Descargar la presentación
La descarga está en progreso. Por favor, espere

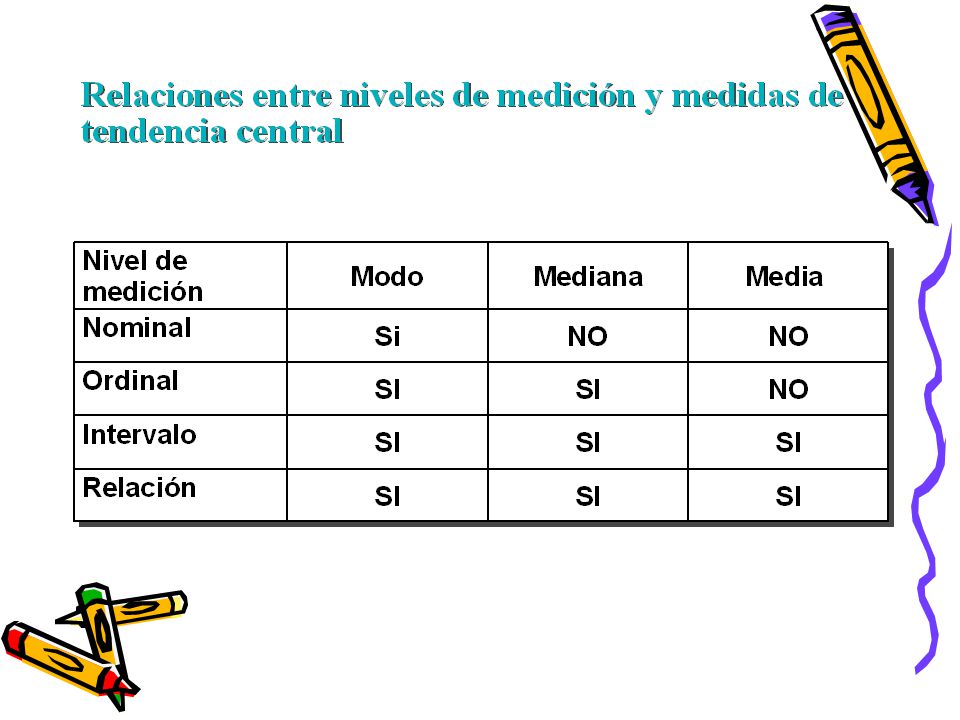
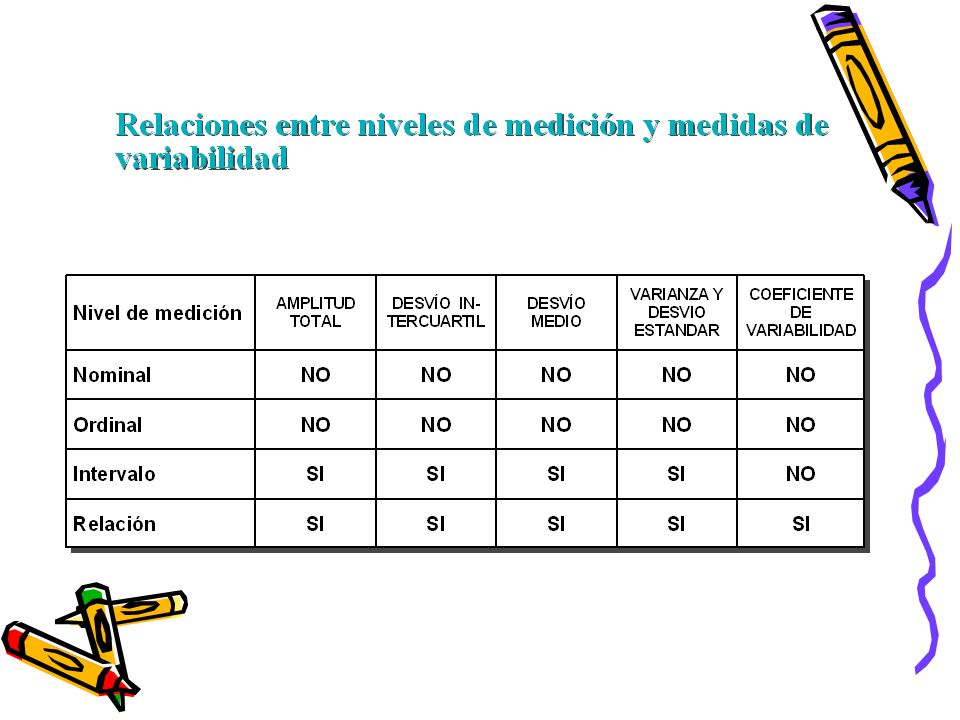
1
METODOLOGÍA DE LA INVESTIGACIÓN
INVESTIGACIÓN CUANTITATIVA: ESTADÍSTICA

9
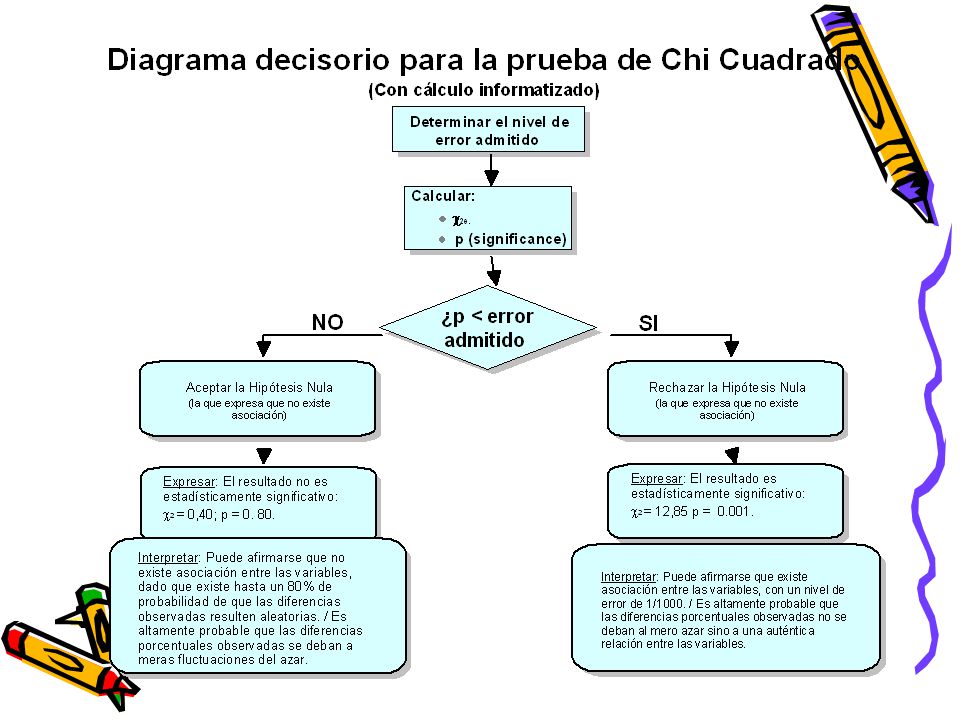
Elementos básicos de la Prueba de Asociación de Chi cuadrado

10
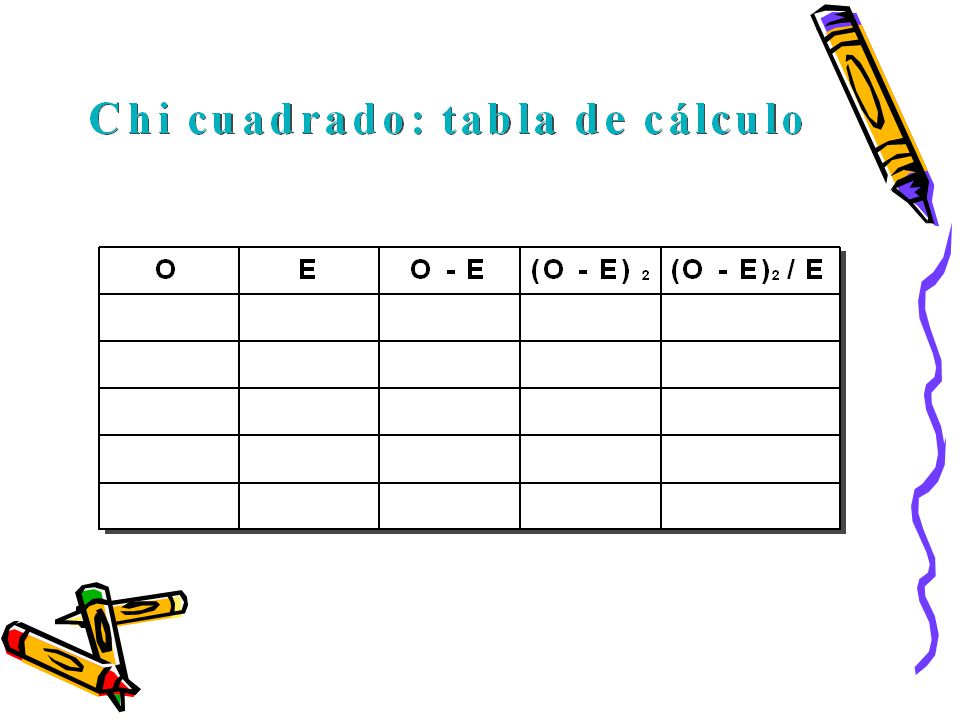
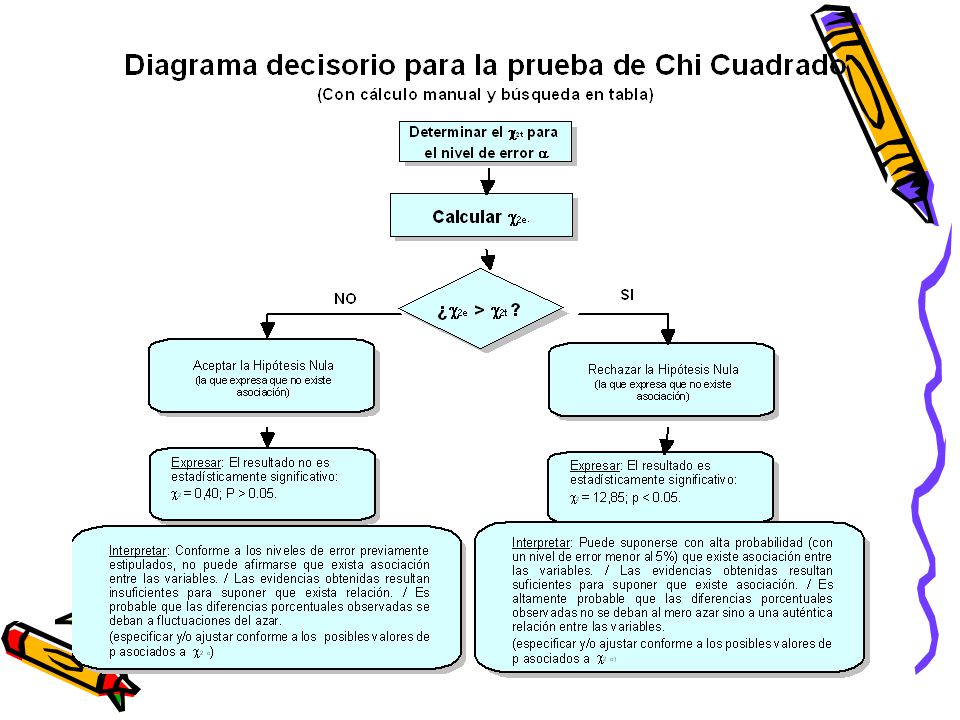
c2 S = ( o - e ) e Chi cuadrado Chi cuadrado 2 Es una medida de
asociación entre dos variables medidas en un nivel nominal u ordinal. Específicamente informa sobre el grado de probabilidad de que exista asociación. Conceptualmente, consiste en comparar las frecuencias efectivamente observadas con las frecuencias que deberían esperarse si no existiera asociación entre las variables. Cuanto mayor sea la diferencia entre lo observado y lo esperado, mayor resultará la probabilidad de que exista asociación. c2 ( 2 S o - e ) = e
 = e.")
12
f = c n Coeficiente Phi Coeficiente Phi 2
Medida de asociación basada en chi cuadrado. Se obtiene al dividir el valor de chi cuadrado por el número de casos y, luego, extraer la raíz cuadrada del resultado. Informa sobre el grado o fuerza de la asociación entre dos variables de nivel no cuantitativo (nominal u ordinal) Cuando se trata de tablas de contingencia de 2 X 2, phi asume valores comprendidos entre 0 y 1. f c 2 = n
 Cuando. se. trata. de. tablas. de. contingencia. de. 2. X. 2, phi. asume valores comprendidos entre 0 y 1. f. c. 2. = n.")
16
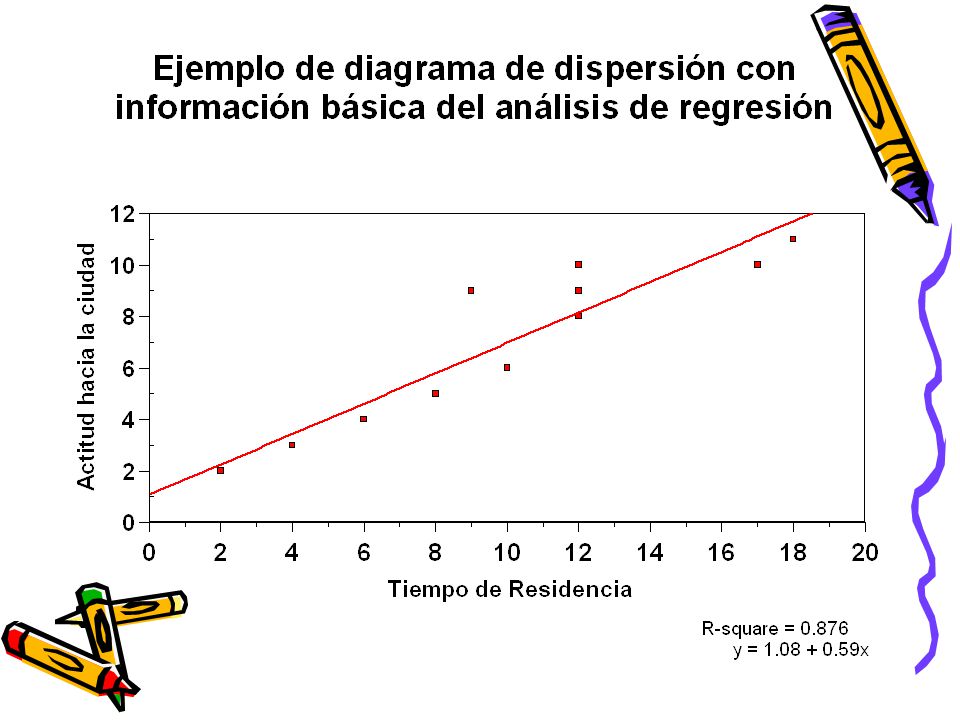
Elementos básicos de Análisis de Correlación y Regresión Lineal

17
S = r [ ( x - x ) . ( y - y ) ] ( x , y ) n . s . s
Coeficiente de correlación R de Pearson Coeficiente de correlación R de Pearson Es una medida de la asociación lineal entre dos variables de nivel de medición cuantitativo (intervalo o relación). De manera más específica, R informa sobre: El grado de correlación de las dos variables. El sentido o dirección de la correlación. El valor de R tiene un rango comprendido entre -1 (una relación negativa perfecta en la que todos los puntos se encuentran sobre una línea con pendiente negativa) y +1 (una relación positiva perfecta en la que todos los puntos se encuentran sobre una línea con pendiente positiva). Un valor de indica que no existe relación lineal. Su fórmula es: S [ ( x - x ) . ( y - y ) ] = r ( x , y ) n . s . s x y
![S = r [ ( x - x ) . ( y - y ) ] ( x , y ) n . s . s](http://slideplayer.es/slide/3291265/11/images/17/S+%3D+r+%5B+%28+x+-+x+%29+.+%28+y+-+y+%29+%5D+%28+x+%2C+y+%29+n+.+s+.+s.jpg "Coeficiente de correlación R de Pearson. Coeficiente de correlación R de Pearson. Es. una. medida. de. la. asociación. lineal. entre. dos. variables. de. nivel. de. medición. cuantitativo. (intervalo. o. relación). De. manera. más. específica, R. informa. sobre: El grado de correlación de las dos variables. El sentido o dirección de la correlación. El. valor. de. R. tiene. un. rango. comprendido. entre. -1. (una. relación. negativa. perfecta. en. la. que. todos. los. puntos. se. encuentran. sobre. una. línea. con. pendiente. negativa) y +1. (una. relación. positiva. perfecta. en. la. que. todos. los. puntos. se. encuentran. sobre. una. línea. con. pendiente. positiva). Un. valor. de. indica. que. no existe relación lineal. Su fórmula es: S. [ ( x. - x. ) . ( y. - y. ) ] = r. ( x. , y. ) n. . s. . s. x. y.")
22
Regresión lineal Se denomina "análisis de regresión lineal" a un
conjunto análisis estadísticos cuya función es determinar si entre una variable dependiente medida en una escala cuantitativa y una o más variables independientes, del mismo tipo, existen relaciones carácter lineal. Una relación lineal si posee una estructura idéntica a una línea recta. En rigor, el se utiliza para grado adecuación los datos empíricos al modelo recta y la probabilidad de que esa adecuación obedezca al azar. Cuando existe sólo independiente "regresión simple". Si más una, estará ante caso "regresión lineal múltiple". Básicamente permite contribuir dos propósitos: explicar predecir. da resultado negativo, debe interpretarse que poco probable existencia lineal, aunque no debe descartarse que existan otros tipos de relaciones, no lineales. También regresión" otros procedimientos diferentes mencionados pero comparten misma lógica.

23
La ecuación de la recta en el análisis de regresión lineal
y = + a b x Y = El valor de la variable dependiente predicho por el modelo lineal. a = Representa el valor de la variable dependiente cuando la variable independiente vale 0. Gráficamente corresponde al punto de Y donde se emplaza o intersecta la recta de regresión. b = Representa el incremento de Y por cada unidad de incremento de X. Gráficamente se expresa en la pendiente o grado de inclinación de la recta. X = El valor de la variable independiente X sobre el cuál se quiere hacer una predicción. _______________________________________________________________ Cuando la ecuación de la recta se utiliza para modelizar datos empíricos, vg., la recta de regresión, es necesario incorporar un factor aleatorio que representa los posibles fluctuaciones de los datos respecto al modelo o, en otros términos, las discrepancias entre el modelo y la realidad. En virtud de ello el modelo general de regresión lineal simple asume esta estructura: Y = a + b x + error

25
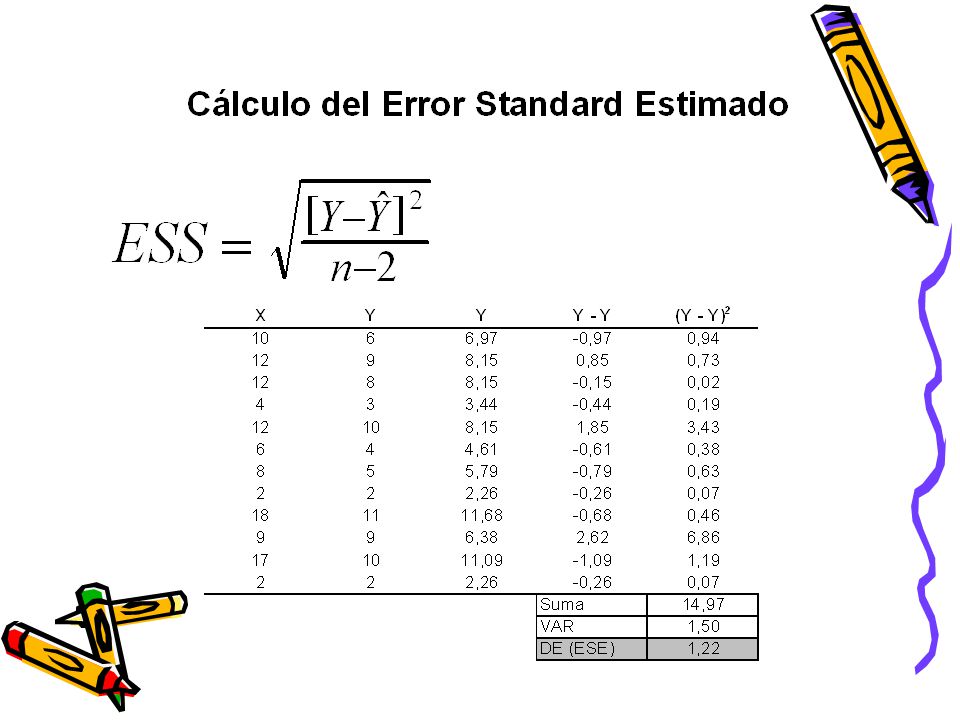
Cálculo de los parámetros de la recta de regresión
a partir de datos empíricos - x y x . y = b S 2 x - x 2 n = - a y b x

29
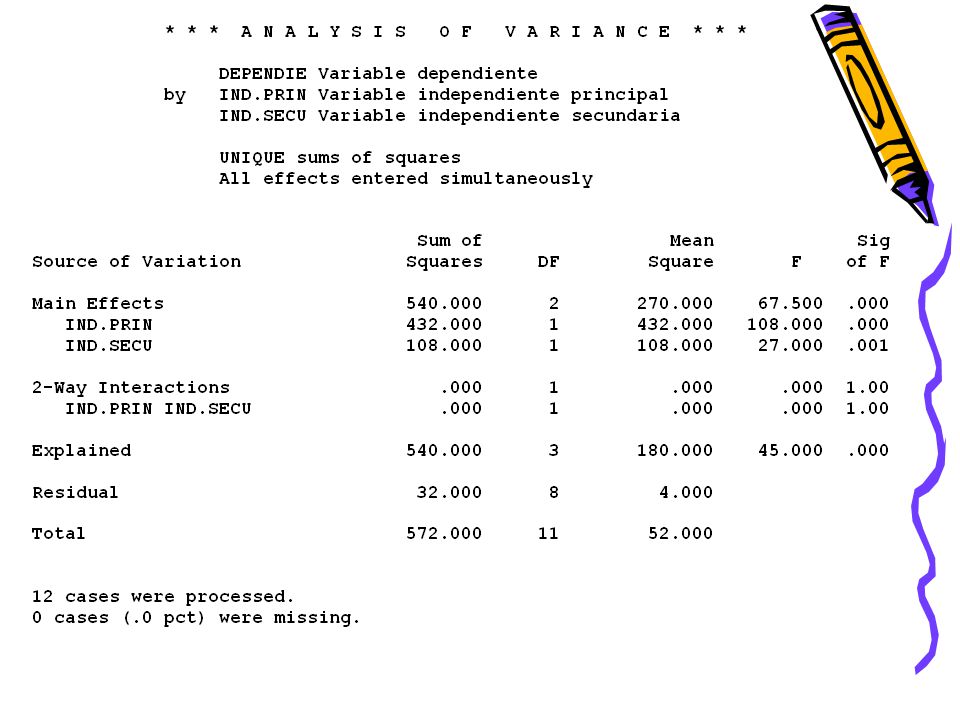
Elementos básicos del Análisis de Varianza

36
Elementos básicos de Análisis Discriminate

37
Terminología básica asociada al análisis
Término Significado Función discriminante Representa al modelo matemático que mejor discrimina a los valores de la variable dependiente (grupos) partir la/s variable/s independiente/es predictoras (es análoga ecuación de regresión, en ése análisis). Correlación canónica Es una medida representa el grado correlación entre y grupos. Al elevarse cuadrado proporción variabilidad involucrada con grupos coeficiente determinación R 2 en el análisis de regresión). Coeficiente l (lambda) de Wilk significación estadística básica del análisis. Señala probabilidad (P) predictivo evaluado se deba azar. (A diferencia de otros tests cuanto menor sea , menor será también P. No obstante, para determinar P, debe transformarse en c2 ) Cargas discriminantes (o correlaciones de estructura) Representan las correlaciones variables independientes función discriminante. Se interpretan como fuerza relativa cada dentro modelo: cuánto mayor resulte carga variable, contribución ésta discriminación global del modelo. Terminología básica asociada al análisis
 partir. la/s. variable/s. independiente/es. predictoras. (es. análoga. ecuación de regresión, en ése análisis). Correlación. canónica. Es. una. medida. representa. el. grado. correlación. entre. y. grupos. Al. elevarse. cuadrado. proporción. variabilidad. involucrada. con. grupos. coeficiente. determinación R. 2. en el análisis de regresión). Coeficiente. l. (lambda) de Wilk. significación. estadística. básica. del. análisis. Señala. probabilidad. (P) predictivo. evaluado. se. deba. azar. (A. diferencia de. otros. tests. cuanto. menor sea. , menor. será. también. P. No. obstante, para determinar P, debe transformarse en. c2. ) Cargas. discriminantes (o. correlaciones de. estructura) Representan. las. correlaciones. variables. independientes. función. discriminante. Se. interpretan. como. fuerza. relativa. cada. dentro. modelo: cuánto. mayor. resulte. carga. variable, contribución. ésta. discriminación global del modelo. Terminología básica asociada al análisis.")
39
Tres reportes estadísticos básicos del análisis discriminante
En las tablas de arriba aparecen tres reportes básicos del análisis discriminate: La correlación canónica, que informa sobre el potencial explicativo del modelo discriminante obtenido Los valores de lambda y chi cuadrado, junto al nivel de significación asociado La matriz de estructura, donde se informa el sentido y grado de la correlación entre cada variable predictora y el modelo discriminante obtenido

40
El resultado descriptivo fundamental del análisis discriminante
La tabla inmediata superior es la matriz de clasificación, que representa el resultado descriptivo básico del análisis discriminate. Allí se detallan en valores absolutos y porcentuales los casos clasificados correctamente en base a aplicar la función discriminate sobre los puntajes de las variables independientes. Como puede apreciarse, el modelo permite clasificar acertadamente al 85% de los casos, porcentaje que supera al que se habría obtenido aleatoriamente en base a las probabilidades previas de cada grupo (cuya esperanza matemática ascendería a 0,600 ó 60%; tabla superior)
")
41
Elementos básicos de Análisis Factorial

45
Elementos de cluster análisis en el contexto de la investigación psicográfica

46
Diagrama de flujo de una investigación psicográfica
Diseño muestral Elaboración de un cuestionario AIO Cruzar los clusters c/ otras var. de segmentación Cruzar los clusters con variables resultados relevantes Administración del Definición de objetivos Análisis multivariado Cluster análisis Descripción de los clusters Tabular Textual Interpretación de los clusters Número de clusters “ Pureza” de los clusters Validación de los clusters Descripción ampliada nivel 1 nivel 2 Cluster psicográfico Cluster psicográfico- demográfico Cluster psico-demo- gráfico-conductual específico

47
Clusters psicográficos cruzados con sus variables constituyentes originales
Variables originales Cluster 1 Cluster 2 General Tamaño 50% 100% Hedonismo 4.40 8 6.20 Innovatividad 4.30 7.10 5.70 Romanticismo 3.50 5.30 Religiosidad 7.00 5.25

48
Clusters o segmentos psicográficos cruzados con sus variables constituyentes originales: descripción tabular y textual Cluster 1: LOS ESPIRITUALISTAS Se definen por la alta valoración que le conceden al romanticismo y por su gran sentimiento de religiosidad. No sintonizan con valores hedonistas ni tampoco les interesan valores de la modernidad tales como la orientación a la innovación. Variables originales Espiritualistas Materialistas General Tamaño 50% 100% Hedonismo 4.40 8 6.20 Innovatividad 4.30 7.10 5.70 Romanticismo 3.50 5.30 Religiosidad 7.00 5.25 Cluster 2: LOS MATERIALISTAS Se definen por la alta valoración de valores de la modernidad tales como hedonismo e innovación. Descreen, o al menos no se sienten identificados, con valores de cuño más tradicional tales como el romanticismo y la religiosidad.

49
Clusters o segmentos psicográficos cruzados con demográficos

50
Cluster Análisis o Análisis de Conglomerados
El ánálisis de conglomerados o cluster análisis es un método estadístico multivariado cuyo objetivo básico es identificar grupos relativamente homogéneos a partir de determinadas características seleccionadas. Por ello, el análisis de conglomerados básicamente constituye un método de clasificación. El fundamento básico de esta metodología es el análisis de distancias entre observaciones. Su lógica es sencilla: Dos observaciones que puntúen de manera similar en las diversas características identificatorias (ie., las variables) se encuentran "próximas" en un espacio virtual clasificatorio y deberían, por lo tanto, clasificarse en los mismos conglomerados o clusters; recíprocamente, las observaciones que se encuentren "lejanas" entre sí, deberían corresponder a diferentes grupos. A diferencia del análisis discriminante,el análisis de conglomerados no parte de grupos dados a priori sino que - justamente- la obtención de tales grupos constituye el output del procedimiento. Por último, cabe precisar que, al igual que el análisis factorial, el cluster análisis constituye un método de interdependencia entre variables y por ende no discrimina entre variables independientes y dependientes.
 se encuentran próximas en un espacio virtual clasificatorio y deberían, por lo tanto, clasificarse en los mismos conglomerados o clusters; recíprocamente, las observaciones que se encuentren lejanas entre sí, deberían corresponder a diferentes grupos. A diferencia del análisis discriminante,el análisis de conglomerados no parte de grupos dados a priori sino que - justamente- la obtención de tales grupos constituye el output del procedimiento. Por último, cabe precisar que, al igual que el análisis factorial, el cluster análisis constituye un método de interdependencia entre variables y por ende no discrimina entre variables independientes y dependientes.")
51
Aplicaciones del análisis de conglomerados
El análisis de conglomerados es el método por excelencia para clasificar objetos en base a afinidades, por lo tanto resulta útil en los siguientes ámbitos: Segmentación psicográfica y otros perfiles actitudinales. Segmentación de audiencias y públicos. Clasificaciones de diversos objetos. Por ejemplo, pueden agruparse programas de capacitación en categorías homogéneas basadas en las características de los participantes. O bien pueden agruparse conjuntos de personas en conglomerados homogéneos para que pueden seleccionarse grupos comparables, con el fin de testear alguna estrategia.

52
Tipos básicos de análisis de conglomerados
Conglomerado de K medias: Realiza análisis de conglomerados usando un algoritmo que puede manejar grandes números de casos, pero que requiere la especificación del número de conglomerados. Conglomerados jerárquicos: Combina casos en conglomerados a través de una secuencia jerárquica, usando un algoritmo con consumo intensivo de memoria que permite examinar muchas soluciones diferentes con facilidad. Los clusters se forman mediante agrupamiento en conglomerados mayores o menores hasta que todos los casos sean miembros de un sólo conglomerado.

53
Ejemplo de operatoria del cluster análisis: a) Datos
Caso Hedonismo Innovatividad Romanticismo Religiosidad 1 3 10 9 2 4 8 5 7 6 11 12 13 14 15 16 17 18 19 20 En la matriz de datos se consigan los resultados de una encuesta sobre autoconcepto en cuatro variables cuyo rango oscilaba entre 1 y 10: a) hedonismo, b) innovatividad c) romanticismo d) religiosidad Tal como puede apreciarse, los primeros diez casos se caracterizan por su bajo hedonismo e innovatividad y su alto romanticismo y religiosidad; mientras que en los últimos 10, se observa lo inverso. Un análisis que requiriera dos cluster debería distinguir esos dos grupos.
 hedonismo, b) innovatividad. c) romanticismo. d) religiosidad. Tal como puede apreciarse, los primeros diez casos se caracterizan por su bajo hedonismo e innovatividad y su alto romanticismo y religiosidad; mientras que en los últimos 10, se observa lo inverso. Un análisis que requiriera dos cluster debería distinguir esos dos grupos.")
54
Ejemplo de operatoria de cluster análisis: b) Reportes básicos (Método K-Medias)
Number of Cases in each Cluster. Cluster cases ,0 ,0 EN LOS TABLAS DE ARRIBA APARECEN DOS REPORTES BASICOS DEL CLUSTER ANALISIS: 1°) La tabla que vincula a los clusters obtenidos con los valores promedio para cada una de las variables utilizadas. Constituye la base para su posterior interpretación. Así, en principio, el cluster 1 estaría conformado por personas de bajo hedonismo, con poca orientación a la innovación, autodefinidas como románticas y acentuadamente religiosas. Inversamente, el cluster 2 estaría integrado por personas marcadamente orientadas al hedonismo y la innovación y poco orientadas al romanticismo y la religiosidad. 2°) La cantidad de miembros en cada cluster, en este caso se trata de dos clusters de 10 integrantes cada uno.
 La tabla que vincula a los clusters obtenidos con los valores promedio para cada una de las variables utilizadas. Constituye la base para su posterior interpretación. Así, en principio, el cluster 1 estaría conformado por personas de bajo hedonismo, con poca orientación a la innovación, autodefinidas como románticas y acentuadamente religiosas. Inversamente, el cluster 2 estaría integrado por personas marcadamente orientadas al hedonismo y la innovación y poco orientadas al romanticismo y la religiosidad. 2°) La cantidad de miembros en cada cluster, en este caso se trata de dos clusters de 10 integrantes cada uno.")
55
Ejemplo de operatoria de cluster análisis: c) Reportes complementarios (Método K-Medias)
Otro reporte de interés está representado por el listado de asignación de casos a los diferentes clusters. En la última columna, aparece una medida de la distancia de cada caso al centro de su cluster, lo cual constituye un valor que informa cuán típico o atípico resulta un individuo respecto al cluster en el que ha sido clasificado. Como puede apreciarse al individuo N° 8 constituye el caso prototípico del cluster 1, ya que presenta la menor distancia al centro del mismo. Para corroborarlo, véase nuevamente la matriz de datos y la información de clusters finales.

56
Ejemplo de operatoria de cluster análisis: c) Reportes complementarios (Método K-Medias)
Otro dato de sumo interés es la tabla de Anova, donde se informa sobre el grado de significación estadística de la diferencia de las medias de los diferentes clusters, para todas las variables utilizidas en su conformación. En el presente caso, todos los valores resultan significativos, lo que indica que los clusters discriminan a los individuos en todas las variables.

57
Ejemplo de operatoria de cluster análisis: d) Reporte básico (Método Jerárquico)
 Reporte básico (Método Jerárquico)")
58
Ejemplo de operatoria de cluster análisis: e) Dendograma (Método Jerárquico)
 Dendograma (Método Jerárquico)")
59
Ejemplo de operatoria de cluster análisis: f) Historial de conglomeración (Método Jerárquico)
 Historial de conglomeración (Método Jerárquico)")
60
Ejemplo de operatoria de cluster análisis: g) Diagrama de témpanos (Método Jerárquico)
 Diagrama de témpanos (Método Jerárquico)")
Presentaciones similares