Descargar la presentación
La descarga está en progreso. Por favor, espere

1
Modelos de regresión lineal
Econometría Modelos de regresión lineal Instructor: Favio Murillo García

2
Modelos de regresión lineal
Referencias: William Greene. Econometric Analysis. Ed. Pearson (capítulo 2) Jeffrey Wooldridge. Introductory Econometrics: A Modern Approach. Ed. Thomson Learning (pp 22-40) Damodar Gujarati. Econometrics. Ed. McGraw-Hill (pp 38-84) Econometría Modelos de regresión lineal
 Jeffrey Wooldridge. Introductory Econometrics: A Modern Approach. Ed. Thomson Learning (pp 22-40) Damodar Gujarati. Econometrics. Ed. McGraw-Hill (pp 38-84) Econometría. Modelos de regresión lineal.")
3
Modelos de regresión lineal
Objetivos de la sesión: Identificar un modelo de regresión lineal. Obtener los estimadores de un modelo de regresión lineal simple con excel y con eviews. Interpretar el signo de los coeficientes y el valor de la bondad de ajuste. Econometría Modelos de regresión lineal

4
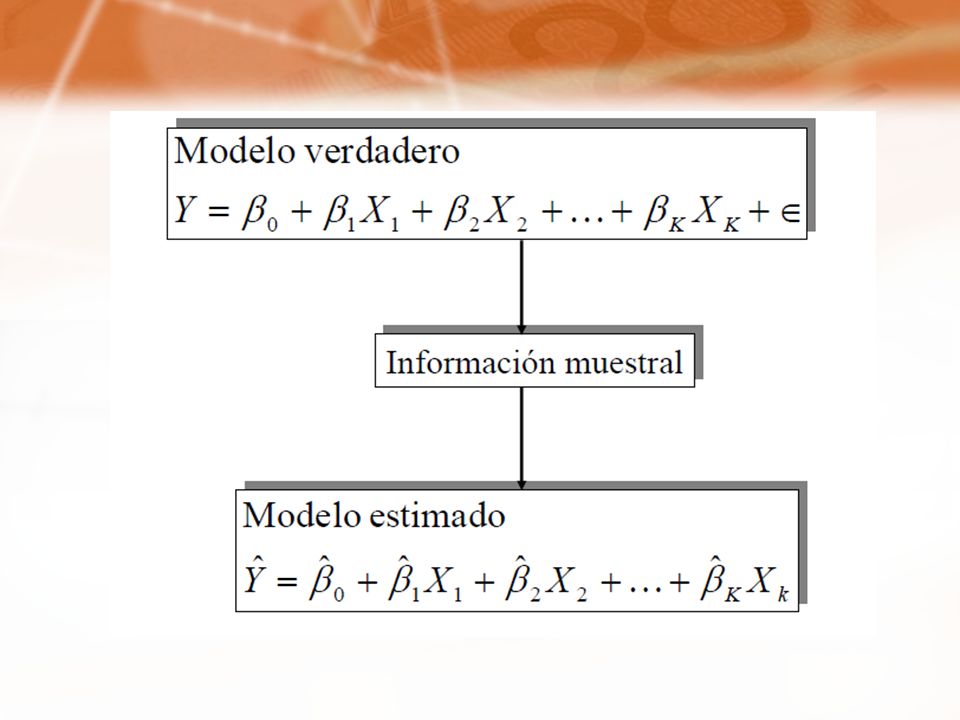
Introducción El papel esencial de la econometría es la estimación y verificación de los modelos econométricos. Proceso: Especificación del modelo en forma matemática. Reunión de datos apropiados y relevantes de la economía o sector que el modelo se propone describir. Con los datos se estima los parámetros del modelo Realizar pruebas con el modelo para analizar si es valido o si es necesario modificar la especificación.

5
Introducción Un modelo econométrico es una representación simplificada de la realidad, que recurre a un número limitado de conceptos formalizados.

6
Criticas Excesiva simplificación.
Supuestos poco realistas. Lo importante no es lo realista o no de los supuestos, sino qué tan buena es la explicación y capacidad de predicción que el modelo tiene en la realidad. Datos. Para funcionar, el modelo requiere datos, que a veces son escasos.

7
Análisis de regresión El objetivo del análisis de regresión es modelar, estadísticamente, la contribución o impacto que una o más variables explicativas pudieran tener sobre alguna variable de interés.

8
La realidad bajo estudio

10
Metodología de análisis
a) Identificar las variables que pudieran estar relacionadas con nuestra variable de interés. b) Proponer un modelo que capte la relación entre las variables. c) Estimar los parámetros del modelo propuesto en función de la información muestral disponible. d) Verificar la validez estadística del modelo construido y el cumplimiento de las propiedades de los errores. e) Verificar que no existan variables redundantes o no significativas en el modelo.
 Identificar las variables que pudieran estar relacionadas con nuestra variable de interés. b) Proponer un modelo que capte la relación entre las variables. c) Estimar los parámetros del modelo propuesto en función de la información muestral disponible. d) Verificar la validez estadística del modelo construido y el cumplimiento de las propiedades de los errores. e) Verificar que no existan variables redundantes o no significativas en el modelo.")
11
Algunas aplicaciones Costo de Capital (CAPM, APT).
Tipo de cambio, tasas de interés, inflación. Relación entre el IPC e índices de mercados financieros internacionales. Modelación del Spread en función volumen, tamaño de la empresa, sector industrial.

12
Algunas aplicaciones Interrelación entre variables económicas y financieras entre economías (Inflación en México vs. Inflación en Estados Unidos). Teoría de administración de portafolios (rendimiento esperado de un portafolio). Nivel de ventas, utilidades, etc.
. Nivel de ventas, utilidades, etc.")
13
Regresión Lineal Simple yi = b0 + b1xi + ui

14
y = b0 + b1x + u mientras que x es: donde y es: u es:
Variable independiente Variable explicativa Covariable Variable de control Regresor b0 y b1: parámetros o coeficientes a estimar donde y es: Variable dependiente Variable explicada Regresando u es: Residual Término de error

15
Algunos supuestos El valor promedio de u, el término de error, en la población es = 0. Es decir, E(u) = 0 Este supuesto no es muy restrictivo puesto que siempre podemos ajustar el intercepto b0 para normalizar E(u) = 0
 = 0.")
16
Media condicional = 0 Hay un supuesto crucial sobre la relación entre el error y la variable explicativa: cov(x, u) Queremos que la información contenida en x sea independiente de la información contenida en u (que no estén relacionados), de modo que: E(u|x) = E(u) = 0, lo cual implica: E(y|x) = b0 + b1x
 Queremos que la información contenida en x sea independiente de la información contenida en u (que no estén relacionados), de modo que: E(u|x) = E(u) = 0, lo cual implica: E(y|x) = b0 + b1x.")
17
Mínimos Cuadrados Ordinarios (MCO)
La idea básica es estimar parámetros poblacionales a partir de una muestra. Sea {(xi,yi): i =1, …,n} una muestra aleatoria de tamaño n de una población. Para cada observación en la muestra, tenemos: yi = b0 + b1xi + ui
: i =1, …,n} una muestra aleatoria de tamaño n de una población. Para cada observación en la muestra, tenemos: yi = b0 + b1xi + ui.")
18
. . . . Línea de regresión, observaciones y errores { y
E(y|x) = b0 + b1x . y4 u4 { . y3 u3 } . y2 u2 { u1 . y1 } x1 x2 x3 x4 x
 = b0 + b1x. . y4. u4. { . y3. u3. } . y2. u2. { u1. . y1. } x1. x2. x3. x4. x.")
19
Estimador MCO / OLS: intercepto (β0)
Tenemos:

20
Estimador MCO / OLS: pendiente (β1)
")
23
El estimador MCO de b1 b1, es la covarianza muestral entre x y y, dividida entre la varianza muestral de x. Si x y y están correlacionados positivamente, b1 será positivo (pues la varianza del denominador siempre es positiva). Si x y y están correlacionados negativamente, b1 será negativo. Obviamente, requerimos que x tenga cierta varianza en la muestra.
. Si x y y están correlacionados negativamente, b1 será negativo. Obviamente, requerimos que x tenga cierta varianza en la muestra.")
24
MCO / OLS Intuitivamente, MCO ajusta una línea a través de los datos muéstrales, de modo que la suma de residuales al cuadrado (SSR) sea la mínima posible: de ahí el término “mínimos cuadrados”. El residual, û, es un estimado del término de error entre lo observado y lo predicho, es decir, la diferencia entre la línea de regresión (fitted line) y el dato observado.
 sea la mínima posible: de ahí el término mínimos cuadrados . El residual, û, es un estimado del término de error entre lo observado y lo predicho, es decir, la diferencia entre la línea de regresión (fitted line) y el dato observado.")
25
Línea de regresión muestral, observaciones, y residuales estimados
. y4 { û4 . } û3 y3 . y2 û2 { } . û1 y1 x1 x2 x3 x4 x

26
Suma de cuadrados: Terminología

27
Bondad de ajuste: R2 ¿Cómo saber qué tan bueno es el ajuste entre la línea de regresión y los datos de la muestra? Podemos calcular la proporción de la suma de cuadrados totales (SST) que es “explicada” por el modelo. Esto es la llamada R-cuadrada de una regresión: R2 = SSE/SST = 1 – SSR/SST
 que es explicada por el modelo. Esto es la llamada R-cuadrada de una regresión: R2 = SSE/SST = 1 – SSR/SST.")
28
Ejercicio La siguiente tabla presenta datos que se refieren al consumo de tazas de café por día y el precio al menudeo del café. En Estados Unidos de 1970 a 1980. Fuentes: Summary of National Coffee Drinking Study, Nielsen Food Index, 1981.

29
Tasas diarias por persona (Y) Precio en dólares por libra (X)
Año Tasas diarias por persona (Y) Precio en dólares por libra (X) 1970 2.57 0.77 1971 2.5 0.74 1972 2.35 0.72 1973 2.3 0.73 1974 2.25 0.76 1975 2.2 0.75 1976 2.11 1.08 1977 1.94 1.81 1978 1.97 1.39 1979 2.06 1.2 1980 2.02 1.17
 Precio en dólares por libra (X)")
30
Conteste ¿ Cómo es la relación existente entre estas dos variables: directa o inversa ? ¿ Qué tan ajustada es la correlación entre estas dos variables ? Construya el siguiente modelo: Interprete intuitivamente el valor de los parámetros obtenidos Estime las tasas diarias por persona si el precio es de 1.5 dólares por libra.

31
Tarea Resolver el ejercicio 2.16 Revisar el ejemplo 7.2
(del texto de Gujarati)
")
32
Regresión Lineal Múltiple yi = b0 + b1x1i + b2x2i + . . . bkxki + ui

33
Cálculo de estimadores b = (Xt X)-1Xt Y
-1Xt Y")
34
Sesgo y eficiencia de MCO
Dos características deseables de cualquier estimador estadístico son: Insesgamiento (unbiasedness): que el parámetro estimado sea, en promedio, igual al “verdadero” parámetro poblacional. Eficiencia (efficiency): que la varianza del estimador sea mínima (ie, máxima precisión). Así, buscamos estimadores con sesgo mínimo y máxima eficiencia (ie, mínima varianza). MCO cuenta con ambas propiedades bajo ciertas condiciones: los supuestos Gauss-Markov.
: que el parámetro estimado sea, en promedio, igual al verdadero parámetro poblacional. Eficiencia (efficiency): que la varianza del estimador sea mínima (ie, máxima precisión). Así, buscamos estimadores con sesgo mínimo y máxima eficiencia (ie, mínima varianza). MCO cuenta con ambas propiedades bajo ciertas condiciones: los supuestos Gauss-Markov.")
35
Supuestos Gauss-Markov: Insesgamiento de MCO/OLS
El modelo poblacional es lineal en sus parámetros: y = b0 + b1x + u Muestra aleatoria de tamaño n, {(xi, yi): i=1, 2, …, n}, representativa de la población, de modo que el modelo muestral es: yi = b0 + b1xi + ui Media condicional cero: E(u|x) = 0 y por tanto E(ui|xi) = 0 Varianza(xi ) > 0
: i=1, 2, …, n}, representativa de la población, de modo que el modelo muestral es: yi = b0 + b1xi + ui. Media condicional cero: E(u|x) = 0 y por tanto E(ui|xi) = 0. Varianza(xi ) > 0.")
36
Demostración: SST = SSE + SSR

37
Supuestos Clásicos de los MICO
El modelo de regresión es lineal en los parámetros Los valores de X son fijos en muestreo repetido El valor medio de es igual a cero. Homocedasticidad o igual varianza de . No autocorrelación entre los . La covarianza entre y Xi es cero. El número de observaciones debe ser mayor que el de parámetros Variabilidad en los valores de X. El modelo de regresión está correctamente especificado No hay multicolinealidad perfecta

38
Supuestos Clásicos de los MICO
El modelo de regresión es lineal en los parámetros Los valores de X son fijos en muestreo repetido Supone que las variables X no son aleatorias Es posible mantener fijo el valor de X, y repetir el experimento, obteniendo en cada observación un valor de la variable distinto aleatoria Y. El análisis de regresión es un análisis de regresión condicional, es decir, condicionado a los valores dados de los regresores X.

39
Supuestos Clásicos de los MICO
3. El valor medio de es igual a cero. Los residuos no son más que las desviaciones de la muestra aleatoria con respecto a la FRP. Los factores que no están incluidos en el modelo, no afectan sistemáticamente el valor esperado de Y. Los valores positivos de se cancelan con los valores negativos, de tal manera que su efecto promedio sobre Y es cero.

40
Supuestos Clásicos de los MICO
4. Homocedasticidad o igual varianza de . La variación alrededor de la recta de regresión es la misma para los valores de X, es decir, las perturbaciones se distribuyen con igual dispersión respecto a la media. y dado el supuesto 2 es equivalente a

41
Homocedasticidad

42
Heterocestadisticidad

43
Supuestos Clásicos de los MICO
5. No autocorrelación entre los . No existe tendencia de que los errores asociados a una observación estén relacionados a los errores de otra. Si en un momento de tiempo o en un individuo de la muestra se genera un error positivo, esto no nos da información alguna sobre si el próximo error será positivo o negativo. Los errores no tienen un patrón de comportamiento sistemático. Si y están correlacionados, Yt no sólo depende de Xt, sino también de

44
Supuestos Clásicos de los MICO

45
Supuestos Clásicos de los MICO

46
Supuestos Clásicos de los MICO
6. La covarianza entre y Xi es cero. Si hay correlación, no es posible saber como afecta individualmente y a la variable Yi. Este supuesto se cumple inmediatamente si X no es una variable aleatoria (sino que es fija). 7. El número de observaciones debe ser mayor que el de parámetros
. 7. El número de observaciones debe ser mayor que el de parámetros.")
47
Supuestos Clásicos de los MICO
8. Variabilidad en los valores de X. El modelo de MCO requiere que exista una dispersión entre las X para poder calcular los valores de los coeficientes, pues si no, éstos serían una cantidad infinita. Ejemplo. Si todos los valores de X son idénticos, entonces Por lo cual Y entonces,

48
Supuestos Clásicos de los MICO
9. El modelo de regresión está correctamente especificado La forma de la FRM es igual a la FRP El modelo posee las variables correctas: no se incluyen variables irrelevante ni se excluyen relevantes. La forma funcional es la correcta 10. No hay multicolinealidad perfecta No hay una relación perfectamente lineal entre las X

Presentaciones similares






>")








 a partir de los valores de x (variable.>")




