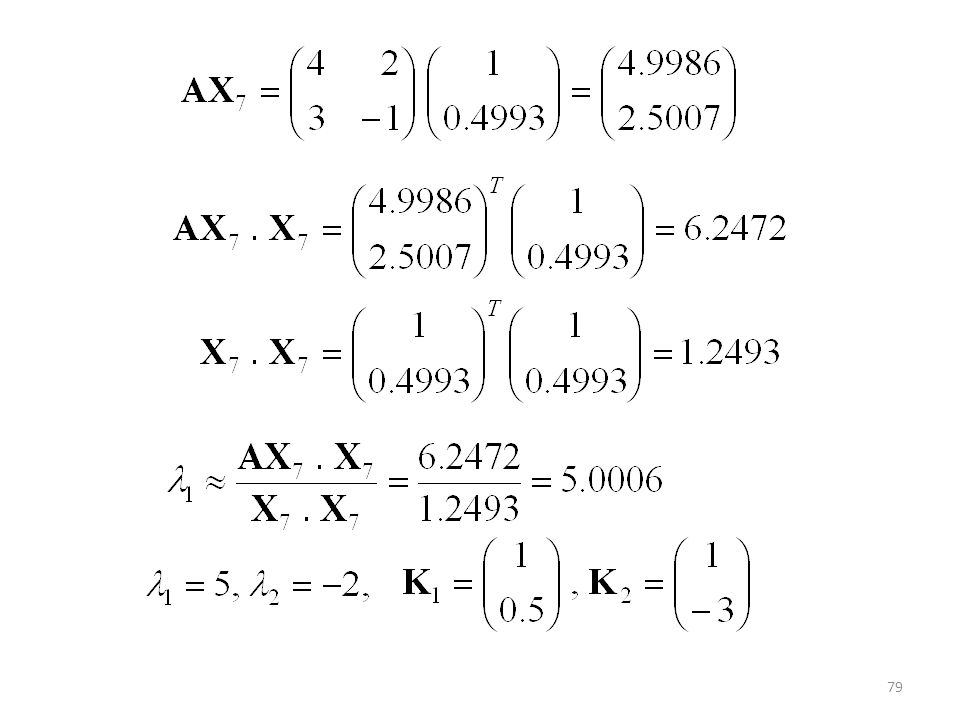
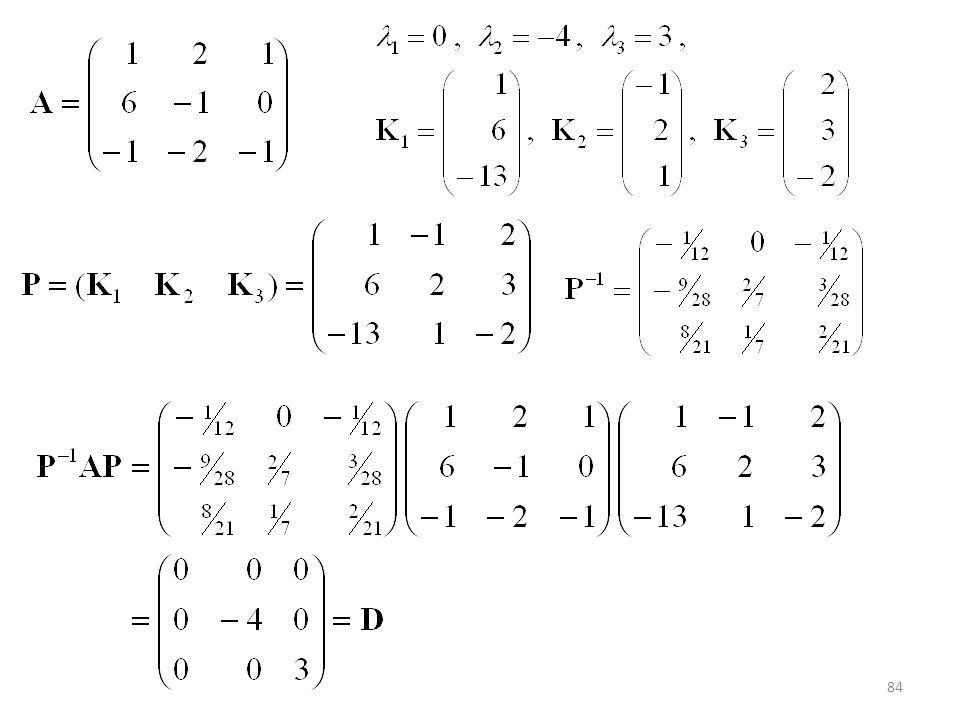






 Noviembre de 2004.>")












