Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Introducción a la estadística Algunas definiciones de estadística
Ciencia de tomar decisiones en presencia de la incertidumbre. Freund, J. E. – Eallis y Roberts § Rama del conocimiento científico que se ocupa del análisis numérico e interpretación de los resultados que provienen de experimentos de naturaleza aleatoria. Capelletti, C. A. § Disciplina que investiga la posibilidad de extraer de los datos inferencias válidas, elaborando los métodos mediante los cuales pueden obtenerse dichas inferencias. Cramer, H. § Ciencia de tomar decisiones en base a observaciones. Sprowls, C. § Operación de análisis matemático que permite estudiar con el máximo de precisión los fenómenos no conocidos completamente. Mothes, J. § Disciplina que trata los problemas relativos a las características operatorias de las reglas de comportamiento inductivo, basadas en experimentos aleatorios. Neyman, J.

2
Introducción a la estadística
Estadística descriptiva. Estadística inferencial. Relación entre variables, de acuerdo a los distintos niveles de medición. Técnicas de análisis de asociación entre variables de distintos niveles de medición. Lógica de los test de hipótesis.

3
Sistema de Información Estadística
Un Sistema de Información Estadística “Conjunto de reglas, principios, métodos y actividades ordenadamente relacionados entre sí, que permiten observar y evaluar mediante mediciones periódicas o permanentes y desde un punto de vista cuantitativo, recursos, actividades, resultados y acciones realizadas dentro de un sector, una entidad o de un conjunto de sectores o de entidades ”.

4
Estadística Describir nuestro conjunto de datos: Características, valores atípicos, dispersión, tendencias para datos temporales. Descubrir patrones de comportamiento en los datos o ciertas relaciones entre las variables medidas. Intentar extrapolar la información contenida en la muestra a un conjunto mayor de datos. Inferir futuros comportamientos de la población estudiada (predicción)
")
5
Estadística: clasificaciones
Estadística descriptiva Estadística inferencial Estadística exploratoria Estadística multivariada Estadística no paramétrica

6
Niveles de medición Nominal: El valor de la variable indica solo la clase de pertenencia Ordinal: Las clases de pertenencia pueden ser ordenadas. Intervalo: El valor de la variable tiene un sentido y en general podremos (en al mayoría de los casos) calcular promedios, medidas de dispersión y aplicar test. Pero no siempre podremos establecer razones ente dos valores de la variable. Razón: Existe un cero absoluto, podemos efectuar cocientes de los valores de la variable.
 calcular promedios, medidas de dispersión y aplicar test. Pero no siempre podremos establecer razones ente dos valores de la variable. Razón: Existe un cero absoluto, podemos efectuar cocientes de los valores de la variable.")
7
Resumen de información
Estadísticos de posición o locación: ¿Donde esta ubicado nuestro conjunto de datos? Modo Mediana Media Estadísticos de dispersión Rango Coeficiente de variación

8
Distribución de frecuencias

9
Variables cuantitativas: medidas de posición
Modo. Mediana y percentiles Media: promedio de la variable El uso de estos estadisticos depende de los objetivos del analista o de las características de la población que se desea estudiar.

10
Histograma

11
Gráfico de dispersión

12
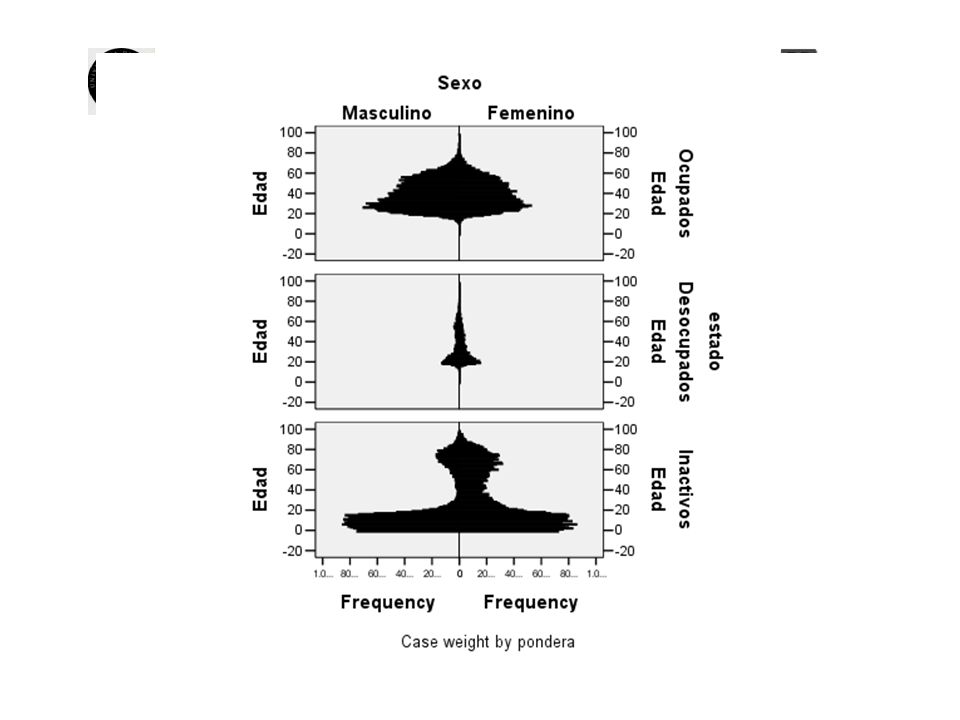
Pirámides de población

14
Variables simétricas

15
Variables Asimétricas

16
Medidas de asimetría La medida más usual de asimetría: “skewness”
Cuando se tiene variables asimétricas con valores positivos (ingreso por ejemplo), es usual tomar logaritmo para simetrizarlas.
, es usual tomar logaritmo para simetrizarlas.")
17
Box-Plot

18
Box-Plot: Horas trabajadas según sexo – Encuesta Permanente de Hogares

19
Ingreso ocupacion principal EPH 1998 GBA

20
Ingreso ocupación principal EPH 1998 GBA Sin cero

21
Relación entre dos variables nominales Tablas de contingencia Condicion de actividad por sexo – Fuente: EPH - INDEC

22
Relación entre dos variables nominales: Tablas de contingencia
Hipótesis nula: no existe asociación estadistica entre las dos variables, la distribución de los efectivos es proporcional a los “marginales”: totales fila y columna. Hipotesis alternativa: existe asociación estadística entre las variables

23
Tablas de contingencia Test de Chi – Cuadrado
Chi-cuadrado: Compara los efectivos teóricos (bajo el supuesto de independencia) con los observados. Efectivos teóricos en la celda (i,j):
 con los observados. Efectivos teóricos en la celda (i,j):")
24
Chi-cuadrado Si los observados son iguales a los teóricos, el coeficiente vale cero. El coeficiente aumenta al aumentar la discrepancia entre el observado y el teórico, respecto al valor teórico. Pero este coeficiente depende de n: Aumenta con el número de observaciones.

25
Chi-cuadrado normalizado - PHI
Se cumple que <=min(J-1, I-1)
")
26
V de Cramer Donde m = min(L-1, K-1) Se cumple que 0<=V<=1
 Se cumple que 0<=V<=1")
27
Ejercicio practico 1: Calcular el chi-cuadrado en la siguiente tabla
Variable X Variable Y C D A 20 B 12

28
Ejercicio practico 2: Calcular el chi-cuadrado y el V de Cramer en la siguiente tabla
Variable X Variable Y C D A 200 B 120

29
Asociación entre variables ordinales y cuantitativas: Coeficientes de correlación
Estos coeficientes reflejan en general el hecho de que una de las variables aumenta de valor cuando la otra lo hace. Los más utilizados: Coeficiente de correlación de Pearson (Karl Pearson, ) Coeficiente de correlación de Spearman (Charles Spearman, ( )
 Coeficiente de correlación de Spearman (Charles Spearman, ( )")
30
Coeficiente de correlación de Pearson entre dos variables X e Y
ρ = Cov(X, Y)/DS(X)*DS(Y) Variables continuas (de razón). Mide la existencia de una relación lineal entre las variables. -1 <= ρ <= 1 ρ =0 : ausencia de relación lineal ρ =1: relación lineal creciente ρ =-1: relación lineal decreciente Sensible a valores extremos o atípicos
/DS(X)*DS(Y) Variables continuas (de razón). Mide la existencia de una relación lineal entre las variables. -1 <= ρ <= 1. ρ =0 : ausencia de relación lineal. ρ =1: relación lineal creciente. ρ =-1: relación lineal decreciente. Sensible a valores extremos o atípicos.")
31
Coeficiente de correlación de Pearson: significado
El ρ de Pearson indica la existencia de una relación lineal entre X e Y. Identifica relaciones positivas y negativas. El coeficiente 0 indica ausencia de relacion estadística Puede haber una relación creciente, pero no lineal.

32
Ejercicio practico 3: Coeficiente de correlación de Pearson
Hallar el ρ de Pearson para la siguiente serie de valores. Graficarla con Excel. X Y 1 1 2 4 3 9 4 16

33
Coeficiente de correlación de Spearman entre dos variables X e Y
rs = ρ(rang(X), rang(Y)) Variables ordinales. Mide la existencia de una relación creciente o decreciente entre las variables. -1 <= ρ <= 1 ρ =0 : ausencia de relación creciente o decreciente ρ =1: relación creciente ρ =-1: relación decreciente Robusto a valores extremos o atípicos
, rang(Y)) Variables ordinales. Mide la existencia de una relación creciente o decreciente entre las variables. -1 <= ρ <= 1. ρ =0 : ausencia de relación creciente o decreciente. ρ =1: relación creciente. ρ =-1: relación decreciente. Robusto a valores extremos o atípicos.")
34
Coeficiente de correlación de Spearman entre dos variables X e Y
En caso de rangos “empatados”, tomamos el promedio de los rangos.

35
Ejercicio práctico 4: Asociación entre dos variable ordinales y cuantitativas
Dada el siguiente par de valores de dos variables, comprobar que el coeficiente de correlación de Spearman es el coeficiente de correlación de Pearson de los rangos . X Y 4 7 3 2 1 5

36
Recta de regresión Supongamos tener n obervaciones bivariadas, o sea a cada elemento le medimos un par de variables (Xi, Yi) que supondremos continuas por ahora. Peso y estatura. Producto Bruto Per capita y Tasa de mortalidad infantil. Tasa de desempleo y ingreso medio de los asalariados Cigarrillos fumados por día y probabilidad de sufrir cáncer de pulmón.
 que supondremos continuas por ahora. Peso y estatura. Producto Bruto Per capita y Tasa de mortalidad infantil. Tasa de desempleo y ingreso medio de los asalariados. Cigarrillos fumados por día y probabilidad de sufrir cáncer de pulmón.")
37
Recta de regresión: Ejemplo
En el siguiente gráfico se muestran los 8511 radios censales del Gran Buenos Aires. A cada radio se le midieron dos variables: % de hogares con celular y % de hogares con freezer, según datos del CENSO 2001. Los datos se graficaron mediante un gráfico X-Y. El eje de las X (horizontal) indica al % de hogares con freezer, el eje de las Y (vertical) el % de hogares con celular. Vemos que hay una relación aproximadamente lineal entre ambas variables, por lo menos en la parte central del gráfico.
 indica al % de hogares con freezer, el eje de las Y (vertical) el % de hogares con celular. Vemos que hay una relación aproximadamente lineal entre ambas variables, por lo menos en la parte central del gráfico.")
38
Nube de puntos y recta de regresión

39
Modelo de regresión La relación puede ser lineal solo en una parte del recorrido de las variables. Variable X: variable “independiente” o explicativa. Variable Y: variable “dependiente” o explicada. El modelo de regresión no implica “causalidad” (ej. Educación e Ingreso). El modelo de regresión puede tener más de una variable: explicativa: modelo de regresión múltiple.
. El modelo de regresión puede tener más de una variable: explicativa: modelo de regresión múltiple.")
40
Modelo de regresión: Forma general
El modelo subyacente en la regresión lineal (simple o múltiple) es que la variable dependientes una función lineal de las variables independientes: Y= 1+b1·X1+b2·X2+…bk·Xk + e. e es una variable aleatoria, pues no es razonable suponer una relación lineal exacta entre Y y X1,…, Xk Pero en promedio podemos suponer que e será igual a cero. e se denomina el término de errror. Es igual a la diferencia entre el valor observado y la recta de regresión.
 es que la variable dependientes una función lineal de las variables independientes: Y= 1+b1·X1+b2·X2+…bk·Xk + e. e es una variable aleatoria, pues no es razonable suponer una relación lineal exacta entre Y y X1,…, Xk. Pero en promedio podemos suponer que e será igual a cero. e se denomina el término de errror. Es igual a la diferencia entre el valor observado y la recta de regresión.")
41
Ajuste del modelo de regresión
Por ajuste del modelo de regresión se interpreta cuan bien la “nube de puntos” está cerca de la recta de regresión. El modelo de regresión tiene una medida de la “bondad de ajsute”: el R2. Este valor está entre 0 y 1. 1 -> Ajuste perfecto 0 -> No hay efecto de las variables independientes y la variable dependiente. No todos los modelos en estadística poseen una medida objetiva del “ajuste” de los datos al modelo.

42
Ajuste del modelo de regresión
Supongamos el modelo de regresión simple Y = a + b * X + e El “parámetro“ b indica cuánto aumenta Y por un aumento unitario de X. Si X no tiene efecto sobre Y, b valdrá 0.... a es la ordenada al origen.

43
Ajuste del modelo de regresión
Los paquetes estadísticos o Excel nos proveen estadísticos para evaluar el ajuste del modelo (R2). Y para evaluar si b es “significativamente distinto de cero” o no..... Si es “significativamente distinto de cero”, la variable independiente X tiene un efecto sobre Y.
. Y para evaluar si b es significativamente distinto de cero o no..... Si es significativamente distinto de cero , la variable independiente X tiene un efecto sobre Y.")
44
Ajuste del modelo de regresión
En general, si el tamaño de muestra es muy grande, los parámetros pueden ser “significativamente distintos de cero” a menudo. Esto no significa que sean relevantes para el investigador.

45
Recta de regresión: Cálculo de los parámetros
Para el ejemplo anterior son los 8511 radios censales, se plantea el modelo que explica a la variable CEL (% de celulares). Cel = a + b*Freezer + e Con el paquete Stata se calcularon los parámetros a y b. La salida es la siguiente:
. Cel = a + b*Freezer + e. Con el paquete Stata se calcularon los parámetros a y b. La salida es la siguiente:")
46
Modelo de regresión: Salida I
regress Cel Freez Number of obs = F( 1, 8509) = Prob > F = R-squared = Adj R-squared = Cel | Coef. Std. Err t P>|t| [95% Conf. Interval] Freez | _cons | O sea la recta de regresión es Cel = *Frezzer
 = Prob > F = R-squared = Adj R-squared = Cel | Coef. Std. Err. t P>|t| [95% Conf. Interval] Freez | _cons | O sea la recta de regresión es Cel = *Frezzer.")
47
Modelo de regresión: Salida II
Number of obs = F( 7, 418) = Prob > F = R-squared = t_desoc | Coef. Std. Er. t P>|t| [95% Conf.Int] t_activ | j_sipip | j_ucp | Cta_prop| Publico | Privado | Patron | _cons |
 = Prob > F = R-squared = t_desoc | Coef. Std. Er. t P>|t| [95% Conf.Int] t_activ | j_sipip | j_ucp | Cta_prop| Publico | Privado | Patron | _cons |")
48
Ajuste del modelo de regresión
Por ajuste del modelo se interpreta cuan bien los valores observados se ajustan a nuestro modelo. En el modelo de regresión lineal hay un estadístico, el R2 que nos indica la bondad del ajuste. R2 está comprendido entre 0 y 1. 1 indica un ajuste perfecto: todas las observaciones están sobre una recta.

49
Prueba de los coeficientes
Otra pregunta que el investigador se plantea es si algún coeficiente es igual a cero. O si es “significativamente distinto de cero”. Esta pregunta puede ser respondida mediante el estadístico t de Student. Cuanto más grade es t, mayor la probabilidad de que el coeficiente correspondiente sea igual a cero.

50
Análisis de los residuos
Luego está el análisis de los residuos observados: observaciones con residuos elevados en valor absoluto pueden indicar errores de medición, puntos extremos, o un modelo especificado incorrectamente. En general los paquetes estadísticos traen opciones para graficar los residuos y detectar aquellos con valores grandes. Finalmente, corresponde al investigador social interpretar si el modelo es plausible, que significan los parámetros, explicar el porquébuna observación tiene un residuo excesivamente grande, mantener o eliminar una variable.

51
Tipo de variables en el modelo de regresión lineal
El modelo de regresión se plantea en general cuando la variable dependiente (Y) es continua En teoría, las variables explicativas (X) pueden ser todas nominales (por ejemplo en un modelo que explique el ingreso sexo, tramo de edad, etc.). Cuando la variable a explicar (Y) no es continua, debemos aplicar otro modelo (Poisson, logit, etc)
 es continua. En teoría, las variables explicativas (X) pueden ser todas nominales (por ejemplo en un modelo que explique el ingreso sexo, tramo de edad, etc.). Cuando la variable a explicar (Y) no es continua, debemos aplicar otro modelo (Poisson, logit, etc)")
52
Ejercicio practico 4: Regresión lineal simple
Para los siguientes datos, calcular los coeficientes de regresión mediante el programa EXCEL. X Y 2 34 5 33 10 21 40 39

53
Ejercicio práctico 4:

54
Universo, población y muestra
Universo, población, muestra. Parámetros poblacionales. Estimación a partir de una muestra: Inferencia y estimadores. Propiedades de los estimadores.

Presentaciones similares