Descargar la presentación
La descarga está en progreso. Por favor, espere

1
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones IMPLEMENTACIÓN VLSI DEL ALGORITMO CORDIC EN MODO VECTORIZACIÓN UTILIZANDO RADIX ALTO José Alejandro Piñeiro Riobó

2
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC Algoritmo iterativo para la rotación de un vector en un sistema de coordenadas lineales, circulares o hiperbólicas. Permite realizar transformaciones de coordenadas y el cálculo de una gran variedad de funciones trigonométricas e hiperbólicas, entre otras. Utilizado en procesado digital de señales y gráficos 3D, álgebra matricial, radar y robótica, entre otras aplicaciones.

3
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC Algoritmo iterativo para la rotación de un vector en un sistema de coordenadas lineales, circulares o hiperbólicas. Permite realizar transformaciones de coordenadas y el cálculo de una gran variedad de funciones trigonométricas e hiperbólicas, entre otras. Utilizado en procesado digital de señales y gráficos 3D, álgebra matricial, radar y robótica, entre otras aplicaciones.

4
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC Algoritmo iterativo para la rotación de un vector en un sistema de coordenadas lineales, circulares o hiperbólicas. Permite realizar transformaciones de coordenadas y el cálculo de una gran variedad de funciones trigonométricas e hiperbólicas, entre otras. Utilizado en procesado digital de señales y gráficos 3D, álgebra matricial, radar y robótica, entre otras aplicaciones.

5
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC Algoritmo iterativo para la rotación de un vector en un sistema de coordenadas lineales, circulares o hiperbólicas. Permite realizar transformaciones de coordenadas y el cálculo de una gran variedad de funciones trigonométricas e hiperbólicas, entre otras. Utilizado en procesado digital de señales y gráficos 3D, álgebra matricial, radar y robótica, entre otras aplicaciones.

6
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC Formulación convencional: recurrencia radix 2 (se extrae 1 bit del resultado en cada iteración). Iteraciones lentas. Elevada latencia para un tamaño de palabra elevado. Soluciones: Uso de sumadores rápidos (CLA) y/o aritmética redundante (carry-save, signed-digit). Empleo de recurrencias con un radix alto r 2 b (se extraen b bits del resultado en cada iteración).
. Iteraciones lentas. Elevada latencia para un tamaño de palabra elevado. Soluciones: Uso de sumadores rápidos (CLA) y/o aritmética redundante (carry-save, signed-digit). Empleo de recurrencias con un radix alto r 2 b (se extraen b bits del resultado en cada iteración)..")
7
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC Formulación convencional: recurrencia radix 2 (se extrae 1 bit del resultado en cada iteración). Iteraciones lentas. Elevada latencia para un tamaño de palabra elevado. Soluciones: Uso de sumadores rápidos (CLA) y/o aritmética redundante (carry-save, signed-digit). Empleo de recurrencias con un radix alto r 2 b (se extraen b bits del resultado en cada iteración).
. Iteraciones lentas. Elevada latencia para un tamaño de palabra elevado. Soluciones: Uso de sumadores rápidos (CLA) y/o aritmética redundante (carry-save, signed-digit). Empleo de recurrencias con un radix alto r 2 b (se extraen b bits del resultado en cada iteración)..")
8
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC Formulación convencional: recurrencia radix 2 (se extrae 1 bit del resultado en cada iteración). Iteraciones lentas. Elevada latencia para un tamaño de palabra elevado. Soluciones: Uso de sumadores rápidos (CLA) y/o aritmética redundante (carry-save, signed-digit). Empleo de recurrencias con un radix alto r 2 b (se extraen b bits del resultado en cada iteración).
. Iteraciones lentas. Elevada latencia para un tamaño de palabra elevado. Soluciones: Uso de sumadores rápidos (CLA) y/o aritmética redundante (carry-save, signed-digit). Empleo de recurrencias con un radix alto r 2 b (se extraen b bits del resultado en cada iteración)..")
9
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC Formulación convencional: recurrencia radix 2 (se extrae 1 bit del resultado en cada iteración). Iteraciones lentas. Elevada latencia para un tamaño de palabra elevado. Soluciones: Uso de sumadores rápidos (CLA) y/o aritmética redundante (carry-save, signed-digit). Empleo de recurrencias con un radix alto r 2 b (se extraen b bits del resultado en cada iteración).
. Iteraciones lentas. Elevada latencia para un tamaño de palabra elevado. Soluciones: Uso de sumadores rápidos (CLA) y/o aritmética redundante (carry-save, signed-digit). Empleo de recurrencias con un radix alto r 2 b (se extraen b bits del resultado en cada iteración)..")
10
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC Formulación convencional: recurrencia radix 2 (se extrae 1 bit del resultado en cada iteración). Iteraciones lentas. Elevada latencia para un tamaño de palabra elevado. Soluciones: Uso de sumadores rápidos (CLA) y/o aritmética redundante (carry-save, signed-digit). Empleo de recurrencias con un radix alto r 2 b (se extraen b bits del resultado en cada iteración).
. Iteraciones lentas. Elevada latencia para un tamaño de palabra elevado. Soluciones: Uso de sumadores rápidos (CLA) y/o aritmética redundante (carry-save, signed-digit). Empleo de recurrencias con un radix alto r 2 b (se extraen b bits del resultado en cada iteración)..")
11
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC Formulación convencional: recurrencia radix 2 (se extrae 1 bit del resultado en cada iteración). Iteraciones lentas. Elevada latencia para un tamaño de palabra elevado. Soluciones: Uso de sumadores rápidos (CLA) y/o aritmética redundante (carry-save, signed-digit). Empleo de recurrencias con un radix alto r 2 b (se extraen b bits del resultado en cada iteración).
. Iteraciones lentas. Elevada latencia para un tamaño de palabra elevado. Soluciones: Uso de sumadores rápidos (CLA) y/o aritmética redundante (carry-save, signed-digit). Empleo de recurrencias con un radix alto r 2 b (se extraen b bits del resultado en cada iteración)..")
12
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN Modo vectorización.- Rotación del vector inicial hasta que se sitúa sobre el eje de coordenadas X. Resultados: x N 1 =módulo y z N 1 =argumento. Fundamento: descomposición del ángulo de rotación en una suma de ángulos elementales: Los coeficientes i toman valores enteros en el intervalo { (r 1),..., 0,..., (r 1)}, siendo el radix r 2 b.
,..., 0,..., (r 1)}, siendo el radix r 2 b..")
13
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN Modo vectorización.- Rotación del vector inicial hasta que se sitúa sobre el eje de coordenadas X. Resultados: x N 1 =módulo y z N 1 =argumento. Fundamento: descomposición del ángulo de rotación en una suma de ángulos elementales: Los coeficientes i toman valores enteros en el intervalo { (r 1),..., 0,..., (r 1)}, siendo el radix r 2 b.
,..., 0,..., (r 1)}, siendo el radix r 2 b..")
14
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN Y X

15
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN Modo vectorización.- Rotación del vector inicial hasta que se sitúa sobre el eje de coordenadas X. Resultados: x N 1 =módulo y z N 1 =argumento. Fundamento: descomposición del ángulo de rotación en una suma de ángulos elementales: Los coeficientes i toman valores enteros en el intervalo { (r 1),..., 0,..., (r 1)}, siendo el radix r 2 b.
,..., 0,..., (r 1)}, siendo el radix r 2 b..")
16
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Expresión de las recurrencias: d[i 1] d[i] i r 2i [i] [i 1] r( [i] i d[i]) z[i 1] z[i] tan 1 ( i r i ) con d[1] x in, [1] r y in, z[1] 0. Los coeficientes i se seleccionan mediante el redondeo de [i ] truncado a t bits fraccionales: i round ( [i] t ) ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN
 z[i 1] z[i] tan 1 ( i r i ) con d[1] x in, [1] r y in, z[1] 0. Los coeficientes i se seleccionan mediante el redondeo de [i ] truncado a t bits fraccionales: i round ( [i] t ) ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN.")
17
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Expresión de las recurrencias: d[i 1] d[i] i r 2i [i] [i 1] r( [i] i d[i]) z[i 1] z[i] tan 1 ( i r i ) con d[1] x in, [1] r y in, z[1] 0. Los coeficientes i se seleccionan mediante el redondeo de [i ] truncado a t bits fraccionales: i round ( [i] t ) ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN
 z[i 1] z[i] tan 1 ( i r i ) con d[1] x in, [1] r y in, z[1] 0. Los coeficientes i se seleccionan mediante el redondeo de [i ] truncado a t bits fraccionales: i round ( [i] t ) ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN.")
18
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Expresión de las recurrencias: d[i 1] d[i] i r 2i [i] [i 1] r( [i] i d[i]) z[i 1] z[i] tan 1 ( i r i ) con d[1] x in, [1] r y in, z[1] 0. Los coeficientes i se seleccionan mediante el redondeo de [i ] truncado a t bits fraccionales: i round ( [i] t ) ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN
 z[i 1] z[i] tan 1 ( i r i ) con d[1] x in, [1] r y in, z[1] 0. Los coeficientes i se seleccionan mediante el redondeo de [i ] truncado a t bits fraccionales: i round ( [i] t ) ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN.")
19
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN Necesidad de dos escalados de la recurrencia (empleo de los factores M 1 y M 2 ) para asegurar convergencia. Uno antes y otro después de la primera microrrotación. Para simplificar el primer escalado, se utiliza un radix R inferior en la primera microrrotación, siendo: R 2 B 2 b/2 1,para t 2 Extensión del rango de convergencia. Comparación de los F bits más significativos de x in e y in. Si y in x in +2 F, intercambio, z[1] /2 y se decrementa.
 para asegurar convergencia. Uno antes y otro después de la primera microrrotación. Para simplificar el primer escalado, se utiliza un radix R inferior en la primera microrrotación, siendo: R 2 B 2 b/2 1,para t 2 Extensión del rango de convergencia. Comparación de los F bits más significativos de x in e y in. Si y in x in +2 F, intercambio, z[1] /2 y se decrementa..")
20
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN Necesidad de dos escalados de la recurrencia (empleo de los factores M 1 y M 2 ) para asegurar convergencia. Uno antes y otro después de la primera microrrotación. Para simplificar el primer escalado, se utiliza un radix R inferior en la primera microrrotación, siendo: R 2 B 2 b/2 1,para t 2 Extensión del rango de convergencia. Comparación de los F bits más significativos de x in e y in. Si y in x in +2 F, intercambio, z[1] /2 y se decrementa.
 para asegurar convergencia. Uno antes y otro después de la primera microrrotación. Para simplificar el primer escalado, se utiliza un radix R inferior en la primera microrrotación, siendo: R 2 B 2 b/2 1,para t 2 Extensión del rango de convergencia. Comparación de los F bits más significativos de x in e y in. Si y in x in +2 F, intercambio, z[1] /2 y se decrementa..")
21
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN Necesidad de dos escalados de la recurrencia (empleo de los factores M 1 y M 2 ) para asegurar convergencia. Uno antes y otro después de la primera microrrotación. Para simplificar el primer escalado, se utiliza un radix R inferior en la primera microrrotación, siendo: R 2 B 2 b/2 1,para t 2 Extensión del rango de convergencia. Comparación de los F bits más significativos de x in e y in. Si y in x in +2 F, intercambio, z[1] /2 y se decrementa.
 para asegurar convergencia. Uno antes y otro después de la primera microrrotación. Para simplificar el primer escalado, se utiliza un radix R inferior en la primera microrrotación, siendo: R 2 B 2 b/2 1,para t 2 Extensión del rango de convergencia. Comparación de los F bits más significativos de x in e y in. Si y in x in +2 F, intercambio, z[1] /2 y se decrementa..")
22
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN Necesidad de dos escalados de la recurrencia (empleo de los factores M 1 y M 2 ) para asegurar convergencia. Uno antes y otro después de la primera microrrotación. Para simplificar el primer escalado, se utiliza un radix R inferior en la primera microrrotación, siendo: R 2 B 2 b/2 1,para t 2 Extensión del rango de convergencia. Comparación de los F bits más significativos de x in e y in. Si y in x in +2 F, intercambio, z[1] /2 y se decrementa.
 para asegurar convergencia. Uno antes y otro después de la primera microrrotación. Para simplificar el primer escalado, se utiliza un radix R inferior en la primera microrrotación, siendo: R 2 B 2 b/2 1,para t 2 Extensión del rango de convergencia. Comparación de los F bits más significativos de x in e y in. Si y in x in +2 F, intercambio, z[1] /2 y se decrementa..")
23
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN Existencia de un factor de escala K i en las variables d y en cada microrrotación. El factor de escala global viene dado por: K depende del ángulo. Cómputo de ln(K 1 ): g[i 1] g[i] (1/2)ln(1 i 2 r 2i ). Compensación evaluando la función exponencial: x r x C ·exp(ln(K 1 )) x C ·K
: g[i 1] g[i] (1/2)ln(1 i 2 r 2i ). Compensación evaluando la función exponencial: x r x C ·exp(ln(K 1 )) x C ·K .")
24
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN Existencia de un factor de escala K i en las variables d y en cada microrrotación. El factor de escala global viene dado por: K depende del ángulo. Cómputo de ln(K 1 ): g[i 1] g[i] (1/2)ln(1 i 2 r 2i ). Compensación evaluando la función exponencial: x r x C ·exp(ln(K 1 )) x C ·K
: g[i 1] g[i] (1/2)ln(1 i 2 r 2i ). Compensación evaluando la función exponencial: x r x C ·exp(ln(K 1 )) x C ·K .")
25
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN Existencia de un factor de escala K i en las variables d y en cada microrrotación. El factor de escala global viene dado por: K depende del ángulo. Cómputo de ln(K 1 ): g[i 1] g[i] (1/2)ln(1 i 2 r 2i ). Compensación evaluando la función exponencial: x r x C ·exp(ln(K 1 )) x C ·K
: g[i 1] g[i] (1/2)ln(1 i 2 r 2i ). Compensación evaluando la función exponencial: x r x C ·exp(ln(K 1 )) x C ·K .")
26
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN Existencia de un factor de escala K i en las variables d y en cada microrrotación. El factor de escala global viene dado por: K depende del ángulo. Cómputo de ln(K 1 ): g[i 1] g[i] (1/2)ln(1 i 2 r 2i ). Compensación evaluando la función exponencial: x r x C ·exp(ln(K 1 )) x C ·K
: g[i 1] g[i] (1/2)ln(1 i 2 r 2i ). Compensación evaluando la función exponencial: x r x C ·exp(ln(K 1 )) x C ·K .")
27
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ALGORITMO CORDIC CON RADIX ALTO EN MODO VECTORIZACIÓN Existencia de un factor de escala K i en las variables d y en cada microrrotación. El factor de escala global viene dado por: K depende del ángulo. Cómputo de ln(K 1 ): g[i 1] g[i] (1/2)ln(1 i 2 r 2i ). Compensación evaluando la función exponencial: x r x C ·exp(ln(K 1 )) x C ·K
: g[i 1] g[i] (1/2)ln(1 i 2 r 2i ). Compensación evaluando la función exponencial: x r x C ·exp(ln(K 1 )) x C ·K .")
29
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ARQUITECTURA Arquitectura palabra-serie. Formato de punto fijo. Arquitectura para el cálculo del argumento del vector de entrada: función tan 1 (y in /x in ). Arquitectura para el cálculo de módulo y argumento: (x in 2 y in 2 ) ½ y tan 1 (y in /x in ).
. Arquitectura para el cálculo de módulo y argumento: (x in 2 y in 2 ) ½ y tan 1 (y in /x in )..")
30
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ARQUITECTURA Arquitectura palabra-serie. Formato de punto fijo. Arquitectura para el cálculo del argumento del vector de entrada: función tan 1 (y in /x in ). Arquitectura para el cálculo de módulo y argumento: (x in 2 y in 2 ) ½ y tan 1 (y in /x in ).
. Arquitectura para el cálculo de módulo y argumento: (x in 2 y in 2 ) ½ y tan 1 (y in /x in )..")
31
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ARQUITECTURA Arquitectura palabra-serie. Formato de punto fijo. Arquitectura para el cálculo del argumento del vector de entrada: función tan 1 (y in /x in ). Arquitectura para el cálculo de módulo y argumento: (x in 2 y in 2 ) ½ y tan 1 (y in /x in ).
. Arquitectura para el cálculo de módulo y argumento: (x in 2 y in 2 ) ½ y tan 1 (y in /x in )..")
32
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones ARQUITECTURA Arquitectura palabra-serie. Formato de punto fijo. Arquitectura para el cálculo del argumento del vector de entrada: función tan 1 (y in /x in ). Arquitectura para el cálculo de módulo y argumento: (x in 2 y in 2 ) ½ y tan 1 (y in /x in ).
. Arquitectura para el cálculo de módulo y argumento: (x in 2 y in 2 ) ½ y tan 1 (y in /x in )..")
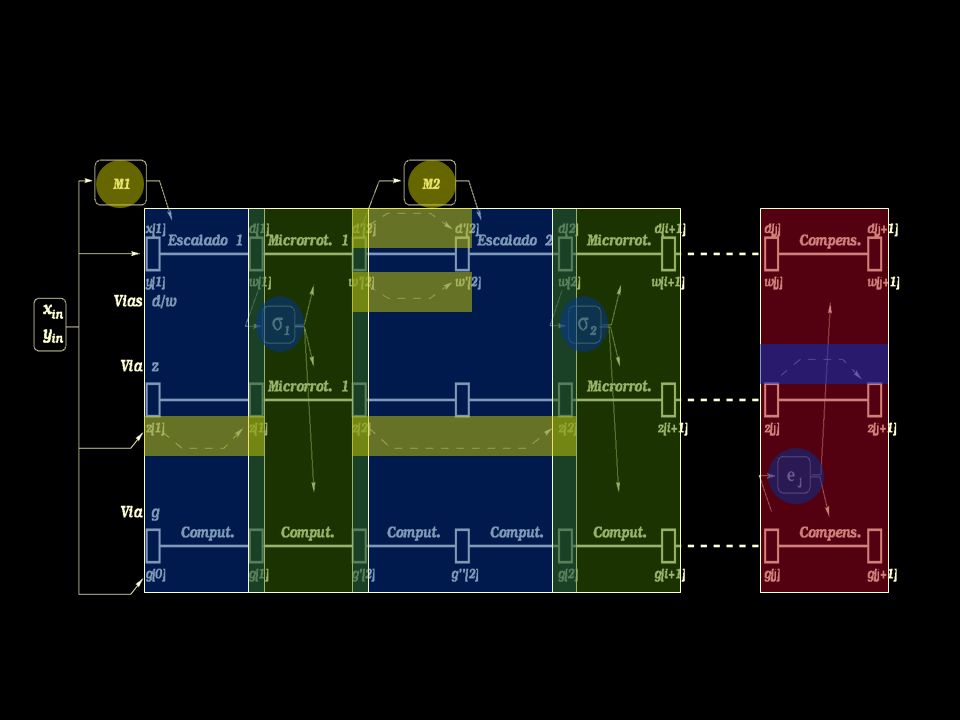
33
Arquitectura completa Arquitectura argumento (modificada) vía g. z[i 1] z[i] tan 1 ( i r i ) d[i 1] d[i] i r 2i [i] [i 1] r( [i] i d[i]) g[i 1] g[i] (1/2)ln(1 i 2 r 2i ) g[j 1] r (g[j] r j ln(1 e j r j )) d[j 1] d[j] e j d[j]r j
 d[i 1] d[i] i r 2i [i] [i 1] r( [i] i d[i]) g[i 1] g[i] (1/2)ln(1 i 2 r 2i ) g[j 1] r (g[j] r j ln(1 e j r j )) d[j 1] d[j] e j d[j]r j.")
34
Vías d y .- Realización de los escalados y las microrrotaciones. Bloques de M 1 y M 2.- Obtención de los factores de escalado. Bloques de i y e j.- Selección de los coeficientes mediante redondeo. Vía z.- Determinación del ángulo elemental en cada microrrotación y cómputo del ángulo total. Vía g.- Cómputo de ln(K 1 ) y, junto con la vía d, realización de las iteraciones de compensación. Unidad de control (FSM). g
 y, junto con la vía d, realización de las iteraciones de compensación. Unidad de control (FSM). g.")
35
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Parámetros de diseño. Precisión: n 32 bits. Radix r 512, valor t 3 bits. Radix R 32, valor F 5 bits. Tamaño de palabra interno: q 38 bits fraccionales. Es necesario realizar N 4 microrrotaciones para alcanzar la precisión de n 32 bits. n B (N 1)·b IMPLEMENTACIÓN
·b IMPLEMENTACIÓN.")
36
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Parámetros de diseño. Precisión: n 32 bits. Radix r 512, valor t 3 bits. Radix R 32, valor F 5 bits. Tamaño de palabra interno: q 38 bits fraccionales. Es necesario realizar N 4 microrrotaciones para alcanzar la precisión de n 32 bits. n B (N 1)·b IMPLEMENTACIÓN
·b IMPLEMENTACIÓN.")
37
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Parámetros de diseño. Precisión: n 32 bits. Radix r 512, valor t 3 bits. Radix R 32, valor F 5 bits. Tamaño de palabra interno: q 38 bits fraccionales. Es necesario realizar N 4 microrrotaciones para alcanzar la precisión de n 32 bits. n B (N 1)·b IMPLEMENTACIÓN
·b IMPLEMENTACIÓN.")
38
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Parámetros de diseño. Precisión: n 32 bits. Radix r 512, valor t 3 bits. Radix R 32, valor F 5 bits. Tamaño de palabra interno: q 38 bits fraccionales. Es necesario realizar N 4 microrrotaciones para alcanzar la precisión de n 32 bits. n B (N 1)·b IMPLEMENTACIÓN
·b IMPLEMENTACIÓN.")
39
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Flujo de diseño basado en VHDL. Herramientas CAD utilizadas en el diseño lógico: HDLdesk, de Cadence (simulación funcional de los componentes). Design Analyzer, de Synopsys (síntesis lógica y simulación pre-layout). Librería de celdas estándar 0.7 m CMOS doble metal de ES2. IMPLEMENTACIÓN
. Design Analyzer, de Synopsys (síntesis lógica y simulación pre-layout). Librería de celdas estándar 0.7 m CMOS doble metal de ES2. IMPLEMENTACIÓN.")
40
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Flujo de diseño basado en VHDL. Herramientas CAD utilizadas en el diseño lógico: HDLdesk, de Cadence (simulación funcional de los componentes). Design Analyzer, de Synopsys (síntesis lógica y simulación pre-layout). Librería de celdas estándar 0.7 m CMOS doble metal de ES2. IMPLEMENTACIÓN
. Design Analyzer, de Synopsys (síntesis lógica y simulación pre-layout). Librería de celdas estándar 0.7 m CMOS doble metal de ES2. IMPLEMENTACIÓN.")
41
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Flujo de diseño basado en VHDL. Herramientas CAD utilizadas en el diseño lógico: HDLdesk, de Cadence (simulación funcional de los componentes). Design Analyzer, de Synopsys (síntesis lógica y simulación pre-layout). Librería de celdas estándar 0.7 m CMOS doble metal de ES2. IMPLEMENTACIÓN
. Design Analyzer, de Synopsys (síntesis lógica y simulación pre-layout). Librería de celdas estándar 0.7 m CMOS doble metal de ES2. IMPLEMENTACIÓN.")
42
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Flujo de diseño basado en VHDL. Herramientas CAD utilizadas en el diseño lógico: HDLdesk, de Cadence (simulación funcional de los componentes). Design Analyzer, de Synopsys (síntesis lógica y simulación pre-layout). Librería de celdas estándar 0.7 m CMOS doble metal de ES2. IMPLEMENTACIÓN
. Design Analyzer, de Synopsys (síntesis lógica y simulación pre-layout). Librería de celdas estándar 0.7 m CMOS doble metal de ES2. IMPLEMENTACIÓN.")
43
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Flujo de diseño basado en VHDL. Herramientas CAD utilizadas en el diseño lógico: HDLdesk, de Cadence (simulación funcional de los componentes). Design Analyzer, de Synopsys (síntesis lógica y simulación pre-layout). Librería de celdas estándar 0.7 m CMOS doble metal de ES2. IMPLEMENTACIÓN
. Design Analyzer, de Synopsys (síntesis lógica y simulación pre-layout). Librería de celdas estándar 0.7 m CMOS doble metal de ES2. IMPLEMENTACIÓN.")
44
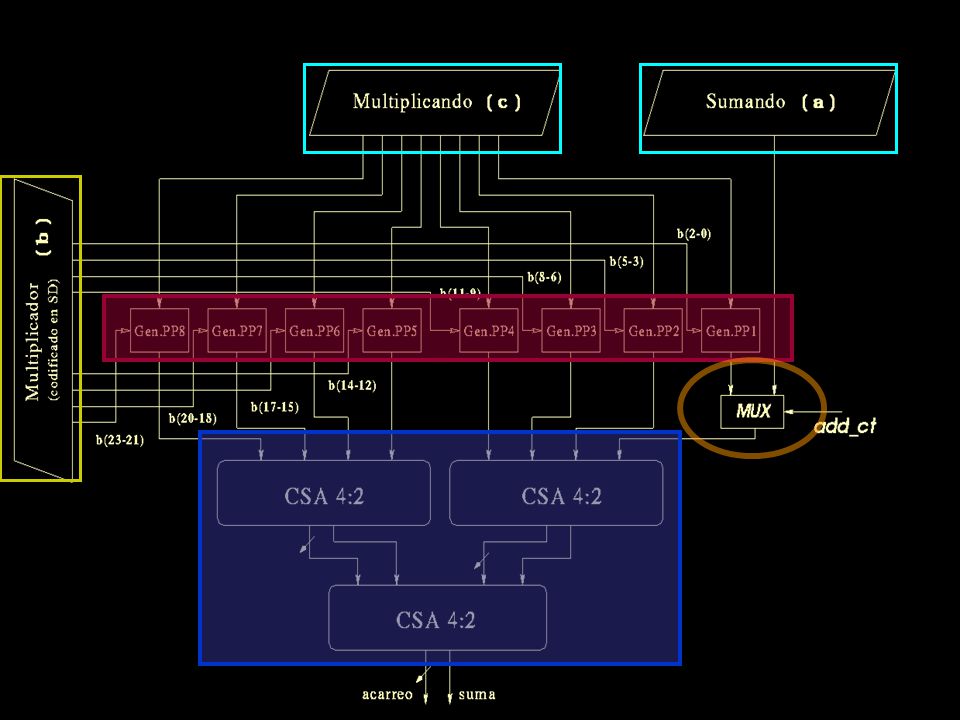
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones IMPLEMENTACIÓN Multiplicadores-Acumuladores (MAC): Evaluación de la operación: h a b ·c. Representación de los operandos: Complemento a dos: sumando ( a ) y multiplicando ( c ). SD-radix 4: multiplicador ( b ); reduce a la mitad el número de productos parciales a acumular.
: Evaluación de la operación: h a b ·c. Representación de los operandos: Complemento a dos: sumando ( a ) y multiplicando ( c ). SD-radix 4: multiplicador ( b ); reduce a la mitad el número de productos parciales a acumular..")
45
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones IMPLEMENTACIÓN Multiplicadores-Acumuladores (MAC): Evaluación de la operación: h a b ·c. Representación de los operandos: Complemento a dos: sumando ( a ) y multiplicando ( c ). SD-radix 4: multiplicador ( b ); reduce a la mitad el número de productos parciales a acumular.
: Evaluación de la operación: h a b ·c. Representación de los operandos: Complemento a dos: sumando ( a ) y multiplicando ( c ). SD-radix 4: multiplicador ( b ); reduce a la mitad el número de productos parciales a acumular..")
46
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones IMPLEMENTACIÓN Multiplicadores-Acumuladores (MAC): Evaluación de la operación: h a b ·c. Representación de los operandos: Complemento a dos: sumando ( a ) y multiplicando ( c ). SD-radix 4: multiplicador ( b ); reduce a la mitad el número de productos parciales a acumular.
: Evaluación de la operación: h a b ·c. Representación de los operandos: Complemento a dos: sumando ( a ) y multiplicando ( c ). SD-radix 4: multiplicador ( b ); reduce a la mitad el número de productos parciales a acumular..")
47
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones IMPLEMENTACIÓN Multiplicadores-Acumuladores (MAC): Evaluación de la operación: h a b ·c. Representación de los operandos: Complemento a dos: sumando ( a ) y multiplicando ( c ). SD-radix 4: multiplicador ( b ); reduce a la mitad el número de productos parciales a acumular.
: Evaluación de la operación: h a b ·c. Representación de los operandos: Complemento a dos: sumando ( a ) y multiplicando ( c ). SD-radix 4: multiplicador ( b ); reduce a la mitad el número de productos parciales a acumular..")
49
ARCHITECTURE behave OF mac_d IS -- Declaración del componente CSA_TREE -- Declaración de señales y constantes for U1 : csa_tree Use Entity work.csa_tree(crypt); BEGIN partial1:process(b) begin for i in 0 to 7 loop b0(i)<=b(3*i); b1(i)<=b(3*i+1); b2(i)<=b(3*i+2); end loop; end process partial1; partial2:process(b0,b1,b2,c) begin for i in 0 to 7 loop res(i)(0)<=b0(i) xor ((c(0) nand b1(i)) nand ('0' nand b2(i))); for j in 1 to 40 loop res(i)(j)<=b0(i) xor ((c(j) nand b1(i)) nand (c(j-1) nand b2(i))); end loop; res(i)(41)<=b0(i) xor ((c(40) nand b1(i)) nand (c(40) nand b2(i))); end loop; end process partial2; partial3:process(res,add_ct,a) begin if add_ct='0' then PP1(57 downto 42) res(0)(41)); PP1(41 downto 0)<= res(0); else PP1(57 downto 48) a(40)); PP1(47 downto 7)<= a; PP1(6 downto 0) ’0’); end if; PP2(57 downto 44) res(1)(41)); PP2(43 downto 2)<= res(1); PP3(57 downto 46) res(2)(41)); PP3(45 downto 4)<= res(2); PP4(57 downto 48) res(3)(41)); PP4(47 downto 6)<= res(3); -- Sigue la construcción de prod. parc. hasta PP8 end process partial3; U1 : csa_tree port map (PP1,PP2,PP3,PP4,PP5,PP6,PP7,PP8,ssm,crr); END behave;
; END behave;.")
50
ARCHITECTURE behave OF mac_d IS -- Declaración del componente CSA_TREE -- Declaración de señales y constantes for U1 : csa_tree Use Entity work.csa_tree(crypt); BEGIN partial1:process(b) begin for i in 0 to 7 loop b0(i)<=b(3*i); b1(i)<=b(3*i+1); b2(i)<=b(3*i+2); end loop; end process partial1; partial2:process(b0,b1,b2,c) begin for i in 0 to 7 loop res(i)(0)<=b0(i) xor ((c(0) nand b1(i)) nand ('0' nand b2(i))); for j in 1 to 40 loop res(i)(j)<=b0(i) xor ((c(j) nand b1(i)) nand (c(j-1) nand b2(i))); end loop; res(i)(41)<=b0(i) xor ((c(40) nand b1(i)) nand (c(40) nand b2(i))); end loop; end process partial2; partial3:process(res,add_ct,a) begin if add_ct='0' then PP1(57 downto 42) res(0)(41)); PP1(41 downto 0)<= res(0); else PP1(57 downto 48) a(40)); PP1(47 downto 7)<= a; PP1(6 downto 0) ’0’); end if; PP2(57 downto 44) res(1)(41)); PP2(43 downto 2)<= res(1); PP3(57 downto 46) res(2)(41)); PP3(45 downto 4)<= res(2); PP4(57 downto 48) res(3)(41)); PP4(47 downto 6)<= res(3); -- Sigue la construcción de prod. parc. hasta PP8 end process partial3; U1 : csa_tree port map (PP1,PP2,PP3,PP4,PP5,PP6,PP7,PP8,ssm,crr); END behave;
; END behave;.")
51
ARCHITECTURE behave OF mac_d IS -- Declaración del componente CSA_TREE -- Declaración de señales y constantes for U1 : csa_tree Use Entity work.csa_tree(crypt); BEGIN partial1:process(b) begin for i in 0 to 7 loop b0(i)<=b(3*i); b1(i)<=b(3*i+1); b2(i)<=b(3*i+2); end loop; end process partial1; partial2:process(b0,b1,b2,c) begin for i in 0 to 7 loop res(i)(0)<=b0(i) xor ((c(0) nand b1(i)) nand ('0' nand b2(i))); for j in 1 to 40 loop res(i)(j)<=b0(i) xor ((c(j) nand b1(i)) nand (c(j-1) nand b2(i))); end loop; res(i)(41)<=b0(i) xor ((c(40) nand b1(i)) nand (c(40) nand b2(i))); end loop; end process partial2; partial3:process(res,add_ct,a) begin if add_ct='0' then PP1(57 downto 42) res(0)(41)); PP1(41 downto 0)<= res(0); else PP1(57 downto 48) a(40)); PP1(47 downto 7)<= a; PP1(6 downto 0) ’0’); end if; PP2(57 downto 44) res(1)(41)); PP2(43 downto 2)<= res(1); PP3(57 downto 46) res(2)(41)); PP3(45 downto 4)<= res(2); PP4(57 downto 48) res(3)(41)); PP4(47 downto 6)<= res(3); -- Sigue la construcción de prod. parc. hasta PP8 end process partial3; U1 : csa_tree port map (PP1,PP2,PP3,PP4,PP5,PP6,PP7,PP8,ssm,crr); END behave;
; END behave;.")
52
ARCHITECTURE behave OF mac_d IS -- Declaración del componente CSA_TREE -- Declaración de señales y constantes for U1 : csa_tree Use Entity work.csa_tree(crypt); BEGIN partial1:process(b) begin for i in 0 to 7 loop b0(i)<=b(3*i); b1(i)<=b(3*i+1); b2(i)<=b(3*i+2); end loop; end process partial1; partial2:process(b0,b1,b2,c) begin for i in 0 to 7 loop res(i)(0)<=b0(i) xor ((c(0) nand b1(i)) nand ('0' nand b2(i))); for j in 1 to 40 loop res(i)(j)<=b0(i) xor ((c(j) nand b1(i)) nand (c(j-1) nand b2(i))); end loop; res(i)(41)<=b0(i) xor ((c(40) nand b1(i)) nand (c(40) nand b2(i))); end loop; end process partial2; partial3:process(res,add_ct,a) begin if add_ct='0' then PP1(57 downto 42) res(0)(41)); PP1(41 downto 0)<= res(0); else PP1(57 downto 48) a(40)); PP1(47 downto 7)<= a; PP1(6 downto 0) ’0’); end if; PP2(57 downto 44) res(1)(41)); PP2(43 downto 2)<= res(1); PP3(57 downto 46) res(2)(41)); PP3(45 downto 4)<= res(2); PP4(57 downto 48) res(3)(41)); PP4(47 downto 6)<= res(3); -- Sigue la construcción de prod. parc. hasta PP8 end process partial3; U1 : csa_tree port map (PP1,PP2,PP3,PP4,PP5,PP6,PP7,PP8,ssm,crr); END behave;
; END behave;.")
53
ARCHITECTURE behave OF mac_d IS -- Declaración del componente CSA_TREE -- Declaración de señales y constantes for U1 : csa_tree Use Entity work.csa_tree(crypt); BEGIN partial1:process(b) begin for i in 0 to 7 loop b0(i)<=b(3*i); b1(i)<=b(3*i+1); b2(i)<=b(3*i+2); end loop; end process partial1; partial2:process(b0,b1,b2,c) begin for i in 0 to 7 loop res(i)(0)<=b0(i) xor ((c(0) nand b1(i)) nand ('0' nand b2(i))); for j in 1 to 40 loop res(i)(j)<=b0(i) xor ((c(j) nand b1(i)) nand (c(j-1) nand b2(i))); end loop; res(i)(41)<=b0(i) xor ((c(40) nand b1(i)) nand (c(40) nand b2(i))); end loop; end process partial2; partial3:process(res,add_ct,a) begin if add_ct='0' then PP1(57 downto 42) res(0)(41)); PP1(41 downto 0)<= res(0); else PP1(57 downto 48) a(40)); PP1(47 downto 7)<= a; PP1(6 downto 0) ’0’); end if; PP2(57 downto 44) res(1)(41)); PP2(43 downto 2)<= res(1); PP3(57 downto 46) res(2)(41)); PP3(45 downto 4)<= res(2); PP4(57 downto 48) res(3)(41)); PP4(47 downto 6)<= res(3); -- Sigue la construcción de prod. parc. hasta PP8 end process partial3; U1 : csa_tree port map (PP1,PP2,PP3,PP4,PP5,PP6,PP7,PP8,ssm,crr); END behave;
; END behave;.")
54
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Tabla 1. Estimación de área y retardo de los principales componentes. RESULTADOS

55
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Tabla 2. Aportación de cada vía al área total. RESULTADOS

56
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones RESULTADOS Camino crítico arquitectura argumento: RA1 Recodificación mux2 Inverter MAC_ mux10 reg_ : aprox. 29 ns ( 11.5 t fa ; 1 t fa = 2.56 ns). Camino crítico arquitectura módulo y argumento: RA1 Mod Tabla A i mux15 mux19 CSA_g mux17 reg_g: aprox. 32 ns ( 12.5 t fa ). Segundo escalado dividido en dos ciclos: caminos de 28 y 21 ns, respectivamente.
. Camino crítico arquitectura módulo y argumento: RA1 Mod Tabla A i mux15 mux19 CSA_g mux17 reg_g: aprox. 32 ns ( 12.5 t fa ). Segundo escalado dividido en dos ciclos: caminos de 28 y 21 ns, respectivamente..")
57
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones RESULTADOS Camino crítico arquitectura argumento: RA1 Recodificación mux2 Inverter MAC_ mux10 reg_ : aprox. 29 ns ( 11.5 t fa ; 1 t fa = 2.56 ns). Camino crítico arquitectura módulo y argumento: RA1 Mod Tabla A i mux15 mux19 CSA_g mux17 reg_g: aprox. 32 ns ( 12.5 t fa ). Segundo escalado dividido en dos ciclos: caminos de 28 y 21 ns, respectivamente.
. Camino crítico arquitectura módulo y argumento: RA1 Mod Tabla A i mux15 mux19 CSA_g mux17 reg_g: aprox. 32 ns ( 12.5 t fa ). Segundo escalado dividido en dos ciclos: caminos de 28 y 21 ns, respectivamente..")
58
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones RESULTADOS Camino crítico arquitectura argumento: RA1 Recodificación mux2 Inverter MAC_ mux10 reg_ : aprox. 29 ns ( 11.5 t fa ; 1 t fa = 2.56 ns). Camino crítico arquitectura módulo y argumento: RA1 Mod Tabla A i mux15 mux19 CSA_g mux17 reg_g: aprox. 32 ns ( 12.5 t fa ). Segundo escalado dividido en dos ciclos: caminos de 28 y 21 ns, respectivamente.
. Camino crítico arquitectura módulo y argumento: RA1 Mod Tabla A i mux15 mux19 CSA_g mux17 reg_g: aprox. 32 ns ( 12.5 t fa ). Segundo escalado dividido en dos ciclos: caminos de 28 y 21 ns, respectivamente..")
59
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones RESULTADOS Camino crítico arquitectura argumento: RA1 Recodificación mux2 Inverter MAC_ mux10 reg_ : aprox. 29 ns ( 11.5 t fa ; 1 t fa = 2.56 ns). Camino crítico arquitectura módulo y argumento: RA1 Mod Tabla A i mux15 mux19 CSA_g mux17 reg_g: aprox. 32 ns ( 12.5 t fa ). Segundo escalado dividido en dos ciclos: caminos de 28 y 21 ns, respectivamente.
. Camino crítico arquitectura módulo y argumento: RA1 Mod Tabla A i mux15 mux19 CSA_g mux17 reg_g: aprox. 32 ns ( 12.5 t fa ). Segundo escalado dividido en dos ciclos: caminos de 28 y 21 ns, respectivamente..")
60
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones RESULTADOS Camino crítico arquitectura argumento: RA1 Recodificación mux2 Inverter MAC_ mux10 reg_ : aprox. 29 ns ( 11.5 t fa ; 1 t fa = 2.56 ns). Camino crítico arquitectura módulo y argumento: RA1 Mod Tabla A i mux15 mux19 CSA_g mux17 reg_g: aprox. 32 ns ( 12.5 t fa ). Segundo escalado dividido en dos ciclos: caminos de 28 y 21 ns, respectivamente.
. Camino crítico arquitectura módulo y argumento: RA1 Mod Tabla A i mux15 mux19 CSA_g mux17 reg_g: aprox. 32 ns ( 12.5 t fa ). Segundo escalado dividido en dos ciclos: caminos de 28 y 21 ns, respectivamente..")
61
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones RESULTADOS Tabla 3(a). Comparativa con otras arquitecturas CORDIC. Cálculo del argumento
. Comparativa con otras arquitecturas CORDIC. Cálculo del argumento.")
62
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Tabla 3(b). Comparativa con otras arquitecturas CORDIC. Cálculo de módulo y argumento RESULTADOS
. Comparativa con otras arquitecturas CORDIC. Cálculo de módulo y argumento RESULTADOS.")
63
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Implementación VLSI de una arquitectura serie, en punto fijo, precisión de 32 bits, de CORDIC en modo vectorización y coordenadas circulares. Recurrencia con radix alto ( r 512) en las microrrotaciones, con aritmética redundante. Selección mediante redondeo de los coeficientes i y e j, y realización de dos escalados de la recurrencia para garantizar convergencia. CONCLUSIONES
 en las microrrotaciones, con aritmética redundante. Selección mediante redondeo de los coeficientes i y e j, y realización de dos escalados de la recurrencia para garantizar convergencia. CONCLUSIONES.")
64
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Implementación VLSI de una arquitectura serie, en punto fijo, precisión de 32 bits, de CORDIC en modo vectorización y coordenadas circulares. Recurrencia con radix alto ( r 512) en las microrrotaciones, con aritmética redundante. Selección mediante redondeo de los coeficientes i y e j, y realización de dos escalados de la recurrencia para garantizar convergencia. CONCLUSIONES
 en las microrrotaciones, con aritmética redundante. Selección mediante redondeo de los coeficientes i y e j, y realización de dos escalados de la recurrencia para garantizar convergencia. CONCLUSIONES.")
65
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Implementación VLSI de una arquitectura serie, en punto fijo, precisión de 32 bits, de CORDIC en modo vectorización y coordenadas circulares. Recurrencia con radix alto ( r 512) en las microrrotaciones, con aritmética redundante. Selección mediante redondeo de los coeficientes i y e j, y realización de dos escalados de la recurrencia para garantizar convergencia. CONCLUSIONES
 en las microrrotaciones, con aritmética redundante. Selección mediante redondeo de los coeficientes i y e j, y realización de dos escalados de la recurrencia para garantizar convergencia. CONCLUSIONES.")
66
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Implementación VLSI de una arquitectura serie, en punto fijo, precisión de 32 bits, de CORDIC en modo vectorización y coordenadas circulares. Recurrencia con radix alto ( r 512) en las microrrotaciones, con aritmética redundante. Selección mediante redondeo de los coeficientes i y e j, y realización de dos escalados de la recurrencia para garantizar convergencia. CONCLUSIONES
 en las microrrotaciones, con aritmética redundante. Selección mediante redondeo de los coeficientes i y e j, y realización de dos escalados de la recurrencia para garantizar convergencia. CONCLUSIONES.")
67
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Flujo de diseño basado en VHDL, con ayuda de herramientas CAD, y tecnología de diseño de 0.7 m. Aumento de velocidad entre un 50% y un 100% con respecto a arquitecturas CORDIC tradicionales. Primera implementación realizada del algoritmo CORDIC con radix alto. CONCLUSIONES

68
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Flujo de diseño basado en VHDL, con ayuda de herramientas CAD, y tecnología de diseño de 0.7 m. Aumento de velocidad entre un 50% y un 100% con respecto a arquitecturas CORDIC tradicionales. Primera implementación realizada del algoritmo CORDIC con radix alto. CONCLUSIONES

69
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Flujo de diseño basado en VHDL, con ayuda de herramientas CAD, y tecnología de diseño de 0.7 m. Aumento de velocidad entre un 50% y un 100% con respecto a arquitecturas CORDIC tradicionales. Primera implementación realizada del algoritmo CORDIC con radix alto. CONCLUSIONES

70
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Líneas de investigación abiertas: Implementación con un radix menor, para estudiar su impacto sobre área y velocidad. Implementación de la arquitectura segmentada. Extensión a modo rotación. Extensión a sistemas de coordenadas lineal e hiperbólico, e introducción del algoritmo recurrente de división. CONCLUSIONES

71
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Líneas de investigación abiertas: Implementación con un radix menor, para estudiar su impacto sobre área y velocidad. Implementación de la arquitectura segmentada. Extensión a modo rotación. Extensión a sistemas de coordenadas lineal e hiperbólico, e introducción del algoritmo recurrente de división. CONCLUSIONES

72
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Líneas de investigación abiertas: Implementación con un radix menor, para estudiar su impacto sobre área y velocidad. Implementación de la arquitectura segmentada. Extensión a modo rotación. Extensión a sistemas de coordenadas lineal e hiperbólico, e introducción del algoritmo recurrente de división. CONCLUSIONES

73
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Líneas de investigación abiertas: Implementación con un radix menor, para estudiar su impacto sobre área y velocidad. Implementación de la arquitectura segmentada. Extensión a modo rotación. Extensión a sistemas de coordenadas lineal e hiperbólico, e introducción del algoritmo recurrente de división. CONCLUSIONES

74
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Líneas de investigación abiertas: Implementación con un radix menor, para estudiar su impacto sobre área y velocidad. Implementación de la arquitectura segmentada. Extensión a modo rotación. Extensión a sistemas de coordenadas lineal e hiperbólico, e introducción del algoritmo recurrente de división. CONCLUSIONES

75
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones Líneas de investigación abiertas: Implementación con un radix menor, para estudiar su impacto sobre área y velocidad. Implementación de la arquitectura segmentada. Extensión a modo rotación. Extensión a sistemas de coordenadas lineal e hiperbólico, e introducción del algoritmo recurrente de división. CONCLUSIONES

76
1. Algoritmo 2. Arquitectura 3. Implementación 4. Conclusiones IMPLEMENTACIÓN VLSI DEL ALGORITMO CORDIC EN MODO VECTORIZACIÓN UTILIZANDO RADIX ALTO José Alejandro Piñeiro Riobó

Presentaciones similares










>")

>")





 de distintas formas – Signo magnitud.>")
