Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Parsing de Dependencias CoNLL 2006 y 2007 Guillermo Nebot Troyano

2
¿Qué es hacer Parsing de dependencias? Consiste en formar una estructura sintáctica para una oración identificando el HEAD (sólo uno) de cada palabra de la oración. Esto define el Grafo de Dependencia donde sus nodos son las palabras de la oración y los arcos son las relaciones de las palabras dependientes hacia su Head.
 de cada palabra de la oración. Esto define el Grafo de Dependencia donde sus nodos son las palabras de la oración y los arcos son las relaciones de las palabras dependientes hacia su Head..")
3
Ejemplo de Grafo de dependencias (1) 1De 7 2 aí 1 3 que 7 4 a 5 5 Cameron_Hall 6 6 tenha 0 7 caído 6 8 de 7 9 o 10 10 céu 8 11. 6 Unlabeled Parsing de Dependencias root tenha caído de aí quede cèu o Cameron_Hall. a

4
Ejemplo de Grafo de dependencias (2) 1De 7ADVL 2 aí 1P< 3 que 7FOC 4 a 5>N 5 Cameron_Hall 6 SUBJ 6 tenha 0STA 7 caído 6 MV 8 de 7ADVL 9 o 10>N 10 céu 8P< 11. 6PUNC Labeled Parsing de Dependencias root tenha caído de aí quede cèu o Cameron_Hall. a MV PUNC ADVL SUBJ FOC >N P< >N P<

5
Arco Proyectivo Definición: Un arco (i,j) es proyectivo si y sólo si todos los nodos entre i y j están dominados por i. Ejemplo:

6
Ejemplo de Arco No-Proyectivo

7
Proyectivo vs. No-Proyectivo Single vs. Multiple root

8
¿Porqué hacer Parsing de dependencias? Una de las ventajas del Parsing de dependencia, en comparación Parsing de constituyentes, es que se extiende de manera natural a los idiomas con orden de las palabras libre o flexible y en algunos idiomas el output se parece al del Parsing de constituyentes. Esto explica el interés actual para la evaluación multilingüe de los programas de Parsing de dependencias. Otra ventaja es que es más eficiente y rápido que el Parsing de constituyentes. También se puede usar para solucionar el problema WSD.

9
CoNLL 2006 La décima edición de CoNLL consistió en un shared task de Parsing de Dependencias Multilingüe. Los idiomas que se trataron fueron 13: Alemán, Árabe, Castellano, Checo, Chino, Danés, Esloveno, Holandés, Japonés, Portugués, Sueco, Turco y Búlgaro (opcional). Pertenecen a 7 familias de idiomas: Eslávica, Germánica, Japónica, Latina, Semítica, Sino-Tibetan y Ural-Altaica. Se presentaron 19 grupos de participantes.
. Pertenecen a 7 familias de idiomas: Eslávica, Germánica, Japónica, Latina, Semítica, Sino-Tibetan y Ural-Altaica. Se presentaron 19 grupos de participantes..")
10
CoNLL 2006 Para entrenar a los programas de análisis, Parsers, son necesarias recopilaciones sintácticamente anotadas, Treebanks, de millares de oraciones para cada idioma. Se establece un formato de los Treebanks estándar para todos los idiomas: ID, FORM, LEMMA, CPOSTAG, POSTAG, FEATS, HEAD, DEPREL, PHEAD, PDEPREL.

11
CoNLL 2006 Los Parsers fueron evaluados mediante labeled attachment score (LAS), es decir, el porcentaje de aciertos del HEAD y relación de dependencia (DEPREL) predichos por el Parser para los tokens. Los tokens de puntuación fueron excluidos de la evaluación.

12
Parser de McDonald (CoNLL 2006) Presentó un Parser de Dependencias multilingüe de dos etapas y lo evaluó en los 13 idiomas. La primera etapa se basa en Unlabeled Parsing de Dependencias. La segunda etapa toma el output de la primera y etiqueta todos los arcos del grafo de dependencia usando un clasificador.

13
Denotaremos por x = x 1,...,x n una frase de n palabras e y su grafo de dependencia correspondiente. El grafo de dependencia esta representado por parejas, donde x j es la palabra dependiente y x i es el Head. Cada arco se le puede asignar una etiqueta l (i,j) de un conjunto predefinido y finito L de etiquetas.
 de un conjunto predefinido y finito L de etiquetas..")
14
Etapa 1: Unlabeled Parsing Para la mayoría de los idiomas, la no-proyectividad es un fenómeno común. Tratar el Parsing de dependencias como una búsqueda del máximo scoring maximum spanning tree (MST) en un gráfico rinde algoritmos eficientes para los árboles proyectivos y no-proyectivos. Cuando se combinan con un algoritmo discriminativo que aprende online y con un conjunto rico de features, estos modelos proporcionan funcionamiento avanzado a través de idiomas múltiples.
 en un gráfico rinde algoritmos eficientes para los árboles proyectivos y no-proyectivos. Cuando se combinan con un algoritmo discriminativo que aprende online y con un conjunto rico de features, estos modelos proporcionan funcionamiento avanzado a través de idiomas múltiples..")
15
Maximum Spannig Tree (1) Primer Orden: Llamamos esta dependencia de primer orden puesto que los scores se restringen a un solo arco en el árbol de la dependencia. El problema MST es encontrar el grafo de dependencias G que maximice y satisfaga la restricción del árbol.

16
Maximum Spannig Tree (2) Segundo Orden: E stos modelos el score del árbol es la suma de los scores de pares adyacente de arcos., x i es el Head de x j y x k. Escribimos si x j es la primera o última palabra dependiente de x i. Si tenemos Entonces

17
Maximum Spannig Tree (3) El score de un árbol para el segundo orden que analiza ahora es: donde k y j son adyacentes, y dependientes de la misma i en el árbol y
 El score de un árbol para el segundo orden que analiza ahora es: donde k y j son adyacentes, y dependientes de la misma i en el árbol y")
18
Maximum Spannig Tree Proyectivo El algoritmo de primer orden puede extenderse al segundo orden (Eisner). Para el algoritmo de segundo orden, la clave está en retrasar el scoring de los arcos hasta que han recolectado a los pares de dependientes. Esto permite que la colección de pares dependientes adyacentes en una sola etapa, que permite la incorporación de las cuentas second-order (O(N 3 )).
)..")
19
Maximum Spannig Tree No-Proyectivo Desafortunadamente, MST no-proyectivo de segundo orden es NP-hard. Para evitar esto, diseñan un algoritmo aproximado basado en el algoritmo proyectivo de segundo orden exacto de Eisner. La aproximación busca primero el mayor scoring parser proyectivo. Entonces cambia los arcos en el árbol, uno a la vez, mientras tales cambios aumentan la cuenta total y no violan la restricción del árbol. Así, tenemos normalmente un número pequeño de transformaciones para el árbol no-proyectivo de mayor scoring.

20
Maximum Spannig Tree No-Proyectivo Podemos imponer M vueltas máximo en el while (sino tiempo exponencial). Es fácil ver que cada iteración del bucle es O(N 2 ), y por tanto, el algoritmo es O(N 3 +MN 2 ). En la práctica, la aproximación termina después de un número pequeño de transformaciones y no necesitaron limitar el número de iteraciones.
, y por tanto, el algoritmo es O(N 3 +MN 2 ). En la práctica, la aproximación termina después de un número pequeño de transformaciones y no necesitaron limitar el número de iteraciones..")
21
Etapa 2: Label Classifiaction (1) Versión 1 El más simple etiquetador debería tomar como input un arco (i, j) de la frase x y encontrar la etiqueta con mayor puntuación: Hacer esto para cada arco del grafo y produciría el output final. Tal modelo se podría entrenar fácilmente usando los datos de entrenamiento proporcionados para cada lengua.

22
Etapa 2 : Label Classifiaction (2) Versión 2 Sin embargo, puede ser que sea ventajoso saber las etiquetas de otros arcos próximos. Por ejemplo, sea x i es el Head de x j1,…,x jM, pasa a menudo que muchas de estas dependencias tienen etiquetas correlacionadas. Para modelar esto tratamos el etiquetado de los arcos (i,j 1 ),…,(i,j M ), como un problema de secuencia etiquetada,
,…,(i,j M ), como un problema de secuencia etiquetada,.")
23
Etapa 2 : Label Classifiaction (3) Usando una factoriazación de primer orden de Markov del score Podemos encontrar la secuencia con mayor score de la etiqueta con el algoritmo de Viterbi. Factorizaciones de mayor orden de Markov no mejoraron el funcionamiento. Usa MIRA (online learner) para calcular los pesos.
 para calcular los pesos..")
24
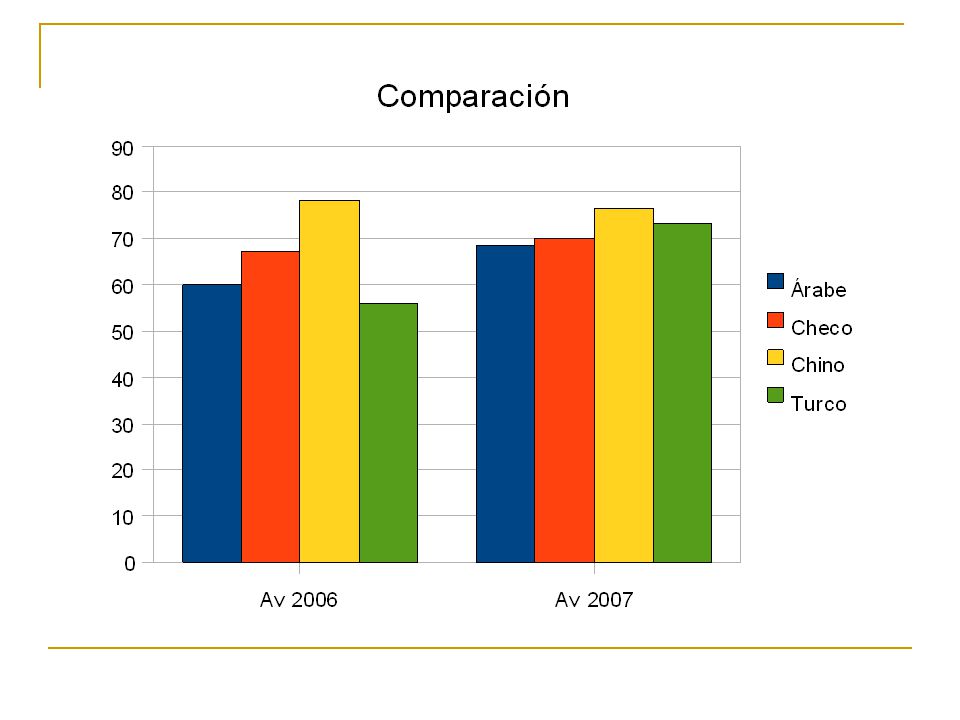
Resultados CoNLL 2006

25
CoNLL 2006

26
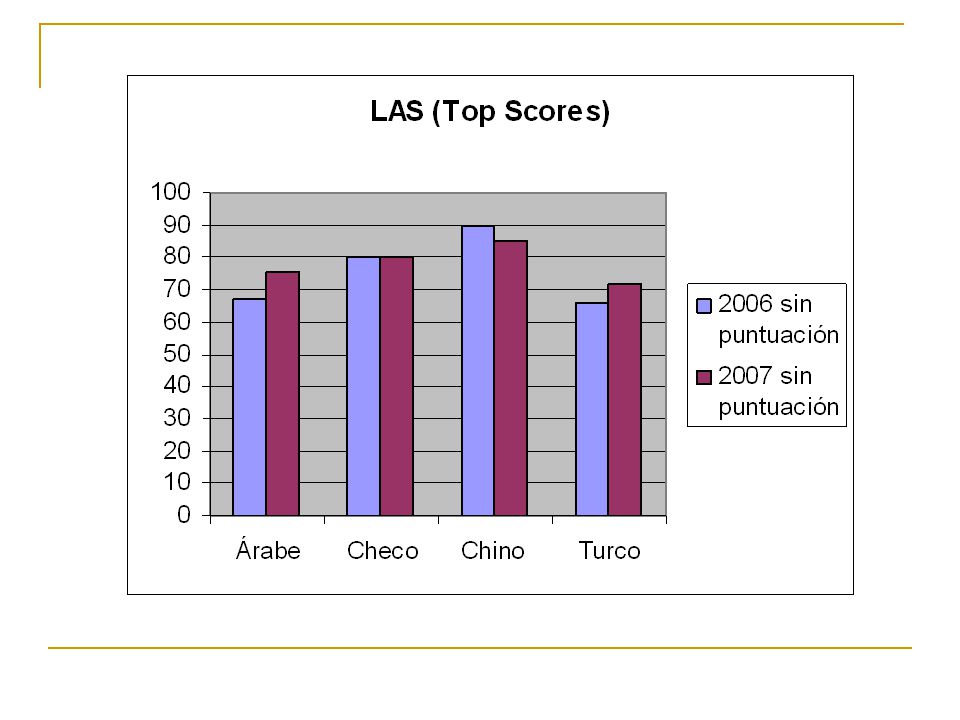
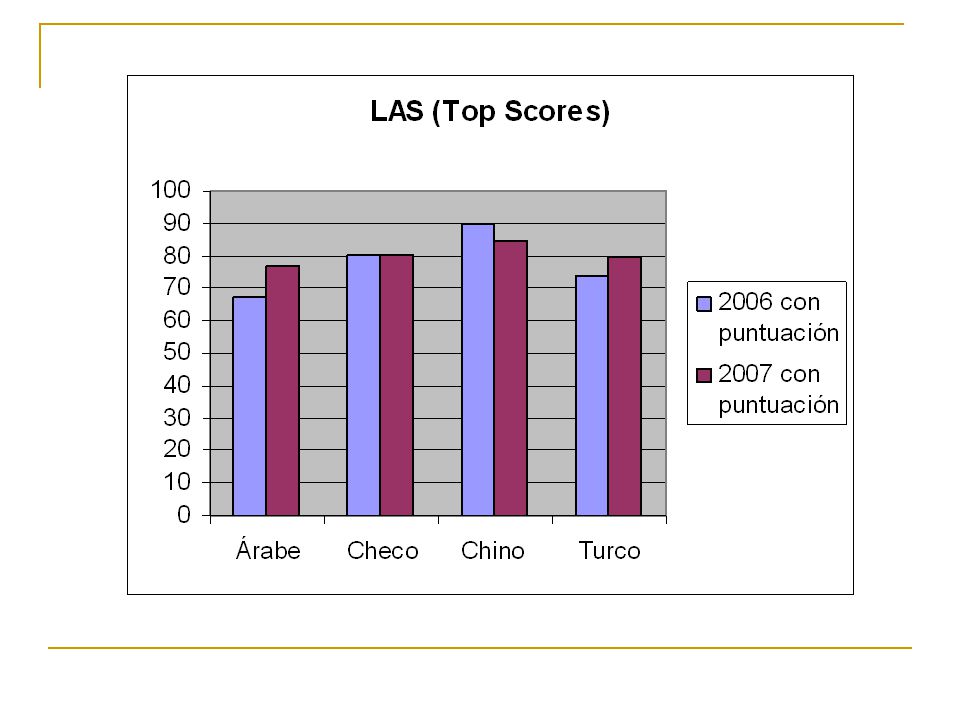
CoNLL 2006 (Conclusiones) En general, hay una alta correlación entre los mejores resultados y los resultados del promedio. Esto significa que los data sets son intrínsecamente fáciles o difíciles, sin importar el planteamiento de análisis. El "más fácil" es claramente el data set japonés. Sin embargo, sería incorrecto concluir de esto que el japonés en general es fácil de analizar. El “más difícil” es claramente el data set turco.

27
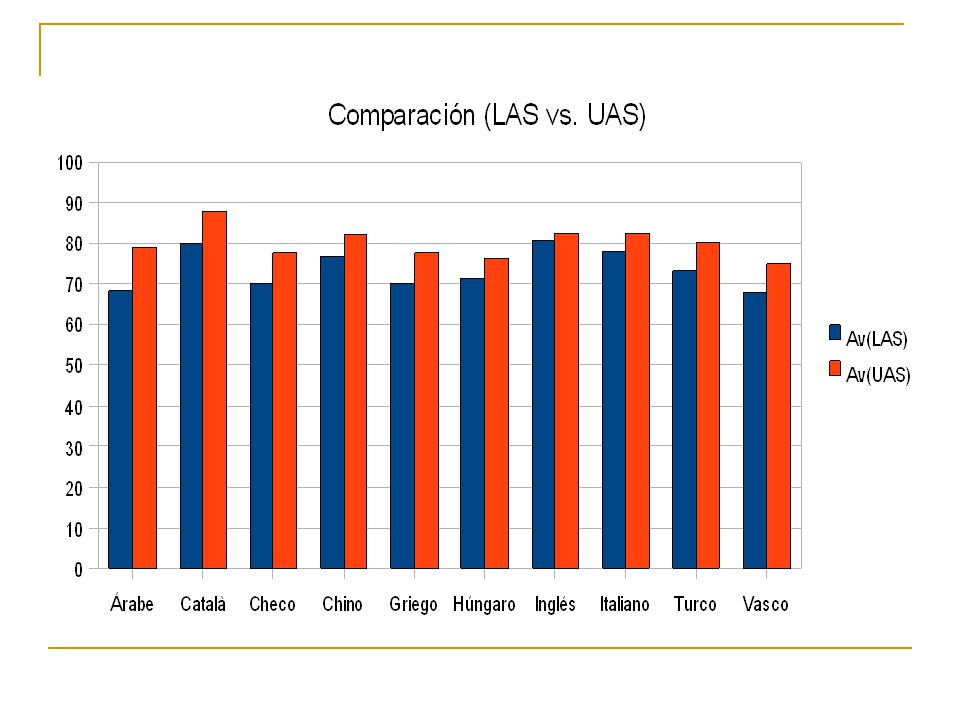
CoNLL 2007 En el shared task se presentaron dos cuestiones: 1. Parsing de Dependencias Multilingüe 2. Parsing de Dependencias de Adaptación del Dominio Comparten un mismo formato para los datos (el mismo que en 2006) y la métrica de evaluación oficial LAS (aunque también se dieron los resultados en unlabeled attachement score, UAS). Los tokens de puntuación este año si que fueron incluidos para la evaluación.
 y la métrica de evaluación oficial LAS (aunque también se dieron los resultados en unlabeled attachement score, UAS). Los tokens de puntuación este año si que fueron incluidos para la evaluación..")
28
1.Parsing de Dependencias Multilingüe Este año se trataron 10 idiomas y fueron: Árabe, Catalán, Checo, Chino, Griego, Húngaro, Inglés, Italiano, Turco y Vasco. Los Training Data Sets tenían entre 50.000 y 500.000 de tokens. Se presetaron 23 grupos de Participantes.

29
Parser de Nilsson (CoNLL 2007) Consiste en una optimización de dos etapas del sistema de MaltParser para los diez idiomas. La primera etapa consiste en encontrar un single-parser para cada lengua optimizando los parámetros (Single Malt) La segunda etapa consiste en un construir un sistema que combina el output de 6 parsers deterministas (variaciones del Single Malt), extrapolando los parámetros óptimos para cada lengua (Blended Parser) Este sistema supera perceptiblemente el single-parser y alcanza el promedio más alto con LAS en el CoNLL 2007.
 La segunda etapa consiste en un construir un sistema que combina el output de 6 parsers deterministas (variaciones del Single Malt), extrapolando los parámetros óptimos para cada lengua (Blended Parser) Este sistema supera perceptiblemente el single-parser y alcanza el promedio más alto con LAS en el CoNLL")
30
Single Malt Parser Los parámetros disponibles en el MaltParser se pueden dividir en tres grupos: parámetros del algoritmo de parsing. parámetros del modelo de features. parámetros del algoritmo de aprendizaje. La estrategia de optimización del Single Malt parser usada es: Definir un buen sistema base con los mismos ajustes del parámetro para todos los idiomas. Ajustar los parámetros del algoritmo de parsing de una vez por todas para cada lengua (con el sistema base). Optimizar el modelo de features y los parámetros del algoritmo de aprendizaje para cada lengua.
. Optimizar el modelo de features y los parámetros del algoritmo de aprendizaje para cada lengua..")
31
Algoritmo de Parsing (1) Usan el mismo algoritmo que en el Parser de Nivre del CoNLL 2006. El algoritmo construye un gráfico de dependencias con paso de izquierda a derecha sobre la entrada, usando una pila (stack) para almacenar tokens parcialmente procesados y agregando arcos usando cuatro acciones elementales: SHIFT: Pone next token en el stack. REDUCE: Elimina el top token del stack. RIGHT-ARC(r): Añade un arco etiquetado r del top token al next token; pone el next token en el stack. LEFT-ARC(r): Añade un arco etiquetado r del next token al top token y lo elimina del stack. El Parser deriva sólo gráficos proyectivos, el hecho de que los gráficos esten etiquetados permite que las dependencias no- proyectivas sean capturadas usando el algoritmo pseudo- proyectivo.
 para almacenar tokens parcialmente procesados y agregando arcos usando cuatro acciones elementales: SHIFT: Pone next token en el stack. REDUCE: Elimina el top token del stack. RIGHT-ARC(r): Añade un arco etiquetado r del top token al next token; pone el next token en el stack. LEFT-ARC(r): Añade un arco etiquetado r del next token al top token y lo elimina del stack. El Parser deriva sólo gráficos proyectivos, el hecho de que los gráficos esten etiquetados permite que las dependencias no- proyectivas sean capturadas usando el algoritmo pseudo- proyectivo..")
32
Algoritmo de Parsing (2) El algoritmo Pseudo-Proyectivo, proyectiviza los datos de entrenamiento con una transformación mínima, levantando arcos no-proyectivos y extendiendo la etiqueta del arco de los arcos “levantados” que usaban el esquema de codificación llamado HEAD. Las dependencias no-proyectivas se pueden recuperar aplicando la inversa de la transformación del output, usando la etiqueta extendida. Cuando el Parser se entrena en los datos transformados, aprenderá idealmente construir no sólo las estructuras proyectivas de la dependencia sino también asignar las etiquetas del arco que codifican la información sobre elevaciones.

33
Algoritmo de Parsing (3) Definimos: R={r 1,…,r m } el conjunto de todas las etiquetas de los arcos. Un grafo de dependencias para una frase W=w 1,…,w n es D=(W,A) donde W es el conjunto de nodos, A el conjunto de arcos etiquetados r(w i,w j ) y cumpliendo que para toda w j sólo tiene un único Head w i. El grafo D está bien formado si y solo si es acíclico y está conectado.
 donde W es el conjunto de nodos, A el conjunto de arcos etiquetados r(w i,w j ) y cumpliendo que para toda w j sólo tiene un único Head w i. El grafo D está bien formado si y solo si es acíclico y está conectado..")
34
Algoritmo de Parsing (4) D’=(W,A’) es el grafo de dependencia no-proyectivo de D=(W,A). La función SMALLEST-NONP-ARC da el arco no-proyectivo con la distancia más corta del Head al dependiente.

35
Algoritmo de Parsing (4)
 ")
36
Algoritmo de Parsing (5) Hay tres parámetros básicos a ajustar: Orden del arco: Usar arc-eager o arc- standard. La segunda versión se usó solo para el chino. Inicialización de la pila (Stack): En la versión base el parser tiene inicializada una nodo root artificial en la pila (agrega arcos de la raíz explícitamente) o es posible inicializar una stack vacío (agrega arcos de la raíz implícitamente). Con la pila vacía se reduce el nodeterminismo.
: En la versión base el parser tiene inicializada una nodo root artificial en la pila (agrega arcos de la raíz explícitamente) o es posible inicializar una stack vacío (agrega arcos de la raíz implícitamente). Con la pila vacía se reduce el nodeterminismo..")
37
Algoritmo de Parsing (6) Post-processing: El parser base realiza un solo paso de izquierda a derecha sobre el input pero es posible permitir un segundo paso donde solo se procesan los unattached tokens. Puesto que el algoritmo de Parsing produce sólo gráficos de dependencia proyectivos, podemos utilizar el análisis pseudo-proyectivos para recuperar dependencias no- proyectivas. Esto solo tuvo mejor rendimiento en el Checo, Griego, Turco y Vasco, ya que tienen más de un 20% de grafos no-proyectivos. Promedio de mejora tras la optimización del algoritmo de Parsing= 0.32%.

38
Modelo de Features (1) MaltParser utiliza un modelo basado en la historia del feature para predecir la acción siguiente del parsing. Cada feature de este modelo es un atributo de un token definida en la pila actual S, en la cola del input I o/y al gráfico parcialmente construido G de la dependencia, donde el feature puede ser cualquier de los atributos del formato de entrada CoNLL. La selección de features varia generalmente entre 20 y 30.

39
Modelo de Features (2) Usado por el modelo base de features
 Usado por el modelo base de features")
40
Algoritmo de Aprendizaje Los mejores resultados obtenidos con una SVM (usando el paquete LIBSVM). La SVM usa un kernel cuadrático LIBSVM está preparada para clasificación multiclase y convierte los features simbólicos en números (binarización). El modelo base usa γ=0.2 y r =0 para los parámetros del Kernel, C=0.5 de parámetro de penalización y ε=1.0 de criterio de parada. Tras aplicar las optimizaciones del Modelo de features y del algoritmo de aprendizaje obtuvieron un promedio de mejora 1.71%.
. El modelo base usa γ=0.2 y r =0 para los parámetros del Kernel, C=0.5 de parámetro de penalización y ε=1.0 de criterio de parada. Tras aplicar las optimizaciones del Modelo de features y del algoritmo de aprendizaje obtuvieron un promedio de mejora 1.71%..")
41
Blended Parser Dado los gráficos output de la dependencia de G i (i=1,..,6) de 6 parsers diferentes para una oración x, construimos un nuevo gráfico que maximiza: Donde es el promedio de LAS para el parser i para la clase c (usan CPOSTAG) de la palabra dependiente a, es 1 si, 0 en otro caso.
 de 6 parsers diferentes para una oración x, construimos un nuevo gráfico que maximiza: Donde es el promedio de LAS para el parser i para la clase c (usan CPOSTAG) de la palabra dependiente a, es 1 si, 0 en otro caso.")
42
Blended Parser El Blended parser final fue construido reusando el Single Malt parser ajustado para cada lengua (arcstandard left-to-right for Chinese, arc-eager left- toright para el resto de idiomas) y entrenando 5 parsers adicionales. Comparando los resultados de los dos sistemas, vemos que el Blended parser supera al Single Malt Parser en todos los idiomas, con una mejora media del 1.40%.

43
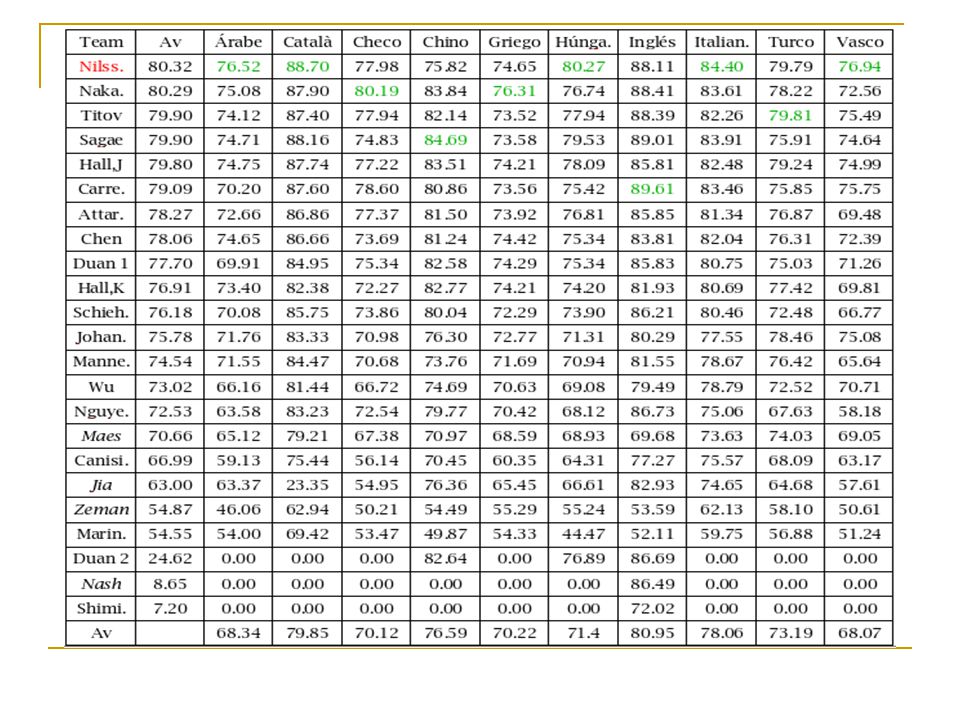
Resultados CoNLL 2007 (Multilingüe)
 ")
49
Conclusiones(Multilingüe) Con UAS se obtienen mejores resultados que con LAS. Se tiene una leve mejoría en los promedios de los resultados del 2007 con respecto de los del 2006. La diferencia entre el promedio para LAS entre el primero y quinto clasificado es menor de 0.5 puntos. El "más fácil" es claramente el data set inglés. El “más difícil” es el data set vasco.

50
2. Parsing de Dependencias de Adaptación del Dominio (1) El objetivo es adaptar el dominio fuente a un dominio target de interés. Solamente se usó el inglés para la adaptación. El corpus utilizado como dominio fuente fueron frases del Wall Street Journal y el dominio traget eran frases de archivos químicos. También hubo un segundo dominio target opcional, diálogos de ninños con sus padres. Se presentaron 10 grupos de Participantes.
 El objetivo es adaptar el dominio fuente a un dominio target de interés. Solamente se usó el inglés para la adaptación. El corpus utilizado como dominio fuente fueron frases del Wall Street Journal y el dominio traget eran frases de archivos químicos. También hubo un segundo dominio target opcional, diálogos de ninños con sus padres. Se presentaron 10 grupos de Participantes..")
51
Resultados de Adaptación del dominio

52
Conclusiones(Adaptación) El mejor sistema alcanza un LAS de 81.06%, es decir, pierde casi 8 puntos con respecto el LAS del multilingüe, 89.01%. Sabiendo que un tercio de las palabras del dominio químico de test son nuevas, los resultados son significativos. Una sorpresa se encontró en el UAS relativamente bajo para los datos de CHILDES, ya que en un primer vistazo, este data set tiene todas las características de un sistema fácil. Media de Palabras por frase=12.9 y porcentaje nuevas palabras bajo, 6.10%.

53
Referencias S.Buchholz and E.Marsi, 2006. CoNLL-X shared task on multilingual denpendency parsing. R.McDonald, K.Lerman, and F.Pereira, 2006. Multilingual dependency analysis with two-stage discriminative parser. R.McDonald and Pereira, 2006. Online learning of approximate dependency parsing algorithms. J.Nivre, 2005. Dependency grammar and dependency parsing. J.Nivre, J.Hall, J.Nilsson, G.Eryig ̆ it and S.Marinov, 2006. Labeled pseudo-projective dependency parsing with Support Vector Machines.

54
Referencias J.Nivre and J.Nilsson, 2005. Pseudo-projective dependency parsing. J.Nivre, J.Hall, S.Küber, R.McDonald, J.Nilsson, S.Riedel and D.Yuret, 2007. The CoNLL 2007 Shared Task on Dependency Parsing. J.Hall, J.Nilsson, J.Nivre, G.Eryig ̆ it, B.Megyesi, M.Nilsson and M.Saers, 2007a. Single malt or blended? A study in Multilingual Parser Optimization. J.Nivre, J.Hall, J.Nilsson, A.Chanev, G.Eryig ̆ it, S.Kübler, S.Marinov and E.Marsi, 2007. MaltParser: A language-independent system for data-driven dependency parsing.

Presentaciones similares