Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Técnicas Supervisadas Aproximación no paramétrica
Reconocimiento de Patrones 2003 Notas basadas en el curso Reconocimiento de Formas de F.Cortijo, Univ. de Granada y en el libro Pattern Clasification de Duda, Hart y Storck Parte del material se extrajo de las notas:Técnicas Supervisadas II: Aproximación no paramétrica de F.Cortijo, Univ. de Granada

2
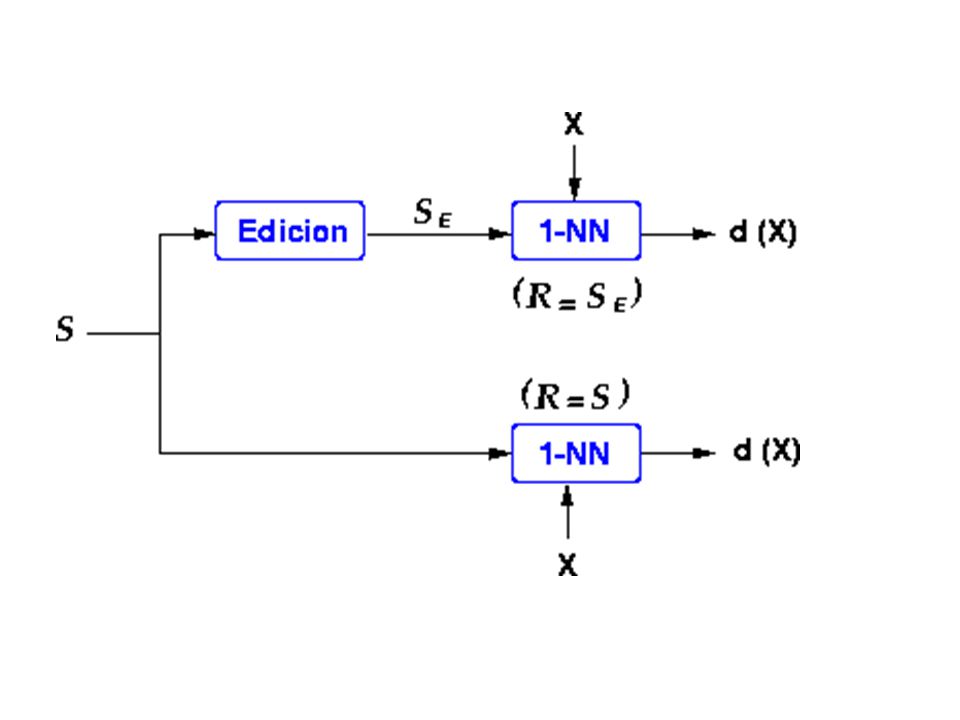
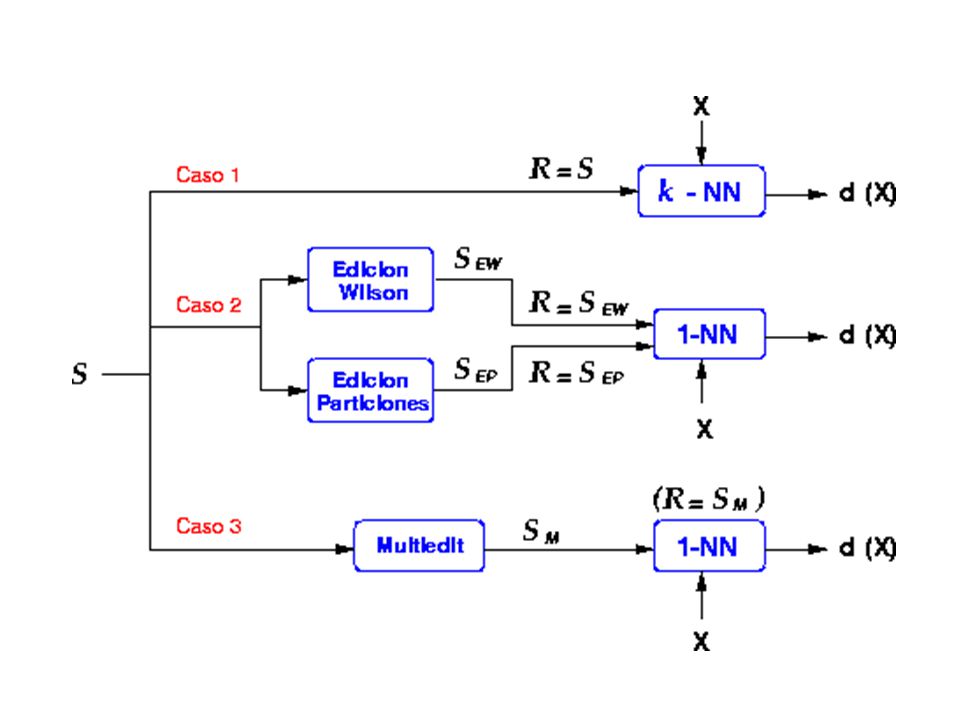
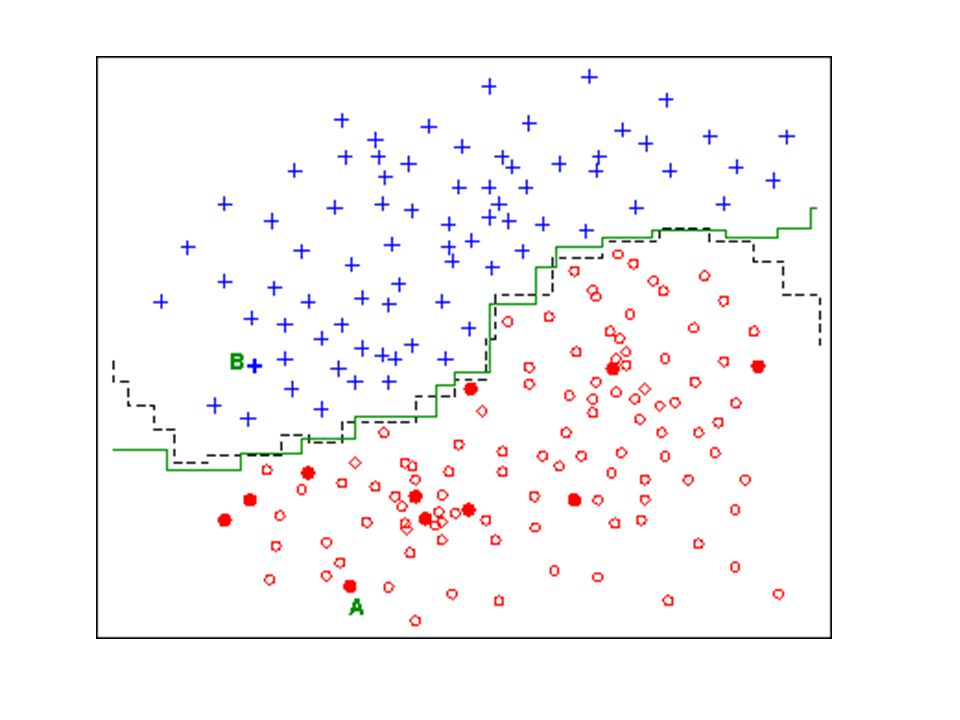
Edición del conjunto de entrenamiento
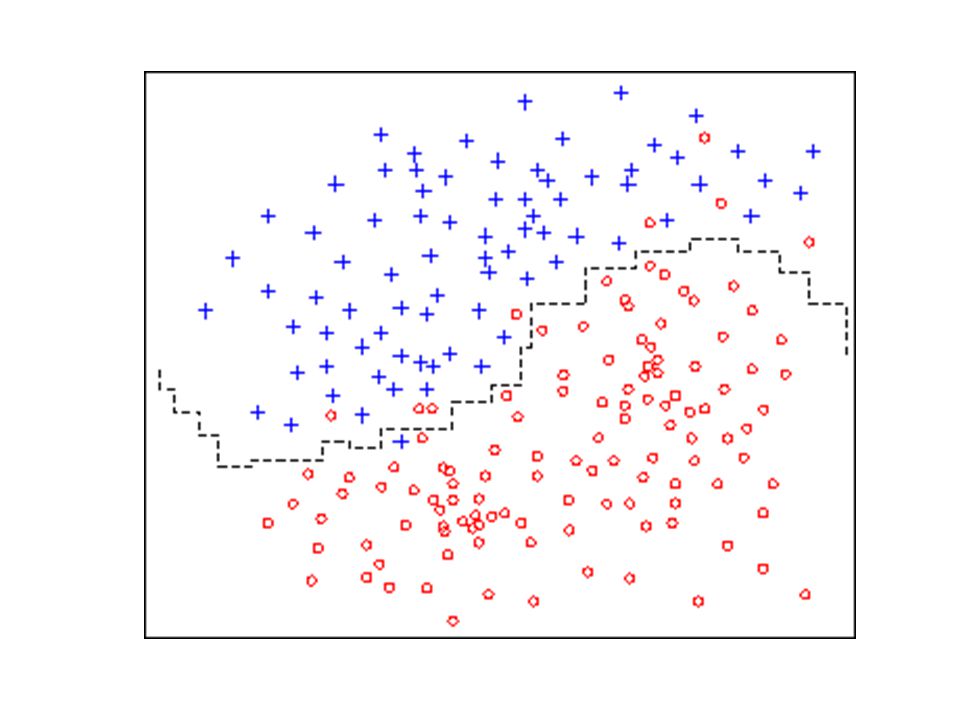
Objetivo: Reducir el conjunto de referencia Mejorar la “calidad” del mismo Eliminar outliers Para aumentar tasa de acierto de 1-NN

5
Edicion de Wilson Reduce prototipos problemáticos.
Genera dependencia estadística entre los prototipos retenidos (validación cruzada) Edicion con la regla k-NN
 Edicion con la regla k-NN.")
6
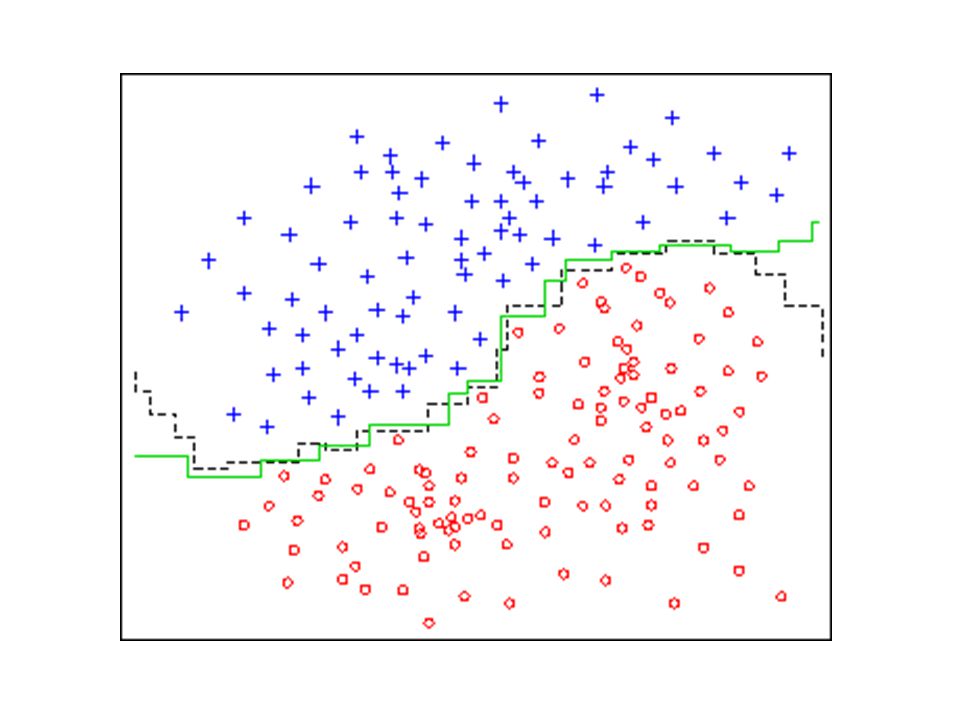
Edicion por particiones
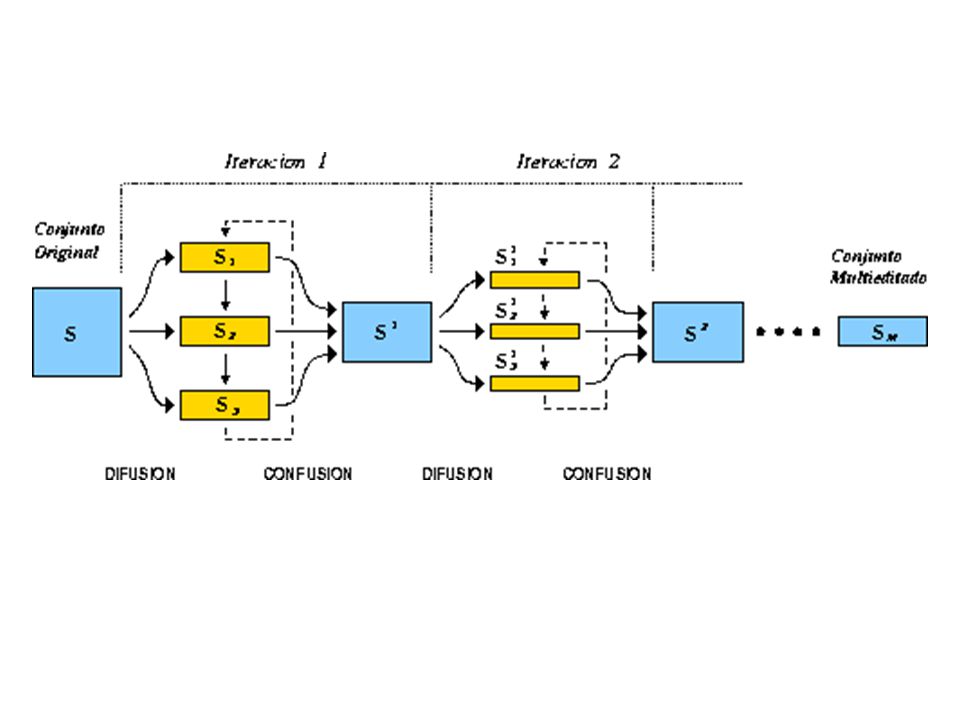
Realizo una partición del conjunto de entrenamiento. Aplico la regla k-NN a cada prototipo pero considerando los vecinos de una partición particular distinta a la del prototipo. Desempeño depende: Paso de difusión Partición inicial Regla k-NN

7
Edicion por particiones
Difusión: Ti generado por la partición de S Clasificación: prototipo usando como referencia otro conjunto diferente Edición: elimina el prototipo incorrectamente clasificado al terminar el proceso de clasificación Confusión: El conjunto de prototipos resultante contiene todos los que han sido correctamente clasificados

9
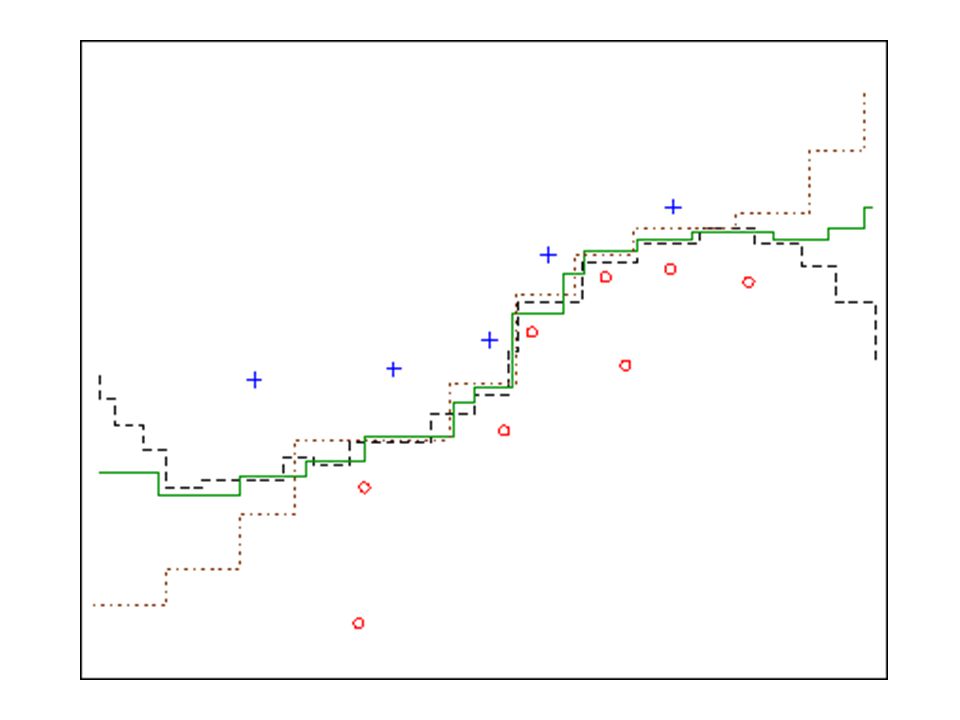
Multiedición Para evitar la dependencia respecto a la partición inicial se aplica en forma iterativa el método de edición por particiones. En cada iteración se genera una nueva partición del conjunto de prototipos que se mantienen sin editar. Edición con la regla 1-NN

16
Figura 33: Número de prototipos descartados por iteración.
Conjunto | S| iteraciones | SM| A1 6884 18 6653 A2 1027 8 734 Figura 33: Número de prototipos descartados por iteración. Paro cuando en I iteraciones no hay descartes.

18
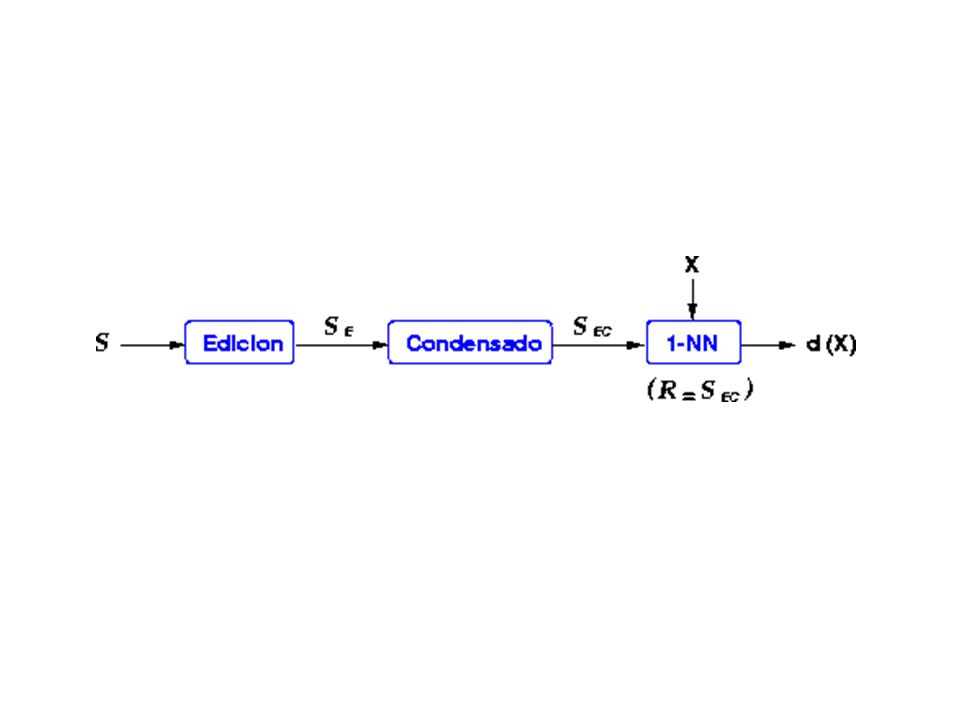
Reducción del coste computacional para los métodos del vecino más cercano
Objetivo: Incrementar eficacia computacional mediante la selección de un conjunto reducido y representativo del conjunto de prototipos Contrapartida: Genera ligera pérdida de bondad.

19
Métodos

20
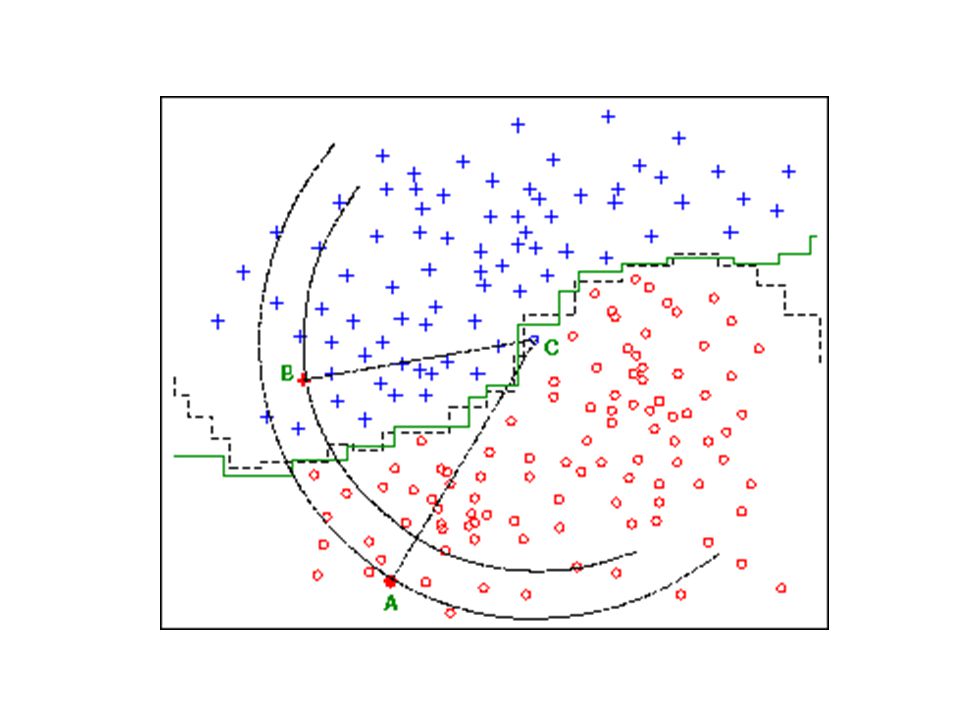
Condensado de Hart Idea:
Un conjunto SC se dice consistente respecto a otro conjunto S, donde SC S, si S puede clasificarse correctamente usando los elementos de SC como referencia. Selección de prototipos que determinen las fronteras de decisión Incremental sin vuelta atrás

27
Clase S SM SMC 1 3806 458 6 2 7542 267 4 3 5463 492 11 2796 34 5 8834 490 16 Total 28441 1741 39

29
Reducción del conjunto de referencia
Clase S SM SMC Total

30
Bondades de las clasificaciones 1-NN
Clase S SM SMC SC % % % % % 99.29% 98.58% 99.29% % 97.45% 96.43% 29.59% Bondad71.63% 98.57% 97.96% 71.43%

31
Condensado de Hart Requiere un conjunto previamente editado para asegurar la consistencia del conjunto condensado No proporciona un conjunto mininal, sólo un conjunto reducido Las fronteras de decisión no son tan buenas Conjunto condensado no es único depende de las condiciones iniciales.

32
Métodos de aprendizaje adaptativo
LVQ (Learning Vector Quantization) o aprendizaje por cuantificación vectorial, propuestos por Kohonen [E.3] DSM (Decision Surface Mapping) o construcción de superficies de decisión, propuesto por Geva y Sitte [E.2].
 o aprendizaje por cuantificación vectorial, propuestos por Kohonen [E.3] DSM (Decision Surface Mapping) o construcción de superficies de decisión, propuesto por Geva y Sitte [E.2].")
33
Métodos de aprendizaje adaptativo
Fija a priori la cantidad de prototipos del conjunto de aprendizaje resultante Np El conjunto resultante no tiene porque estar incluido en el conjunto Inicial. Heurística sencilla Rapidez de cálculo Dificultad para establecer valores adecuados de los parámetros.

34
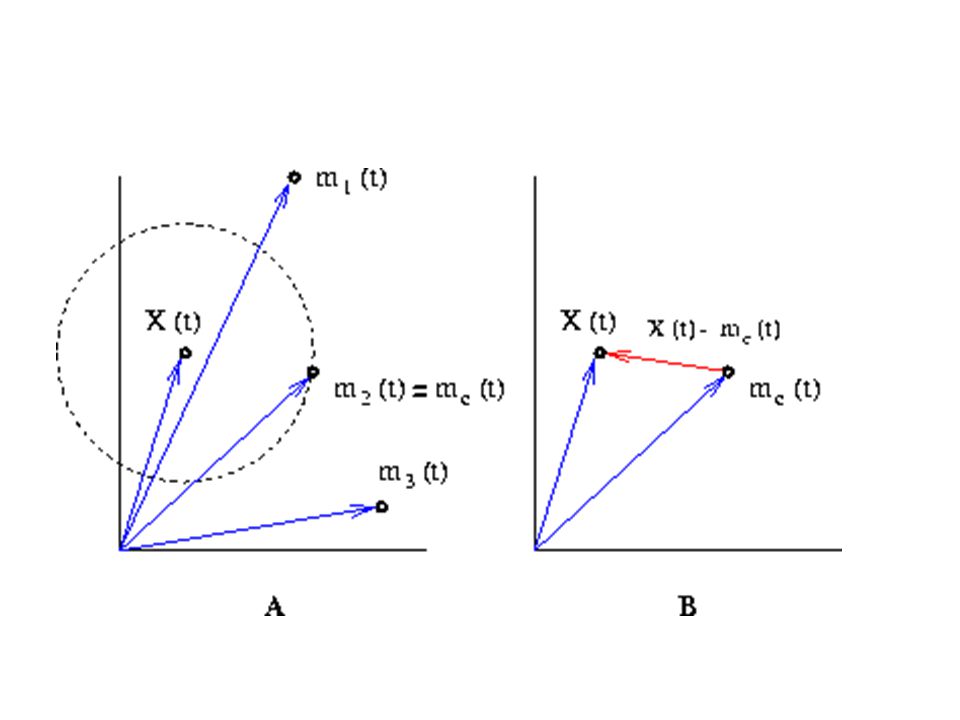
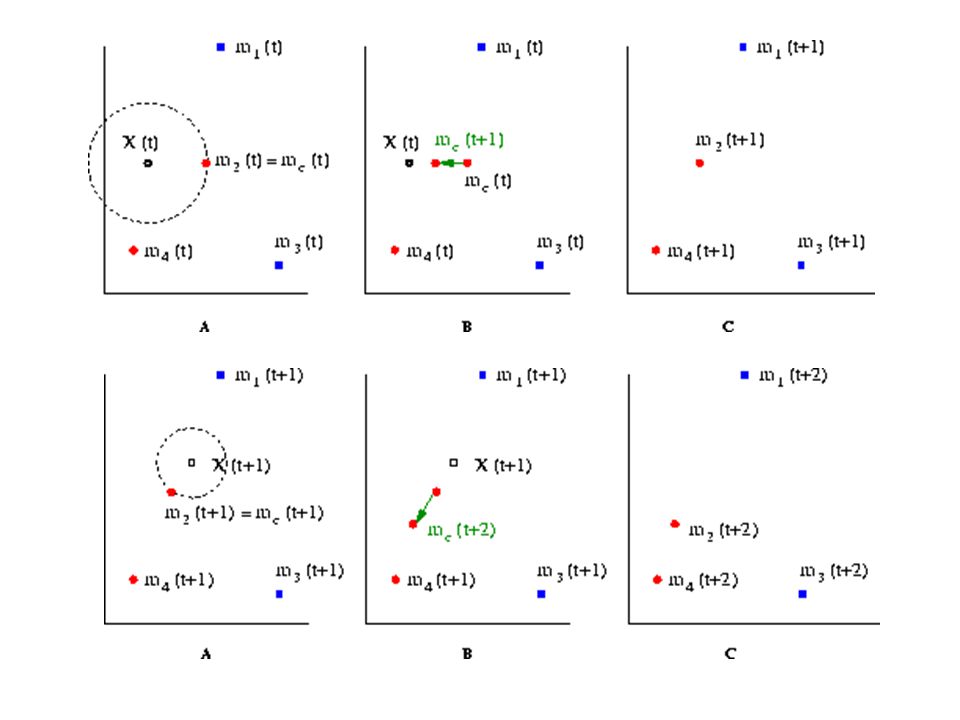
Aprendizaje competitivo y cuantificación vectorial
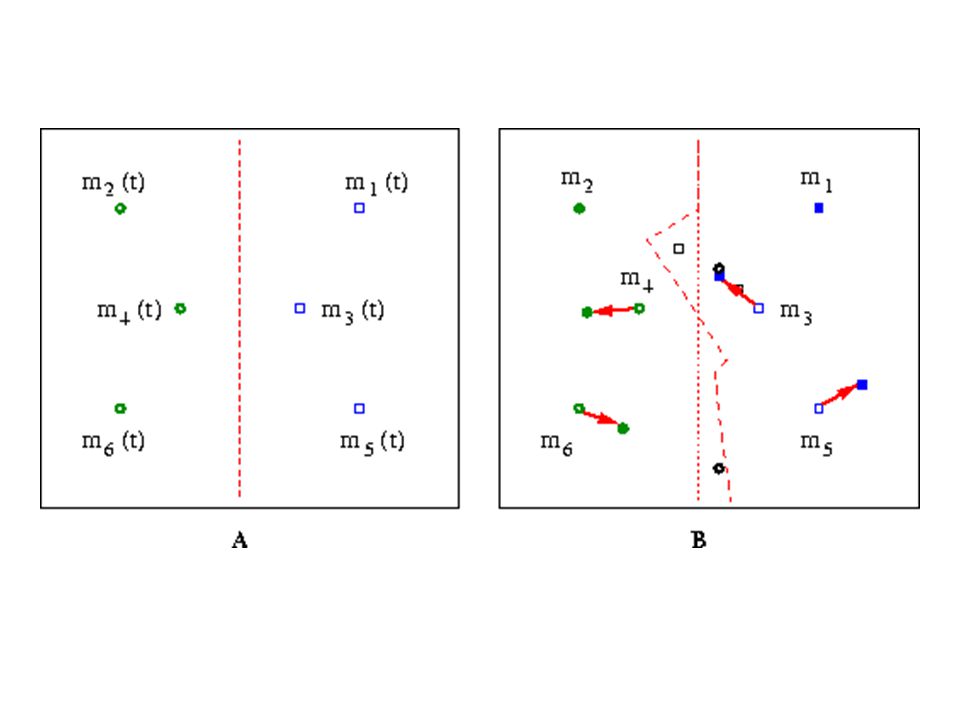
Sistema aprende de una secuencia de patrones: X = X(t) P, t = 1, 2,... 2. {mi(t) : mi(t) P, i = 1, 2,..., Np} Un conjunto fijo de vectores de referencia o prototipos modifican durante el aprendizaje. {mi(0), i = 1, 2,..., Np} ha sido inicializado de alguna forma. Actualizo mc(t) que mejor empareje con X(t) se
 P, t = 1, 2, {mi(t) : mi(t) P, i = 1, 2,..., Np} Un conjunto fijo de vectores de referencia o prototipos modifican durante el aprendizaje. {mi(0), i = 1, 2,..., Np} ha sido inicializado de alguna forma. Actualizo mc(t) que mejor empareje con X(t) se.")
36
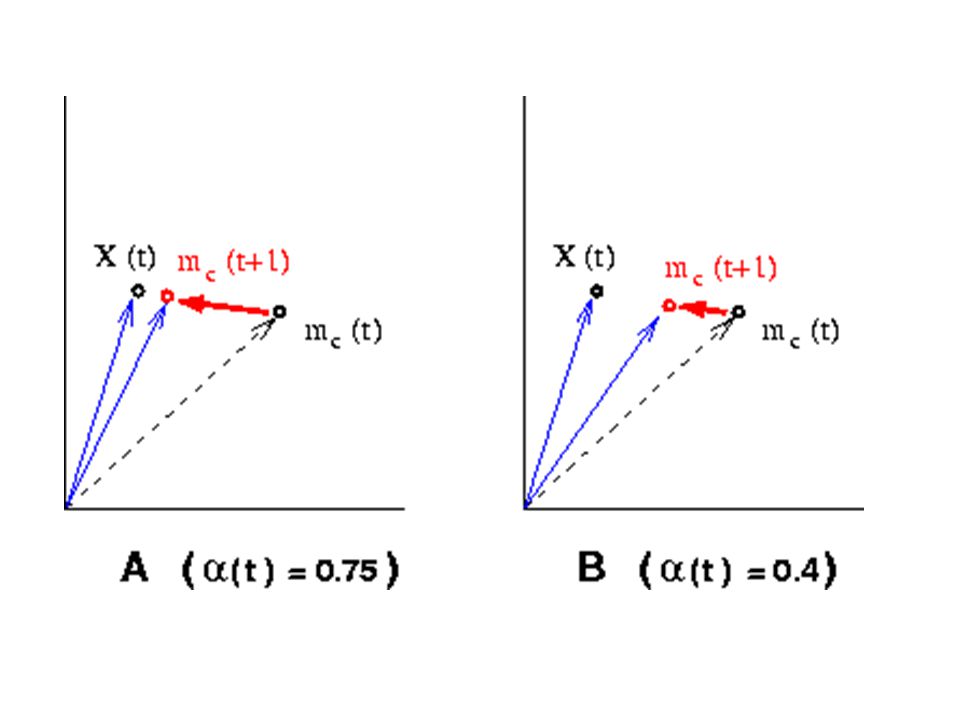
Cuantificación Vectorial
mc(t + 1) mc(t) + (t) [X(t) - mc(t)] mi(t + 1) mi(t) para i c (t) secuencia monótona decreciente de coeficientes escalares : 0 < (t) < 1
 mc(t) + (t) [X(t) - mc(t)] mi(t + 1) mi(t) para i c. (t) secuencia monótona decreciente de coeficientes escalares : 0 < (t) < 1.")
37
Función de Ganancia o Razón de Aprendizaje

39
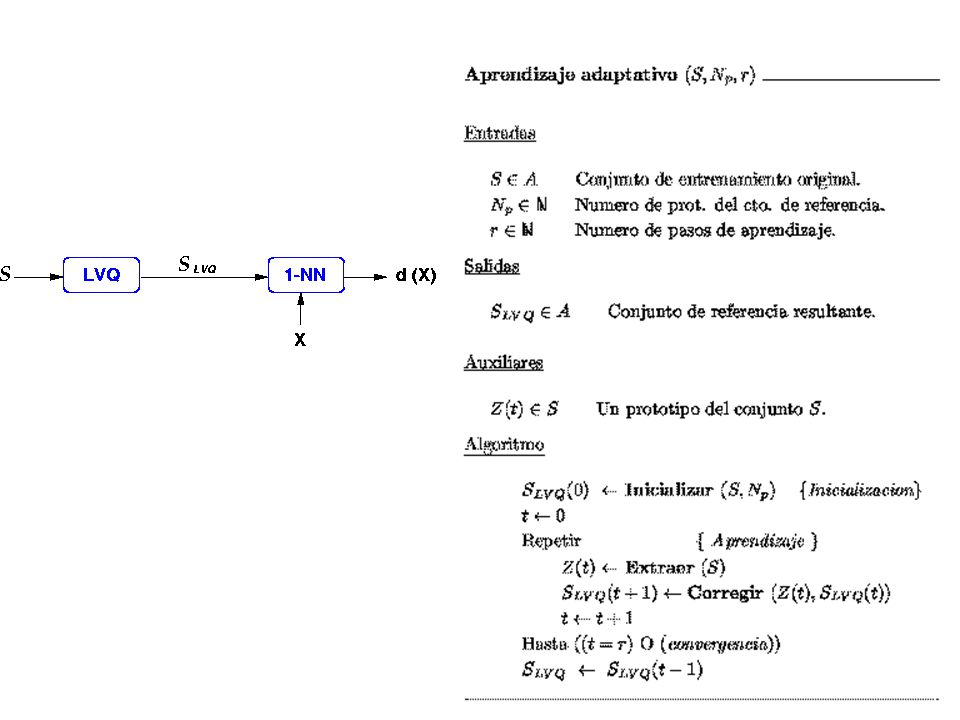
Aprendizaje por cuantificación vectorial (LVQ)
Inicialización : Determinación de Npi : Proporcional a Ni. Npi sea el mismo para todas las clases. Seleccionan los prototipos de SLVQ(0): Para cada clase, se procesan secuencialmente sus prototipos. Se añaden a SLVQ(0) si la clasificación k-NN es correcta.
: Para cada clase, se procesan secuencialmente sus prototipos. Se añaden a SLVQ(0) si la clasificación k-NN es correcta.")
40
Aprendizaje Método LVQ-1 SLVQ (0), SLVQ (1), ..., SLVQ(r - 1) = SLVQ
mj(t + 1) mj(t) + (t)[X(t) - m j(t)] {Premio a mj(t)} mi(t + 1) mi(t) - (t)[X(t) - mi(t)] {Castigo a mi(t)} Premio: Si la clase de mc(t), coincide con la X(t), Castigo: En otro caso, mc(t) se aleja de X(t).
 mj(t) + (t)[X(t) - m j(t)] {Premio a mj(t)} mi(t + 1) mi(t) - (t)[X(t) - mi(t)] {Castigo a mi(t)} Premio: Si la clase de mc(t), coincide con la X(t), Castigo: En otro caso, mc(t) se aleja de X(t).")
43
LQV-1 Tiende a mover los prototipos hacia prototipos de aprendizaje de su misma clase y a alejarlos de los de otra clase Recomendable fijar un valor peqeño para (0), bastante menor que 0.1 (0.02 ó 0.03). Número de pasos de aprendizaje es suficiente con presentar un número de prototipos 50 x Np < r < 200 x Np. No es tan importante el valor de r si el conjunto inicial es de buena calidad (previamente editado).
, bastante menor que 0.1 (0.02 ó 0.03). Número de pasos de aprendizaje es suficiente con presentar un número de prototipos. 50 x Np < r < 200 x Np. No es tan importante el valor de r si el conjunto inicial es de buena calidad (previamente editado).")
44
Método LVQ-1 Optimizado (OLVQ-1)
Positivo si (Clase (mc(t)) = Clase (X(t)). Negativo si (Clase (mc(t)) = Clase (X(t)). cmáx =0.3 30Np < r < 50Np (usualmente, r = 40Np). Se desestabiliza para valores altos de r
) = Clase (X(t)). Negativo si (Clase (mc(t)) = Clase (X(t)). cmáx = Np < r < 50Np (usualmente, r = 40Np). Se desestabiliza para valores altos de r.")
45
LVQ-2.1 valores bajos para (0)= 0.02 30Np < r < 200Np
Patrón modifica dos prototipos ( el más cercano de la misma clase y el más cercano de distinta clase) mj(t + 1) mj(t) + (t)[X(t) - m j(t)] {Premio a mj(t)} mi(t + 1) mi(t) - (t)[X(t) - mi(t)] {Castigo a mi(t)} valores bajos para (0)= 0.02 30Np < r < 200Np
 mj(t + 1) mj(t) + (t)[X(t) - m j(t)] {Premio a mj(t)} mi(t + 1) mi(t) - (t)[X(t) - mi(t)] {Castigo a mi(t)} valores bajos para (0)= Np < r < 200Np.")
46
LVQ-3 Modifica los dos patrones más cercanos:
Si mi y mj son de la distinta clase LVQ2.1 Si mi y mj son de misma clase: mi(t + 1) mi(t) +(t)[X(t) - mi(t)] mj(t + 1) mj(t) + (t)[X(t) - mj(t)] =[0.1, 0.5]
 mi(t) +(t)[X(t) - mi(t)] mj(t + 1) mj(t) + (t)[X(t) - mj(t)] =[0.1, 0.5]")
47
El desempeño es similar, idea: usar métodos con menos parámetros

48
Aprendizaje de superficies de decisión (DSM)
Se castiga al prototipo más cercano (el inductor del error). Se premia al prototipo más cercano de la misma clase que Z(t). mc(t + 1) mc(t) + (t)[X(t) - mc(t)] {Premio} mw(t + 1) mw(t) - (t)[X(t) - mw(t)] {Castigo}
. Se premia al prototipo más cercano de la misma clase que Z(t). mc(t + 1) mc(t) + (t)[X(t) - mc(t)] {Premio} mw(t + 1) mw(t) - (t)[X(t) - mw(t)] {Castigo}")
50
Tabla 11: Error de clasificación 1- NN para diferentes valores de Np
Np DSM LVQ-1

51
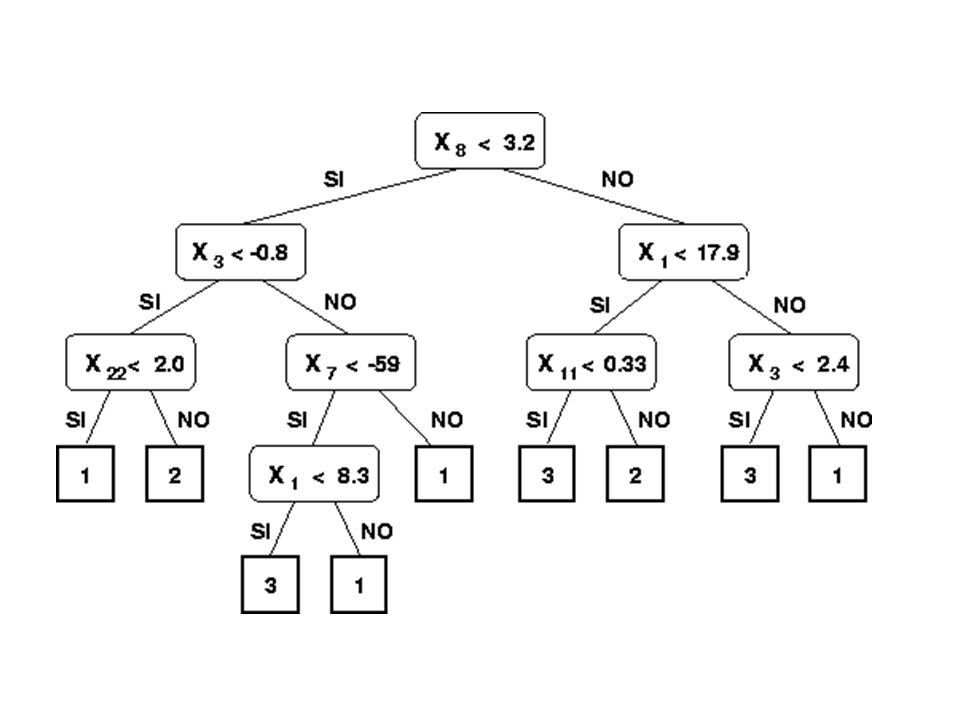
Arboles de Clasificación
Estructura resultante de la partición recursiva del espacio de representación Cada nodo interior contiene una pregunta sobre un atributo concreto Cada nodo hoja se refiere a una decisión (clasificación). CART (Classification And Regression Trees o árboles de clasificación y regresión),
. CART (Classification And Regression Trees o árboles de clasificación y regresión),")
53
Arboles de Clasificación
Aprendizaje. Construcción del árbol a partir de un conjunto de prototipos, S Clasificación. Preguntas sobre los valores de sus atributos, empezado por el nodo raíz y siguiendo el camino determinado por las respuestas a las preguntas de los nodos internos, hasta llegar a un nodo hoja. La etiqueta asignada a esta hoja es la que se asignará al patrón a clasificar

54
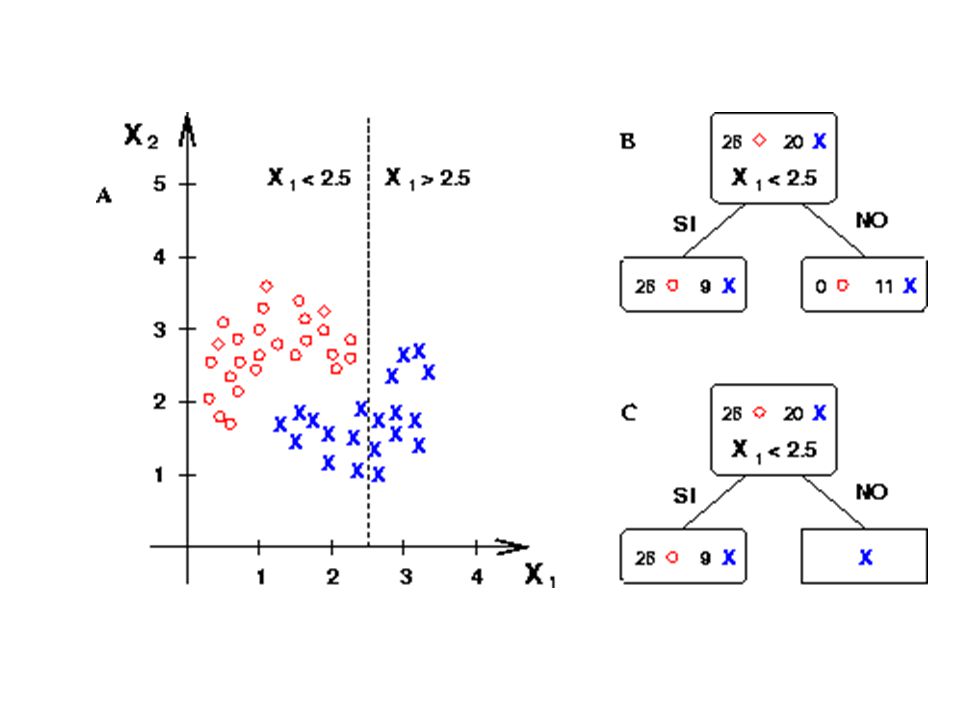
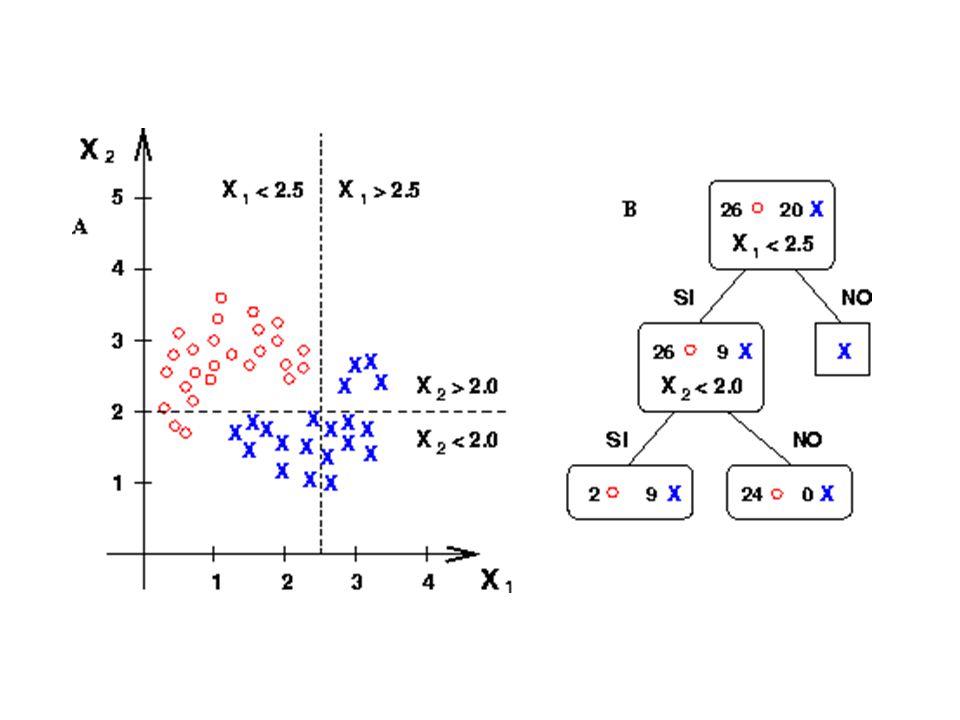
Construcción del árbol de clasificación
Nodo raiz- tiene a todos los prototipos Parto el nodo raiz: Para una carácterística eligo la mejor partición que separe a los prototipos en clases más puras. Realizo lo mismo para las otras caráctersticas Repito para los nodos hijos hasta llegar a condición de parada (nodo hoja). Los prototipos asociados a un nodo hoja agrupamiento homogéneo, al nodo se le asigna una etiqueta.
. Los prototipos asociados a un nodo hoja agrupamiento homogéneo, al nodo se le asigna una etiqueta.")
57
Selección de las particiones
¿De qué forma se hacen las particiones y se selecciona la mejor de entre las posibles en cada momento? objetivo de una partición: es incrementar la homogeneidad de los conjuntos resultantes que sean mas puros. medida de pureza

58
Criterios de partición
Función de impureza definida sobre J-uplas de la forma (c1, c2,..., cJ) tales que: a) cj 0 para j = 1, 2,..., J y b) cj = 1, max cuando (1/J, 1/J, 1/J,..., 1/J) min =0 cuando tengo una sola clase (1, 0, 0,..., 0) Función simétrica Medida de impureza de un nodo t: i(t) = ( p(1| t), p(2| t),..., p(J| t) ) p(j| t) =
 tales que: a) cj 0 para j = 1, 2,..., J y b) cj = 1, max cuando (1/J, 1/J, 1/J,..., 1/J) min =0 cuando tengo una sola clase (1, 0, 0,..., 0) Función simétrica. Medida de impureza de un nodo t: i(t) = ( p(1| t), p(2| t),..., p(J| t) ) p(j| t) =")
59
Bondad de una partición
bondad de la partición s en un nodo t, (s, t): decrecimiento en impureza (s, t) = i(s, t) = i(t) - pL i(tL) - pR i(tR)
: decrecimiento en impureza. (s, t) = i(s, t) = i(t) - pL i(tL) - pR i(tR)")
60
Impureza de un árbol I(T) = I(t) = i(t)p(t)
La selección continuada de las particiones que maximizan i(s, t) es equivalente a seleccionar las particiones que minimizan la impureza global I(T) Sumo en el conjunto de nodos terminales.
 es equivalente a seleccionar las particiones que minimizan la impureza global I(T) Sumo en el conjunto de nodos terminales.")
61
Criterios de medida de impureza
Medida de entropía. i(t) = - p(j| t) log p(j| t) Indice de Gini i(t) = p(i| t) p(j| t) = 1 - p(j| t)2 El clasificador no es muy sensible a la elección del criterio de impureza.
 = - p(j| t) log p(j| t) Indice de Gini. i(t) = p(i| t) p(j| t) = 1 - p(j| t)2. El clasificador no es muy sensible a la elección del criterio de impureza.")
62
Regla de asignación de clases
¿Cómo asignar una etiqueta a un nodo terminal? La clase más representada en ese nodo. j(t) = j si p (j| t) = {p (i| t)}
 = j si p (j| t) = {p (i| t)}")
63
Criterio de parada ¿Cual es el criterio para determinar que un nodo es homogéneo ? Basado en un criterio de poda, se construye un árbol muy grande y se poda hacia la raíz de manera adecuada. La poda permite eleiminar ramas en forma asimétrica, es más eficiente que detener el crecimiento.

64
T' es un subárbol podado de T
La estrategia de poda Particionar nodos hasta que se cumpla alguna de estas condiciones: a) que sea totalmente puro, o b)N(t) < Nmin (habitualmente Nmin = 5) T' es un subárbol podado de T Se asocia una medida de error a cada árbol de la secuencia y se escoge aquel que tenga asociado el menor error.
 que sea totalmente puro, o. b)N(t) < Nmin (habitualmente Nmin = 5) T es un subárbol podado de T. Se asocia una medida de error a cada árbol de la secuencia y se escoge aquel que tenga asociado el menor error.")
65
Poda por mínimo coste-complejidad
Complejidad de un subarbol como el número de nodos terminales, |T |. Error de clasificacion R(T). Medida de coste-complejidad : R (T) = R(T) + |T | 0:parámetro de complejidad R (T()) = {R (T)}
. Medida de coste-complejidad : R (T) = R(T) + |T | 0:parámetro de complejidad. R (T()) = {R (T)}")
66
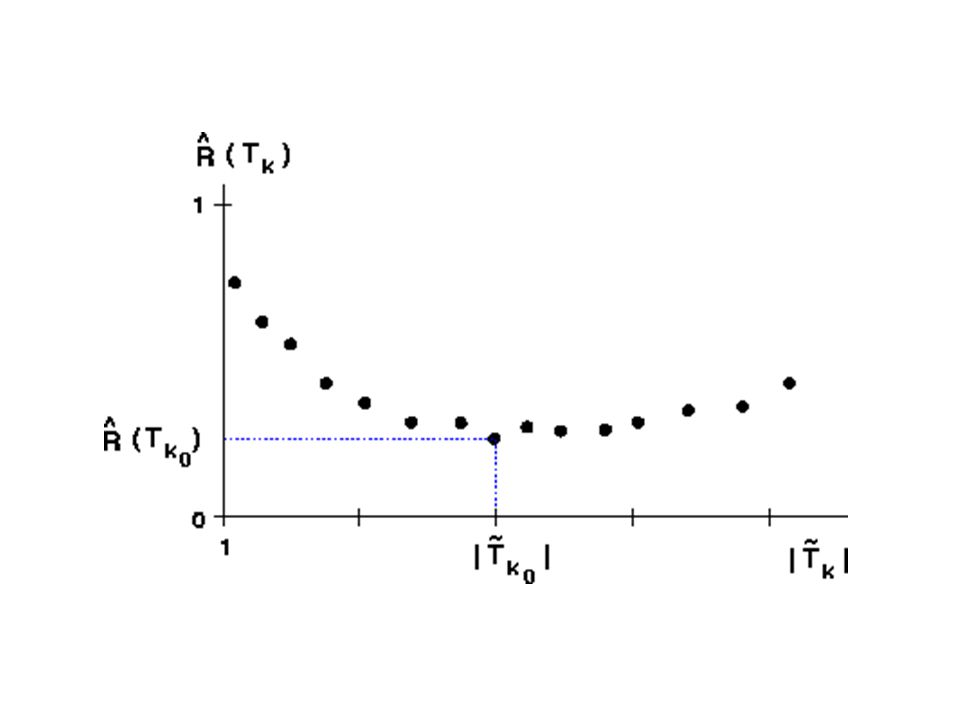
Selección del mejor árbol podado
Escoger aquel que tenga asociado el menor error R*(Tk) ¿cómo estimar honestamente R*(Tk)?. Estimación por conjunto de prueba Estimación por validación cruzada. La regla 1-SE: SE (Rts(T)) =
 ¿cómo estimar honestamente R*(Tk) . Estimación por conjunto de prueba. Estimación por validación cruzada. La regla 1-SE: SE (Rts(T)) =")
Presentaciones similares
















 Gastón Sabatelli (85523)>")

>")





