Descargar la presentación
La descarga está en progreso. Por favor, espere

1
ARQUITECTURA DE LOS SISTEMAS DE BASES DE DATOS

2
La arquitectura de un Sistema de Bases de Datos está influenciada en gran medida por el sistema informático subyacente en el que se ejecuta. Hay que tomar en cuenta aspectos de la Arquitectura de la computadora como la conexión en red, el paralelismo y la distribución.

3
Y otras, se ejecuten en los Sistemas Clientes.
La Conexión en Red de varias computadoras permite que algunas tareas se ejecuten en un Sistema Servidor. Y otras, se ejecuten en los Sistemas Clientes. Esta división de trabajo ha conducido al desarrollo de Sistemas de Bases de Datos Cliente-Servidor. El Procesamiento Paralelo dentro de una computadora permite acelerar las actividades del SBD. Proporcionando a las transacciones unas respuestas más rápidas. Así como la capacidad de ejecutar más transacciones por segundo

4
Cluster de PCs

5
Las consultas pueden procesarse de manera que se explote el paralelismo ofrecido por el sistema.
La necesidad del Procesamiento Paralelo ha conducido al desarrollo de los Sistemas de Bases de Datos Paralelos. Se ha dado la distribución natural de los datos a través de las distintas localidades, agencias, departamentos, etc. de una organización. Permitiendo que los datos residan donde han sido generados o donde son más necesarios. Pero con la característica de que siguen siendo accesibles desde otros lugares o sitios diferentes.

6
El hecho de guardar varias copias de la BD en diferentes sitios permite que puedan continuar las operaciones sobre la BD, aún cuando algún sitio se vea afectado. Esto permite incrementar la disponibilidad del sistema, aún cuando se vea afectado por desastres naturales. Se han desarrollado los Sistemas Distribuidos de Bases de Datos para manejar los datos distribuidos geográfica o administrativamente a lo largo de múltiples SBD.

7
ARQUITECTURA CENTRALIZADA Y CLIENTE/SERVIDOR

8
Los Sistemas de Bases de Datos Centralizados son aquellos que se ejecutan en un único sistema, sin interaccionar con ninguna otra computadora. Tales sistemas comprenden desde los SBD Monousuarios ejecutándose en una PC, hasta los SBD de alto rendimiento ejecutándose en grandes sistemas. Los SBD diseñados para funcionar sobre sistemas monousuarios no suelen proporcionar muchas de las facilidades que ofrecen los sistemas multiusuarios. Hoy en día, las computadoras pueden tener varios procesadores, utilizando Paralelismo de Grano Grueso.

9
Estas computadoras comparten la misma memoria principal.
Las BD que se ejecutan en tales máquinas habitualmente no intenan dividir una consulta simple entre los procesadores. En vez de eso, ejecutan cada consulta en cada procesador posibilitando la concurrencia de varias consultas. Permitiendo ejecutar un mayor número de transacciones por segundo. Las BD diseñadas para la PCs monoprocesador ya disponen de Multitarea.

10
Permitiendo que varios procesos se ejecuten a la vez en el mismo procesador.
Se puede utilizar Tiempo Compartido, mientras que para el usuario aparentan que los procesos se ejecutan en paralelo. SISTEMAS CLIENTE/SERVIDOR Los Sistemas Cliente/Servidor tienen su funcionalidad dividida entre el Sistema Servidor y un conjunto de Sistemas Clientes. Las computadoras personales son ahora más rápidas, más potentes y más baratas.

11
Los sistemas se han ido distanciando de las arquitectura centralizada.
Las terminales conectadas a un sistema central han sido suplantadas por PCs. De igual forma, la interfaz de usuario, que antes era manejado por el servidor, ahora se maneja por la PC. Como consecuencia los Sistemas Centralizados actúan hoy como Sistemas Servidores. Que se encargan de servir o atender las peticiones del Sistema Cliente.

12
La funcionalidad de una BD se puede dividir en dos partes:
La parte visible al usuario. Y la parte del Servidor. La parte visible al usuario está formado por herramientas como formularios, diseñadores de informes y facilidades gráficas. La interfaz entre la parte visible al usuario y el sistema servidor puede ser SQL o una aplicación. Las normas como ODBC y JDBC, se desarrollaron para lograr la conexión entre clientes y servidor.

13
Antes de esto, con la carencia de normas, tanto la interfaz visible como el servidor eran proporcionados por el mismo distribuidor. Existen Herramientas de Desarrollo de Aplicaciones que se utilizan para construir interfaces de usuario. Que proporcionan herramientas gráficas que se pueden utilizar para construir interfaces sin programar. Algunas de estas herramientas son: PowerBuilder, Magic y Borland Delphi; también se puede utilizar Visual Basic.

14
Algunos sistemas de procesamiento de transacciones proporcionan una interfaz de Llamada a Procedimientos Remotos para Transacciones. Logrando conectar los Clientes con el Servidor, a través de estas llamadas. Las llamadas hechos por los Clientes se engloban en una única transacción al Servidor final. De este modo, si la transacción se cancela, el Servidor puede deshacer los efectos de las llamadas a procedimientos remotos individuales.

15
ARQUITECTURAS DE SISTEMAS SERVIDORES
Los sistemas servidores pueden dividirse en: Servidores de Transacciones, y Servidores de Datos. Los Servidores de Transacciones, también llamados sistemas Servidores de Consultas, proporcionan una interfaz a través de la cual los clientes pueden enviar peticiones para realizar una acción que el servidor ejecutará. Después, los valores resultantes se regresarán al cliente.

16
Los Sistemas Servidores de Datos permiten a los clientes interaccionar son los servidores, realizando peticiones de lectura o modificación de datos en unidades tales como archivos o páginas. Por ejemplo, los Servidores de Archivos proporcionan una interfaz de sistema de archivos a través de la cual los clientes pueden crear, modificar, leer y borrar archivos. En cambio, los servidores de datos de los SBD ofrecen más funcionalidades, ya que pueden soportar elementos pequeños como tuplas o atributos. Además de asegurar que los datos nunca se quedan en un estado inconsistente.

17
Los Sistemas Servidores de Datos se utilizan en redes de área local, en las que se alcanza una alta velocidad de conexión entre el cliente y el servidor. Las arquitectura de los servidores de datos se han hecho populares en los SBD Orientadas a Objetos. En esta arquitectura surgen algunos aspectos interesantes para reducir el tiempo de comunicación entre el cliente y el servidor: Envío de Páginas o Envío de Elementos. La unidad de comunicación de datos puede ser una página, una tupla o un objeto.

18
Bloqueo. La concesión del bloqueo de los elementos de datos que el servidor envía a los clientes la realiza habitualmente el propio servidor. Caché de Datos. Los datos que se envían al cliente a favor de una transacción se pueden alojar en una caché del cliente, incluso una vez completada la transacción. Caché de Bloqueos. Los bloqueos también pueden ser almacenados en la memoria caché del cliente (si los datos están divididos entre los clientes), de manera que un cliente rara vez necestia datos que están siendo utlizados por otros clientes.
, de manera que un cliente rara vez necestia datos que están siendo utlizados por otros clientes.")
19
SISTEMAS PARALELOS

20
SISTEMAS PARALELOS Los Sistemas Paralelos mejoran la velocidad de procesamiento y de E/S mediante la utilización de varios CPUs y Discos. Cada vez son más comunes las máquinas paralelas, lo que hace que cada vez sea más importante el estudio de los Sistemas Paralelos de BD. El impulso en los Sistemas Paralelos de BD ha sido la demanda de aplicaciones que han de manejar BD extremadamente grandes (del orden de los Terabytes = 1012 bytes).
.")
21
Sistemas que tienen que procesar un número enorme de transacciones por segundo (del orden de miles/seg.). En el procesamiento paralelo se realizan muchas operaciones simultáneamente. Una máquina paralela de grano grueso consiste en un pequeño número de potentes procesadores. Una máquina masivamente paralela o de grano fino utiliza miles de procesadores más pequeños.

22
Para medir el rendimiento de los SBD existen dos medidas principales:
Las computadoras masivamente paralelas se distinguen de las máquinas paralelas de grano grueso, porque son capaces de soportar un grado de paralelismo mucho mayor. Para medir el rendimiento de los SBD existen dos medidas principales: a) La Productividad, número de tareas que pueden completarse en un intervalo de tiempo determinado. b) El Tiempo de Respuesta, cantidad de tiempo que necesita para completar una única tarea a partir del momento en que se envíe. Un sistema que procese un gran número de pequeñas transacciones puede mejorar la productividad, realizando muchas transacciones en paralelo.
 La Productividad, número de tareas que pueden completarse en un intervalo de tiempo determinado. b) El Tiempo de Respuesta, cantidad de tiempo que necesita para completar una única tarea a partir del momento en que se envíe. Un sistema que procese un gran número de pequeñas transacciones puede mejorar la productividad, realizando muchas transacciones en paralelo.")
23
Un sistema que procese transacciones largas puede mejorar el tiempo de respuesta así como la productividad, realizando en paralelo las distintas subtareas de cada transacción. GANANCIA DE VELOCIDAD Y AMPLIABILIDAD La ganancia de velocidad se refiere a la ejecución en menos tiempo de una tarea dada, mediante el incremento del grado de paralelismo. La Ampliabilidad se refiere al manejo de transacciones más largas, mediante el incremento del grado de paralelismo.

24
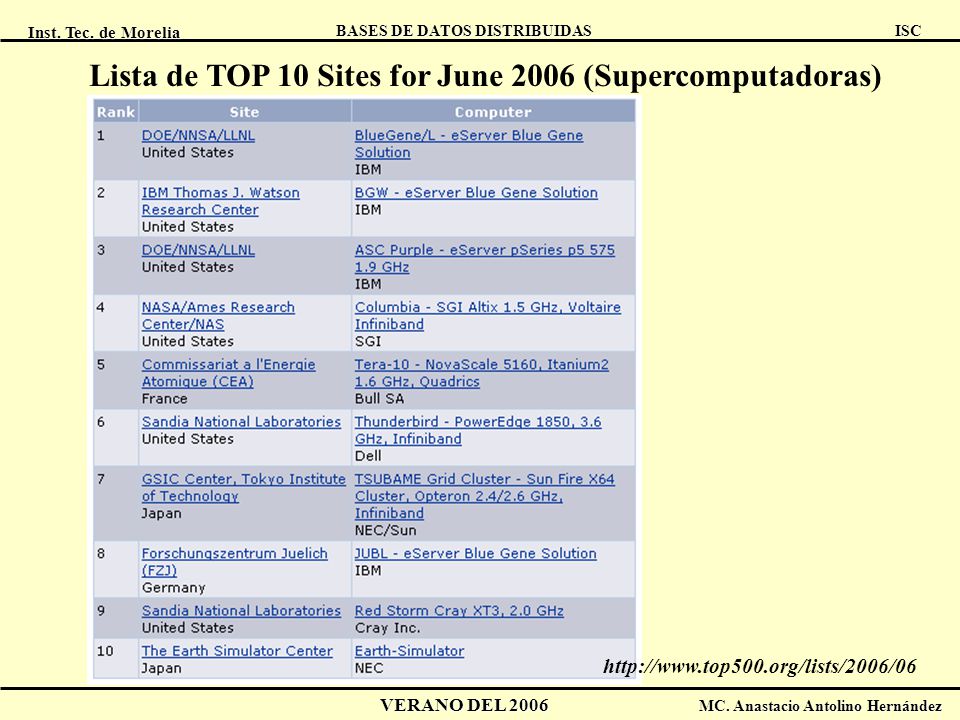
Lista de TOP 10 Sites for June 2006 (Supercomputadoras)
25
CRAY Y-MP4/464 Aspectos Físicos: La supercomputadora Cray se compone de varios gabinetes: El CPU Las unidades de disco La unidad de refrigeración Y la unidad de control de energía y refrigeración. El CPU ocupa un área de 1.5 m., pesa 2,450 kg. y mide 1.9 m. de altura.

26
CRAY Y-MP4/464 Características: El equipo instalado tiene 4 procesadores diseñados con capacidad para trabajar en paralelo y realizar operaciones matemáticas escalares o vectoriales. La memoria central del CPU es de 32 Megapalabras (1 palabra = 64 bits), además existe una memoria temporal (Buffer Memory) de 4 Mp (32MB). Ésta sirve como interfaz entre los procesadores y los subsistemas restantes del CPU.
, además existe una memoria temporal (Buffer Memory) de 4 Mp (32MB). Ésta sirve como interfaz entre los procesadores y los subsistemas restantes del CPU.")
27
CRAY-ORIGIN 2000 de Silicon Graphics
Sistema Operativo: El sistema operativo de CRAY es UNICOS 7.0., el cual está basado en UNIX. Dicho sistema operativo tiene capacidad de multiproceso y multiprogramación así como un sistema de archivos distribuido en diferentes unidades físicas. Características: 40 Procesadores MIPS RISC R bit a 195 MHZ. 10 Gb en memoria RAM. 171 Gb de espacio en disco. 13.6 GFlops pico (contra los 1.2 GFlops de la CRAY Y-P4/464).
.")
28
Una característica muy importante, es que este nuevo tipo de procesadores pertenecen a la tecnología CMOS. Los cuales requieren solamente enfriamiento por aire a 15 grados centígrados y no una compleja instalación de enfriamiento con Fluorinert. Como la que usa la actual supercomputadora, por lo cual el mantenimiento es mínimo.

29
Esta máquina es la supercomputadora más grande de América Latina y una de las más grandes del mundo.
Con lo que la UNAM vuelve a estar a la vanguardia de la tecnología como lo estuvo en la época en la que se adquirió la CRAY-YMP 4/464. Esta nueva supercomputadora estará muy pronto a la disposición de la comunidad universitaria, para el desarrollo de investigaciones de primer nivel.

30
BlueGene/L, Number 1 on the TOP500 list of supercomputers,
La BlueGene/L, es la número 1 en el TOP500 de la Lista de Supercomputadoras. Es revolucionaria, una máquina de bajo costo que entrega extraordinario poder de cómputo para simulaciones científicas y trabajo programático. La BlueGene/L se encuentra optimizada para ejecutar aplicaciones dinámicas moleculares a velocidades extremas.

31
Video de la Construcción de la BlueGene/L, Number 1 on the TOP500 list of supercomputers.

32
Casos de ejemplo: Consideremos un sistema paralelo con un cierto número de procesadores y discos que está ejecutando una aplicación de BD. Supóngase ahora que se incrementa el tamaño del sistema añadiéndole más procesadores, discos y otros componentes. El objetivo es realizar el procesamiento de la tarea en un tiempo inversamente proporcional al número de procesadores y discos del sistema.

33
Se dice que un sistema paralelo tiene una ganancia de velocidad lineal si la ganancia de velocidad es N, cuando el sistema cuenta con N veces más recursos (CPUs, Discos, etc.). Si la ganancia de velocidad es menor que N, se dice que el sistema tiene una ganancia de velocidad sublineal. Ganancia de velocidad lineal Ganancia de velocidad sublineal Velocidad Recursos

34
La ampliabilidad está relacionada con la capacidad para procesar tareas más largas en el mismo tiempo, mediante el incremento de los recursos del sistema. Si el tiempo utilizado para realizar una tarea N veces más grande es igual al tiempo utilizado en otra tarea normal, se dice que tiene una Ampliabilidad Lineal. Por el contrario, si el tiempo utilizado para realizar una tarea N veces más grande, es mayor al tiempo utilizado en otra tarea normal, se dice que el sistema tiene una Ampliabilida Sublineal.

35
Ampliabilidad lineal Ampliabilidad sublineal Tamaño del problema TP / TG El objetivo del paralelismo en los SBD suele ser asegurar que la ejecución del sistema continuará realizándose a una velocidad aceptable, incluso en el caso de que aumente el tamaño de la BD o el número de transacciones.

36
El incremento de la capacidad del sistema mediante el incremento del paralelismo proporciona a una empresa un modo de crecimiento más suave, que el de reemplazar un sistema centralizado. Al utilizar la Ampliabilidad deben atenderse los valores del rendimiento absoluto. Ya que una máquina con una ampliabilidad lineal puede tener un rendimiento más bajo que otra con ampliabilidad sublineal. Simplemente porque ésta última pueda ser mucho más rápida que la primera.

37
Existen algunos factores que trabajan en contra de la eficiencia del paralelismo y pueden atenuar tanto la ganancia de velocidad como la ampliabilidad: Costos de Inicio. El inicio de un único proceso lleva asociado un costo. En una operación paralela compuesta por miles de procesos el tiempo de inicio puede llegar a ser mucho mayor que el tiempo real de procesamiento, influyendo negativamente en la ganancia de velocidad. Interferencia. Los procesos que se ejecutan en un sistema paralelo pueden acceder con frecuencia a recursos compartidos, sufriendo retardos como consecuencia de la interferencia de cada nuevo proceso en la competencia con los procesos existentes por el acceso a los recursos más comunes (bús, disco duros, bloqueos, etc). Este fenómeno afecta tanto a la ganancia de velocidad como a la ampliabilidad.
. Este fenómeno afecta tanto a la ganancia de velocidad como a la ampliabilidad.")
38
Sesgo. El tiempo de servicio de una tarea completa vendrá determinado por el tiempo de servicio de la subtarea más lenta. Normalmente es difícil dividir una tarea en partes exactamente iguales, entonces se dice que la forma de distribución de los tamaños es sesgada. Por ejemplo, si se divide una tarea de tamaño de 100 en 10 partes y la división está sesgada, puede haber algunas tareas de tamaño menor que 10 y otras de tamaño superior.

39
COMPUTACIÓN DISTRIBUIDA

40
GRID COMPUTING La computación en Grid o en Malla es un nuevo paradigma de Computación Distribuida. En el cual todos los recursos de un número indeterminado de computadoras son englobados, para ser tratados como una única supercomputadora de manera transparente. Estas computadoras englobadas no están conectadas o enlazadas firmemente. Es decir, están débilmente acopladas.

41
GRID COMPUTING Es decir, no tienen porque estar en el mismo lugar geográfico. Se encuentran geográficamente distribuidas. Se puede tomar como ejemplo el proyecto En el cual trabajan computadoras alrededor de todo el planeta para buscar vida extraterrestre.

42
GRID COMPUTING La computación distribuida, computación en Parrilla o informática en Rejilla, es un nuevo modelo para resolver problemas de computación masiva. Utilizando un gran número de computadoras organizadas en racimos (o apiladas), incrustadas en una infraestructura de telecomunicaciones distribuida. El sistema Grid consiste en compartir recursos heterogéneos, basados en distintas plataformas, arquitecturas de equipos y programas, lenguajes de programación, etc.
, incrustadas en una infraestructura de telecomunicaciones distribuida. El sistema Grid consiste en compartir recursos heterogéneos, basados en distintas plataformas, arquitecturas de equipos y programas, lenguajes de programación, etc.")
43
GRID COMPUTING Y que se encuentren situados en distintos lugares y pertenecientes a diferentes dominios de administración, sobre una red que utiliza estándares abiertos. Dicho brevemente, consiste en virtualizar los recursos informáticos. El sistema Grid ha sido diseñado para resolver problemas demasiado grandes para cualquier simple Supercomputadora.

44
GRID COMPUTING Mientras se mantiene la flexibilidad de trabajar en múltiples problemas más pequeños. Por lo tanto, el sistema Grid es naturalmente un entorno multi-usuario. Por ello, las técnicas de autorización segura son esenciales, antes de permitir que los recursos informáticos sean controlados por usuarios remotos.

45
EJEMPLOS DE SISTEMAS GRID

46
Globus tiene recursos para manejar:
La herramienta Globus ha emergido como el estándar de facto para la capa intermedia (middleware) del Grid. Globus tiene recursos para manejar: La gestión de recursos (Protocolo de Gestión de Recursos en Grid, Grid Resource Management Protocol). Servicios de Información (Servicio de Descubrimiento y Monitorización, Monitoring and Discovery Service). Administración y Movimiento de Datos (Acceso Global al Almacenamiento Secundario, Global Access to secondary Storage y FTP en Grid, GridFTP).
 del Grid. Globus tiene recursos para manejar: La gestión de recursos (Protocolo de Gestión de Recursos en Grid, Grid Resource Management Protocol). Servicios de Información (Servicio de Descubrimiento y Monitorización, Monitoring and Discovery Service). Administración y Movimiento de Datos (Acceso Global al Almacenamiento Secundario, Global Access to secondary Storage y FTP en Grid, GridFTP).")
47
Globus La mayoría de Grids que se expanden sobre las comunidades académicas y de investigación, de Norteamérica y Europa, están basadas en las herramienta Globus Toolkit como núcleo de la capa intermedia. XML Los Servicios Web basados en XML, ofrecen una forma de acceder a diversos servicios/aplicaciones en un entorno distribuido.

48
XML Recientemente, el mundo de la informática en Grid y los Servicios Web caminan juntos para ofrecer el Grid como un Servicio Web. La arquitectura está definida por la Open Grid Services Architecture (OGSA). La versión 3.0 de Globus Toolkit, que actualmente se encuentra en fase Alfa, será una implementación de referencia acorde con el estándar OGSA.
. La versión 3.0 de Globus Toolkit, que actualmente se encuentra en fase Alfa, será una implementación de referencia acorde con el estándar OGSA.")
49
El Grid ofrece una forma de resolver grandes retos, como:
XML El Grid ofrece una forma de resolver grandes retos, como: El plegamiento de las proteínas y descubrimiento de medicamentos. Modelado financiero. Simulación de terremotos. Inundaciones. Y otras catástrofes naturales: Modelado del clima/tiempo, etc.

50
XML Ofrecen un camino para utilizar los recursos de las tecnologías de la información de forma óptima en una organización. COMPUTACIÓN DE CICLOS REDUNDANTES El modelo de computación de ciclos redundantes, también conocido como computación zombi, es el empleado por aplicaciones como

51
COMPUTACIÓN DE CICLOS REDUNDANTES
Consistente en que un servidor o grupo de servidores distribuyen trabajo de procesamiento a un grupo de computadoras voluntarias a ceder capacidad de procesamiento no utilizada. Básicamente, cuando dejamos nuestra computadora encendida, pero sin utilizarlo, la capacidad de procesamiento se desperdicia por lo general en algún protector de pantalla.

52
COMPUTACIÓN DE CICLOS REDUNDANTES
Este tipo de procesamiento distribuido utiliza nuestra computadora cuando nosotros no la necesitamos, aprovechando al máximo la capacidad de procesamiento. Al día de hoy, ya hay virus que utilizan esta misma técnica para hacer envíos de correo electrónico masivo (spam), desde servidores de todo el mundo, sin el conocimiento de los usuarios.
, desde servidores de todo el mundo, sin el conocimiento de los usuarios.")
53
CLUSTERING Otro método para crear sistemas de supercomputadoras es el clustering. Un cluster de computadoras consiste en un grupo de computadoras de relativo bajo costo, conectadas entre sí mediante un sistema de red de alta velocidad (Gigabit de Fibra Óptica, por lo general). Y un software que realiza la distribución de la carga de trabajo entre los equipos.
. Y un software que realiza la distribución de la carga de trabajo entre los equipos.")
54
CLUSTERING En un cluster todos los nodos se encuentran en el mismo lugar, conectados por una red local. Y de esta manera englobar todos lo recursos. En cambio en un Grid, no tienen porque estar en el mismo espacio geográfico, pueden estar en diferentes puntos del mundo. Por lo general, éste tipo de sistemas cuentan con un centro de almacenamiento de datos único.

55
SEGURIDAD El punto de la seguridad es delicado en este tipo de computación distribuida. Pues las conexiones se hacen de forma remota y no local. Podrían por lo tanto, surgir problemas para controlar el acceso a los otros nodos. Esto puede aprovecharse para un ataque de DoS, aunque la red no va a dejar de funcionar porque uno falle. Esa es una ventaja de este sistema Grid.

56
ARQUITECTURAS EN BASES DE DATOS

57
ARQUITECTURAS PARALELAS DE BASES DE DATOS
Existen varios modelos de arquitectura para las máquinas paralelas. Memoria Compartida. Todos los procesadores comparten una memoria común. P MEMORIA

58
Disco Compartido. Todos los procesadores comparten un conjunto de discos común. Algunas veces los sistemas de disco compartido se denominan agrupaciones. P M

59
Sin compartimiento. Los procesadores no comparten ni memoria ni disco duro.

60
Jerárquico. Este modelo es un híbrido de las arquitecturas anteriores.
P MEMORIA P MEMORIA P MEMORIA

61
Las técnicas utilizadas para acelerar el procesamiento de transacciones en sistemas servidores de datos, como: la caché de datos y bloqueos y la liberación de bloqueos. También se pueden utilizar en BD Paralelas de discos compartidos además de en BD Paralelas. De hecho estas técnicas, son muy importantes para el procesamiento eficiente de transacciones en tales sistemas

62
MEMORIA COMPARTIDA En una arquitectura de Memoria Compartida (M. C.) los procesadores y los discos tienen acceso a una memoria común (a través de un bus o de una red de interconexión). El beneficio de la memoria compartida es la extremada eficiencia en cuanto a la comunicación entre procesadores. Cualquier procesador puede acceder a los datos de la M. C. sin necesidad de la intervención del SW.
 los procesadores y los discos tienen acceso a una memoria común (a través de un bus o de una red de interconexión). El beneficio de la memoria compartida es la extremada eficiencia en cuanto a la comunicación entre procesadores. Cualquier procesador puede acceder a los datos de la M. C. sin necesidad de la intervención del SW.")
63
Un procesador puede enviar mensajes a otros procesadores utilizando escrituras en la M. C.
De modo que la velocidad de envío es mucho mayor (normalmente inferior a un microseg.) que la que alcanza un mecanismo de comunicación. El inconveniente de las máquinas con memoria compartida es que la arquitectura no puede ir más allá de 32 o 64 procesadores. Esto porque el bus o la red de interconexión se convertirían en un cuello de botella.
 que la que alcanza un mecanismo de comunicación. El inconveniente de las máquinas con memoria compartida es que la arquitectura no puede ir más allá de 32 o 64 procesadores. Esto porque el bus o la red de interconexión se convertirían en un cuello de botella.")
64
Llega un momento en el que no sirve de nada añadir más procesadores.
Ya que éstos emplean la mayoría de su tiempo esperando su turno para utilizar el bus y así poder acceder a la memoria. Una Solución: Las arquitecturas de M. C. suelen dotar a cada procesador de una memoria caché muy grande para evitar, siempre que sea posible, las referencias a la M. C. Problema: No obstante, en la caché no podrán estar todos los datos y no podrá evitarse el acceso a la M. C.

65
Además, las cachés necesitan mantener la coherencia.
Si un procesador realiza una escritura en una posición de memoria, los datos de dicha posición de memoria se deberían actualizar o eliminar de cualquier procesador donde estuvieran los datos en caché. El mantenimiento de la coherencia de la caché aumenta la sobrecarga cuando aumenta el número de procesadores. Por estas razones las máquinas con memoria compartida no pueden extenderse llegado un punto.

66
DISCO COMPARTIDO En el modelo de disco compartido todos los procesadores pueden acceder directamente a todos los discos a tráves de una red de interconexión, pero los proceadores tienen memoria privada. Estas arquitectura ofrecen dos ventajas respecto de las de M. C.

67
DISCO COMPARTIDO El bus de la memoria deja de ser un cuello de botella, ya que cada procesador dispone de memoria propia. Esta arquitectura ofrece una forma barata para proporcionar una cierta tolerancia ante fallos. Si falla un procesador (o su memoria) los demás procesadores pueden hacerse cargo de sus tareas. Ya que la base de datos reside en los discos, a los cuales tienen acceso todos los procesadores. La arquitectura de disco compartido tiene aceptación en bastantes aplicaciones.
 los demás procesadores pueden hacerse cargo de sus tareas. Ya que la base de datos reside en los discos, a los cuales tienen acceso todos los procesadores. La arquitectura de disco compartido tiene aceptación en bastantes aplicaciones.")
68
El problema principal de los sistemas de discos compartidos es la ampliabilidad.
Aunque el bus de la memoria no es cuello de botella muy grande, la interconexión con el subsistema de discos es ahora el nuevo cuello de botella. Esto es especialmente grave en situaciones en las que la BD realiza un gran número de acceso a los discos. Los sistemas de discos compartidos pueden soportar un mayor número de procesadores en comparación con los sistemas de M. C.

69
Pero la comunicación entre los procesadores es más lenta (hasta unos pocos milisegundos), ya que se realiza a través de una red de interconexión. Este sistema de discos compartidos fue desarrollado por DEC (ahora HP-Compaq). Y actualmente se encuentra soportado por Oracle, llamado Oracle Rdb.
. Y actualmente se encuentra soportado por Oracle, llamado Oracle Rdb.")
70
SIN COMPARTIMIENTO En un sistema de este tipo cada nodo del sistema consta de un procesador, memoria y uno o más discos. Los procesadores pueden comunicarse utilizando una red de interconexión de alta velocidad. Un nodo funciona como un servidor de los datos almacenados en los discos que posee. El modelo salva el inconveniente de requerir que todas las operaciones de E/S vayan a través de una única red.

71
Todas las referencias a los discos locales son servidas por los discos locales de cada procesador.
Solamente van por la red las peticiones, los accesos a discos remotos y las relaciones de resultados. Las arquitecturas sin compartimiento son más ampliables y pueden soportar con facilidad un gran número de procesadores. El principal inconveniente es el costo de comunicación y de acceso a discos remotos; esto porque necesita la intervención del SW en ambos extremos.

72
JERÁRQUICA La arquitectura jerárquica combina las características de las arquitectura de memoria compartida, de disco compartido y sin comportamiento. A alto nivel el sistema está formado por nodos que están interconectados mediante una red y no comparten ni memoria ni discos. Cada nodo del sistema podría ser en realidad un sistema de M. C. con algunos procesadores.

73
Alternativamente, cada nodo podría ser un sistema de disco compartido.
Y cada uno de estos sistemas de disco compartido podría ser un sistema de memoria compartida. De esta manera, un sistema podría construirse como una jerarquía con una arquitectura de M. C. con pocos procesadores en la base, en lo más alto una arquitectura sin compartimiento y quizá una arquitectura de disco compartido en medio. Los sistemas paralelos comerciales de BD se pueden ejecutar sobre varias de estas arqutecturas.

74
En las arquitecturas de Memoria Virtual Distribuida, hay una única M. C. desde el punto de vista lógico pero hay varios sistemas de memoria disjuntos desde el punto de vista físico. Estas arquitecturas han surgido como un intento por reducir la complejidad de programación de los sistemas jerárquicos. Se obtiene una única vista del área de memoria virtual de estas memorias disjuntas, mediante un HW de asignación de memoria virtual en conjunción con un SW extra.

75
Las velocidades de acceso son diferentes, dependiendo si la página está disponible localmente o no, esta arquitectura también se llama Arquitectura de Memoria No Uniforme (NUMA, NonUniform Memory Architecture).
.")
76
Principles Of Distributed Database Systems 2ª. Ed.
M. Tamer Ozsu y Patrick Valduriez Prentice Hall Fundamentos de Bases de Datos 4a. Edición Silberschatz, Korth y Sudarshan Mc Graw Hill Procesamiento de Bases de Datos 8a. Ed. David M. Kroenke Pearson. Introducción a los Sistemas de Bases de Datos 7a. Ed. C. J. Date Prentice Hall.

Presentaciones similares




 El Sistema de Gestión>")















