Descargar la presentación
La descarga está en progreso. Por favor, espere

1
TALLER REGIONAL SOBRE EL DISEÑO ESTADÍSTICO DE ENCUESTAS DE HOGARES PARA EL ESTUDIO DEL MERCADO LABORAL “Jackknife” Jaime Mojica Cuevas Agosto Panamá

2
6.1. INTRODUCCIÓN El Jackknife es una técnica de replicación de submuestras que ha sido sugerida como un método ampliamente útil para la estimación de la varianza. Como en el caso de los métodos previos, el Jackknife deriva estimaciones del parámetro de interés de cada una de las submuestras de la muestra fuente, y entonces estima la varianza del estimador de la muestra fuente a partir de la variabilidad entre las estimaciones de las submuestras.

3
6.1. INTRODUCCIÓN Quenouille (1949) introdujo originalmente el Jackknife como un método para reducir el sesgo del estimador de un coeficiente de correlación de una serie. Tukey (1958) sugirió que los estimadores individuales de las submuestras podrían considerarse razonablemente como variables aleatorias independientes e idénticamente distribuidas, lo que a su vez sugiere un estimador muy sencillo de la varianzas.
 introdujo originalmente el Jackknife como un método para reducir el sesgo del estimador de un coeficiente de correlación de una serie. Tukey (1958) sugirió que los estimadores individuales de las submuestras podrían considerarse razonablemente como variables aleatorias independientes e idénticamente distribuidas, lo que a su vez sugiere un estimador muy sencillo de la varianzas.")
4
6.2. SESGO DEL ESTIMADOR La propuesta de Quenouville es obtener a partir de la muestra de tamaño n, un estimador basado en n elementos junto con n estimadores basado ene (n-1) cada uno, denominados, por (6.2.1) El estimador del sesgo está dado por: (6.2.2) Deduce un estimador con corrección del sesgo: (6.2.3) este nuevo estimador tiene un sesgo de .
 cada uno, denominados, por. (6.2.1) El estimador del sesgo está dado por: (6.2.2) Deduce un estimador con corrección del sesgo: (6.2.3) este nuevo estimador tiene un sesgo de .")
5
Basado en este estimador Tuker (1958), sugirió calcular un n pseudovalores denominados que se consiguen después de dejar fuera el elemento i de la muestra, donde el nuevo estimador se describe como: (6.2.4) El estimador Jackknife está dado por: (6.2.5) La estimación de la varianza está dada por: (6.2.6)
 El estimador Jackknife está dado por: (6.2.5) La estimación de la varianza está dada por: (6.2.6)")
7
Los se les llama pseudovalores, el estimador de Jackknife de la varianza es:
(6.3.3) o (6.3.4)
 o. (6.3.4)")
8
6.3.1. Procedimiento para calcular la varianza Jackknife con grupos aleatorios
Calcular un estimador de basado en la muestra completa, empleando su diseño de muestreo. Formar los grupos aleatorios, utilizando el procedimiento de la sección 3. Calcular los omitiendo el grupo, así como hacer el ajuste a los factores de expansión de las UPM que no se omitieron, para que reflejen la ponderación de la muestra total. Calcular los pseudovalores para cada grupo de la siguiente forma:

9
Calcular el estimador Jackknife de los pseudovalores como:
Calcular la varianza por: ó

10
6.4. Jackknife para estimadores lineales
El Jackknife en estimadores lineales reproduce solamente los estimadores clásicos de la varianza, no se obtienen ganancias significativas al usar el Jackknife , pero a manera de ilustración se dan las expresiones del estimador de un total. Sea , y supongamos que la muestra fuente se divide en k grupos aleatorios de tamaño m, donde n=mk. Donde y su estimador de varianza es.

11
6.5. ESTIMADORES NO LINEALES
El interés principal del Jackknife es la estimación de la varianza para estadísticas no lineales, y este es el tema de la presente sección. De entrada se hace notar que están disponibles pocos resultados de distribución de muestra finita con relación al uso del Jackknife para estimadores no lineales. Para aplicar el Jackknife a estadísticas no lineales de una encuesta, se debe: Formar k grupos aleatorios y Seguir los principios del Jackknife enumerados en la sección

12
Entonces, como siempre el Jackknife opera omitiendo grupos aleatorios en la muestra. La versión Jackknife de un estimador no lineal de algún parámetro de la población es donde los pseudovalores se definen en (6.2) y es el estimado de la misma forma funcional que obteniendo después de omitir el -ésimo grupo aleatorio. Para estimadores lineales, se vio que el estimador es igual al estimador de la muestra fuente . Para los estimadores no lineales, sin embargo, generalmente se tiene .
 y es el estimado de la misma forma funcional que obteniendo después de omitir el -ésimo grupo aleatorio. Para estimadores lineales, se vio que el estimador es igual al estimador de la muestra fuente . Para los estimadores no lineales, sin embargo, generalmente se tiene .")
13
El estimador Jackknife de la varianza
Un estimador conservador de la varianza es Se puede usar o para estimar la varianza de

14
ESTIMADOR DE RAZÓN Supóngase que se desea estimar la razón entre dos totales poblacionales. El estimador usual es donde son estimadores de los totales poblacionales basados en el diseño de muestreo particular. El estimador del grupo aleatorio se obtiene trabajando con

15
donde son estimadores de Y y X después de omitir el -ésimo grupo aleatorio de la muestra. Entonces, se tienen los pseudovalores. (6.5.1.) y el estimador promedio se obtiene como: (6.5.2.) Para estimar la varianza de ó , se puede obtener por: (6.5.3.) O (6.5.4.)
 y el estimador promedio se obtiene como: (6.5.2.) Para estimar la varianza de ó , se puede obtener por: (6.5.3.) O. (6.5.4.)")
16
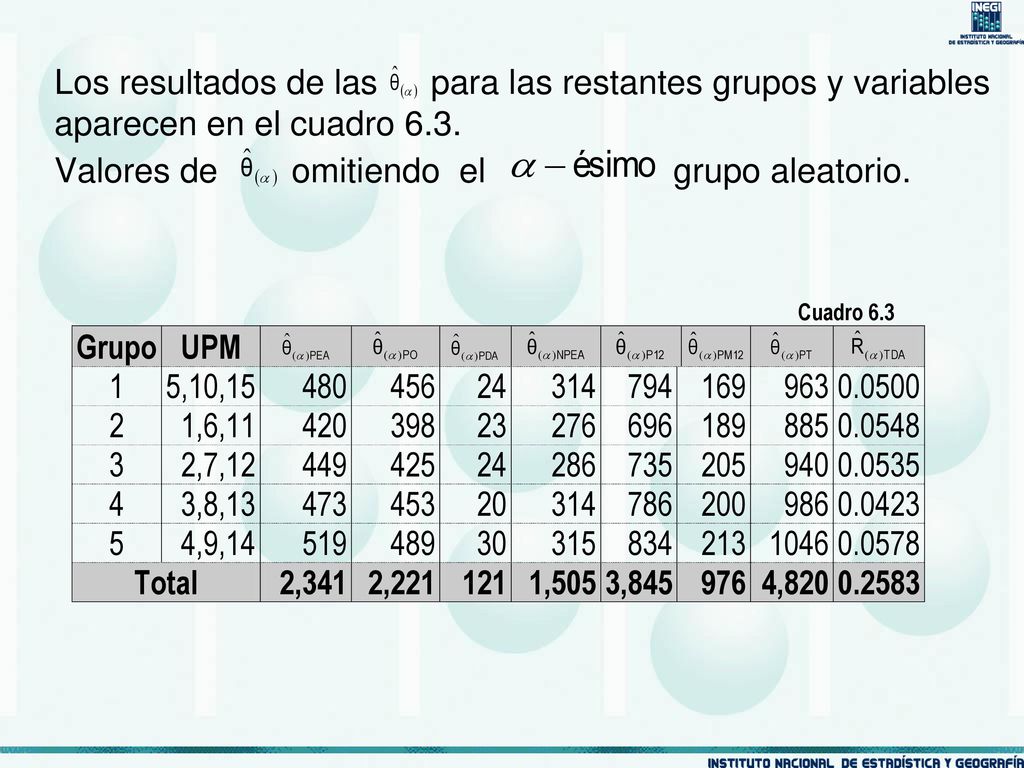
Ejemplo En éste ejemplo se trata de ilustrar cómo funciona el Jackknife aplicado sobre los grupos aleatorios. Para poder llevar a cabo a un buen término éste ejemplo hay que cumplir con el procedimiento La formación de los grupos aleatorios no fue necesario hacerla ya que tomamos los 5 grupos de la sección 3. La formación de los grupos aleatorios con su respectiva información se presenta en el cuadro 6.1. Solo que en esta formación los factores se presentan en su forma original aún no están ajustados.

17
Distribución de los grupos aleatorios con sus respectivas UPM
Cuadro 6.1 GRUPO ALEATORIO UPM Whi PEA PO PDA NPEA P12 PM12 PT 1 5 9 8 4 13 6 19 10 3 2 15 7 12 11 14 16 20 22

18
Calcular el de la muestra completa, para:

19
Suponga que en cada iteración se elimina el -ésimo grupo aleatorio y sean los factores de expansión originales, los cuales se ajustan como a continuación se indica: En el cuadro 6.2 se presentan los factores ajustados por (5/4) en cada pseudoreplica. Después de eliminar el - ésimo grupo aleatorio.
 en cada pseudoreplica. Después de eliminar el - ésimo grupo aleatorio.")
20
Distribución de las pseudoreplicas, con sus factores de expansión ajustados
Cuadro 6.2 Grupo aleatorio UPM whi Réplica1 Réplica2 Réplica3 Réplica4 Réplica5 1 5 6.25 10 9 11.25 15 6 7.50 2 8 10.00 11 3 7 12 4 13 5.00 14 Totales 87.50 85.00 92.50 91.25 93.75

23
En el cuadro 6.4. se presentan los pseudovalores para cada una de las variables y de la tasa de desempleo abierto. Pseudovalores de cada una de las variables de interés

24
Calcular los promedios de cada variable utilizando la siguiente expresión.
Calcular la varianza para: Estimadores lineales. La estimación de la varianza para un estimador del tipo lineal se puede hacer por medio de:

25
Varianza para la población total (PT).
.")
26
Estimadores no lineales.
Para la tasa de desempleo abierto (TDA) se emplean los estimadores de razón, para lo cual se utilizan los valores del cuadro 6.4.
 se emplean los estimadores de razón, para lo cual se utilizan los valores. del cuadro 6.4.")
27
Variable Estimación E.E. C.V. DEFF
En el cuadro 6.5 se presenta un resumen de las estimaciones por variable de interés con sus respectivas precisiones. Estimaciones por variable con sus precisiones Cuadro 6.5 Variable Estimación E.E. C.V. DEFF PEA 468 65.814 0.141 2.768 PO 444 61.632 0.139 2.551 PDA 24 6.595 0.275 0.347 NPEA 301 32.879 0.109 0.586 P12 769 96.130 0.125 2.069 PM12 195 30.455 0.156 0.634 PT 964 0.110 1.774 TDA 0.050 0.2136 0.2078

28
El estimador Jackknife de varianza para el problema de muestreo estratificado se define como
(6.6.1.) (6.6.2.)
 (6.6.2.)")
30
Ejemplo 6.2. En éste ejemplo se busca hacer una aplicación del Jackknife en el muestreo estratificado, utilizando la misma información de la encuesta de población de la sección 4 misma que aparece en el cuadro Se pretende estimar la varianza para totales y para la tasa de desempleo abierto, al igual que los ejemplos anteriores, el desarrollo del ejemplo se hace por pasos. Estimación de Totales. Estimar el de la muestra completa, para el caso de la población total (PT).
.")
31
Obtener los pseudovalores , eliminando la UPM i del estrato h
Obtener los pseudovalores , eliminando la UPM i del estrato h. En cada iteración los factores originales se ajustan como a continuación se indica. En el cuadro 6.6 aparecen las replicas formadas al eliminar una UPM a la vez, por estrato, los factores de expansión en el estrato 1 se ajustan por 8/7, los factores del estrato 2 se ajustan por 4/3 y los factores del estrato 3 se ajustan por 3/2.

32
Distribución de los factores ajustados, cuando se elimina la UPM i en el estrato h
Cuadro 6.6 Estrato UPM PEA PO PDA NPEA P12 PM12 PT R1 R2 R3 R4 R5 R6 R7 R8 1 5 6 2 8 0.000 9.143 3 9 12 5.714 7 15 4 11 13 19 10 20 22

33
Distribución de los factores ajustados, cuando se elimina la UPM i en el estrato h
PEA PO PDA NPEA P12 PM12 PT Réplica1 Réplica2 Réplica3 Réplica4 2 9 3 1 4 8 10 5 12 11 6 14 16 7 Estrato UPM PEA PO PDA NPEA P12 PM12 PT Réplica1 Réplica2 Réplica3 3 13 7 5 2 4 11 6 14 12 15 9

34
A partir de eliminar el i-ésimo conglomerado, se obtienen los
pero con los nuevos factores de expansión ajustados. En el caso de (PT) que corresponde al primer estrato obtendremos los dos primeros pseudovalores, para lo cual eliminamos la primer UPM y solo trabajaremos con 7 UPM. Los totales de las variables de la primer réplica se obtienen por: En la cuadro 6.7. se presentan los , por variable y estrato con sus respectivos totales.
 que corresponde al primer estrato obtendremos los dos primeros pseudovalores, para lo cual eliminamos la primer UPM y solo trabajaremos con 7 UPM. Los totales de las variables de la primer réplica se obtienen por: En la cuadro 6.7. se presentan los , por variable y estrato con sus respectivos totales.")
35
Pseudovalores por estrato y para cada una de las variables.

36
Pseudovalores por estrato y para cada una de las variables.

37
Promedios de los pseudovalores por estrato y variable
Obtener la media de los pseudovalores para cada uno de los estratos, por la siguiente expresión. , así para la (PT) del estrato 1 es: en la cuadro 6.8 aparecen los promedios para cada uno de los estratos y por variable de interés. Promedios de los pseudovalores por estrato y variable
 del estrato 1 es: en la cuadro 6.8 aparecen los promedios para cada uno de los estratos y por variable de interés. Promedios de los pseudovalores por estrato y variable.")
38
La estimación de la varianza se obtiene por medio de la expresión (6.5.4.).
, la varianza para PT es:

39
Varianzas estimadas por estrato, para cada variable de interés
En el cuadro 6.9 aparecen las varianzas por estrato y por variable de interés. Varianzas estimadas por estrato, para cada variable de interés Cuadro 6.9 Estrato Num. UPM'S PEA PO PDA NPEA P12 PM12 PT 1 8 1553.0 1318.7 42.9 1086.7 4203.4 1012.4 3609.0 2 4 225.0 105.0 36.0 1860.0 3129.0 240.0 3825.0 3 192.0 64.0 172.0 28.0 144.0 76.0 Total 1970.0 1487.7 142.9 3118.7 7360.4

40
Estimador de Razón En este punto se trata de obtener la estimación de la varianza para la tasa de desempleo abierto, para lo cual es importante desarrollar los siguientes puntos. Obtener los pseudovalores . Sea i la UPM que se elimina y h el estrato que la contiene. Para obtener los pseudovalores de una razón se emplea la siguiente expresión:

42
Obtendremos los primeros tres pseudovalores del primer estrato por medio de:
Los demás pseudovalores de se presentan en el cuadro 6.8.

43
Obtener los para cada uno de los estratos, por medio de la siguiente expresión:
Se calculo el para el primer estrato como en el cuadro 6.8., se presentan los para cada uno de los estratos.

44
Estimación de la varianza.
La estimación de la varianza para la TDA se obtiene por la expresión (6.5.8.).
.")
45
En el cuadro 6.11 se presentan los cálculos de la diferencia de los cuadrados y su varianza por estrato, en el cuadro 6.12 se presenta un resumen de las precisiones estadísticas. Pseudovalores , ordenados por estrato, con su respectivo , así como la diferencia de cuadrados y varianza por estratos

47
Estimaciones por variable con sus respectivas variables
Cuadro 6.12 Variable Estimación D.E. C.V. DEFF PEA 468 44.38 0.09 1.26 PO 444 38.57 0.08 1.00 PDA 24 11.95 0.49 1.14 NPEA 301 55.84 0.18 1.69 P12 769 85.79 0.11 1.65 PM12 195 37.36 0.19 0.95 PT 964 86.66 1.18 TDA 0.051 0.023 0.45 1.01

Presentaciones similares














 listas de datos ii) datos agrupados en una tabla de frecuencia iii) datos agrupados.>")





.>")



